
At the core of any modern programming language there lies a certain reference model, describing the data structures that applications will operate on. It defines how objects refer to each other, when an object can be deleted, and when and how an object can be modified.
Status quo
Most modern programming languages are built on one of three reference models:
The first category includes languages with manual memory management. Examples include C, C++, and Zig. In these languages, objects are manually allocated and deallocated, and pointers are simple memory addresses with no additional obligations.
The second category includes languages with reference counting. These languages include Objective-C, Swift, partially Rust, C++ when using smart pointers, and some others. These languages allow for some level of automation in removing unnecessary objects. However, this automation comes at a cost. In a multithreaded environment, reference counters must be atomic, which can be expensive. Additionally, reference counting cannot handle all types of garbage. When object A refers to object B, and object B refers back to object A, such a circular reference cannot be removed by reference counting. Languages like Rust and Swift introduce additional non-owning references to address the issue of circular references, but this affects the complexity of object model and syntax.
The third category encompasses most of the modern programming languages with automatic garbage collection, such as Java, JavaScript, Kotlin, Python, Lua, and more. In these languages, unnecessary objects are automatically removed, but there is a catch. The garbage collector consumes a significant amount of memory and processor time. It activates at random moments, causing the main program to pause. Sometimes this pause can be extensive, halting the program's execution entirely, while other times, it might be partial. There is no such thing as a garbage collector without pauses at all. And the only algorithm that scans the entire memory and halts the application for the entire duration of its operation can guarantee the collection of all garbage. In real-life scenarios, such garbage collectors are not used anymore due to their inefficiency. In modern systems, some garbage objects may not be removed at all.
Indeed, the definition of unnecessary objects requires clarification. In GUI applications, if you remove a control element from a form that is subscribed to a timer event, it cannot be simply deleted because there is a reference to this object somewhere in the timer manager. As a result, the garbage collector will not consider such an object as garbage.
As mentioned before, each of the three reference models has its drawbacks. In the first case, we face memory safety issues and memory leaks. In the second case, we encounter slow performance in a multithreaded environment and leaks due to circular references. In the third case, we experience sporadic program pauses, high memory and processor consumption, and the need for manual breaking of some references when an object is no longer needed. Additionally, reference counting and garbage collection systems do not allow for managing the lifetimes of other resources, such as open file descriptors, window identifiers, processes, fonts, and so on. These methods are designed solely for memory management.
In essence, problems exist, and each of the current solutions have their flaws.
Proposal
Let's try to build a reference model free from the aforementioned drawbacks. First, we need to gather requirements and examine how objects are actually used in programs, what programmers expect from object hierarchies, and how we can simplify and automate their work without sacrificing performance.
Our industry has accumulated rich experience in designing data models. It can be said that this experience is generalized in the Universal Modeling Language (UML). UML introduces three types of relationships between objects: association, composition, and aggregation.
- Association: This relationship occurs when one object knows about another, and can interact with it but without implying ownership.
- Composition: This relationship occurs when one object exclusively owns another object. For example, a wheel belongs to a car, and it can only exist in one car at a time.
- Aggregation: This relationship involves shared ownership. For instance, when many people share the name "Andrew."
Let's break this down with more concrete examples:
Database owns its tables, views, enumerations, and stored procedures. A table owns its records, column metadata, and indexes. A record owns its fields. In this case, all these relationships represent composition.
Another example is a user interface form owning its controls, and a UI list owning its elements. A document owns its style tables, which, in turn, own page elements, and text blocks own paragraphs, which then own characters. Again, these relationships represent composition.
Composition always forms a tree-like structure where each object has exactly one owner, and an object exists only as long as its owner references it. We always know when an object should be deleted, so we need no garbage collector nor reference counting for such references.
Examples of association:
- Paragraphs of some document reference styles in the document's style sheets.
- Records in one database table referencing records in another table (assuming we have an advanced relational database where such relationships are encoded using a special data type, rather than foreign keys).
- GUI form's control elements linked in a tab traversal chain.
- Controls on a form referencing data models, which in turn reference controls in some reactive application.
All these associations are maintained by non-owning pointers. They do not prevent object deletion, but they must handle the deletion to ensure memory safety. The language should detect attempts to access objects through such references without checking for object loss.
Aggregation is a bit tricky. The industry's best practices suggest that aggregation should generally be limited to immutable objects. Indeed, if an object has multiple owners from different hierarchies, modifying it can lead to bitter consequences in various unexpected parts of the program. There are even radical suggestions to completely exclude the use of aggregation, see Google's coding style guidelines. Though aggregation can be valuable and appropriate in certain scenarios, for instance, the flyweight design pattern relies on aggregation. Another example, in Java, strings are immutable, allowing multiple objects to reference the same string safely. Additionally, aggregates can be useful in a multithreaded environment where immutable objects can be safely shared between threads.
It is interesting that a hierarchy of immutable objects linked by aggregating references cannot contain cycles. Each immutable object starts its life as mutable since it needs to be filled with data before being "frozen" and made immutable. As we have already seen, immutable objects cannot have cycles. Therefore, cycles in properly organized object hierarchies can only occur through non-owning associative references. While owning composition references always form a tree, and aggregating references form a directed acyclic graph (DAG). None of these structures require a garbage collector BTW.
Side Note: In other words, the main problem with existing reference models is that they allow the creation of data structures that contradict best practices of our industry and, as a consequence, lead to numerous issues with memory safety and memory leaks. Languages that use these models then struggle heroically with the consequences of their architecture without addressing the root causes.
If we design a programming language that:
- Declaratively supports UML references,
- Automatically generates all operations on objects (copying, destruction, passing between threads, etc.) based on these declarations,
- Enforces the rules of using these references at compile time (one owner, immutability, checking for object loss, etc.),
...then such a language will provide both memory safety and absence of memory leaks, eliminate garbage collector overheads, and significantly simplify the programmer's life. As objects will be deleted at predictable times, this will allow attaching resource management to the objects lifetimes.
Implementation
In the experimental programming language Argentum (https://aglang.org), the idea of UML references is implemented as follows:
- A class field marked with
"&"represents a non-owning reference (association). - A field marked with
"*"represents a shared reference to an immutable object (aggregation). - All other reference fields represent composition (such a field is the sole owner of a mutable object).
Example:
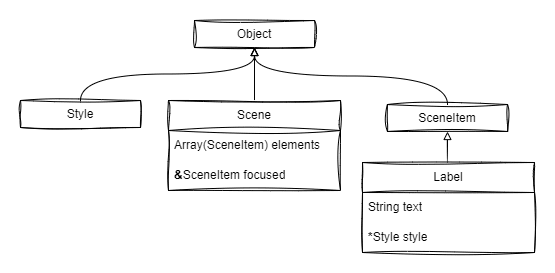
class Scene {
// The `elements` field holds the `Array` object, that holds
// a number of SceneItems. It's composition
elements = Array(SceneItem);
// The 'focused' field references some `SceneItem`. No ownership
// It's association
focused = &SceneItem;
}
interface SceneItem { ... }
class Style { ... }
class Label { +SceneItem; // Inheritance
text = ""; // Composition: the string belongs to label
// The `style` field references an immutable instance of `Style`
// Its immutability allows to share it among multiple parents
// It's aggregation
style = *Style;
}
The resulting class hierarchy:
Example (continued) object creation:
// Make a `Scene` instance and store it in a variable.
// `root` is a composite reference (with single ownership)
root = Scene;
// Make a `Style` instance; fill it using a number of initialization methods;
// freeze it, making it immutable with the help of *-operator.
// and store it in a `normal` variable that is an aggregation reference
// (So this `Style` instance is shareable)
normal = *Style.font(times).size(40).weight(600);
// Make a Label instance, initialize its fields and store it in a `scene.elements` collection
root.elements.add(
Label.at(10, 20).setText("Hello").setStyle(normal));
// Make a non-owning association link from `scene` to `Label`
root.focused := &root.elements[0];
Resulting objects and interconnection hierarchy:
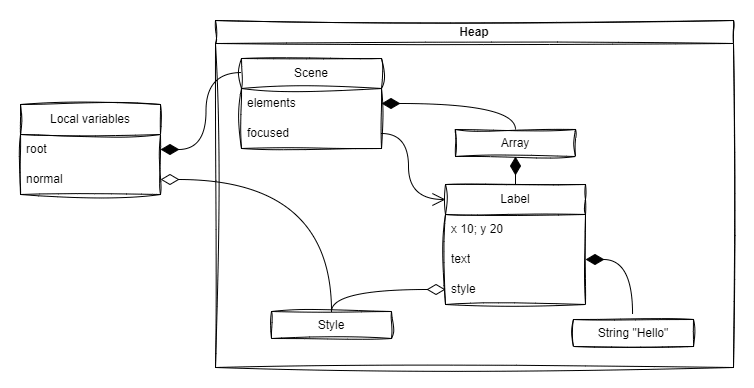
The constructed data structure provides several important integrity guarantees:
root.elements.add(root.elements[0]);
// Compilation error: the object Label can have only one owner.
normal.weight := 800;
// Compilation error: `normal` is an immutable object.
root.focused.hide();
// Compilation error: there is no check-for and handling-of a lost `focused` reference.
But Argentum not only watches over the programmer (and slaps their wrists), it also helps.
Let's try to fix the above compilation errors:
// @-operator makes deep copies.
// Here we add a copy of the label to the scene.
// This copy references the copy of the text, but shares the same Style instance.
root.elements.add(@root.elements[0]);
// Make a mutable copy of the Style instance,
// modify its `weight`,
// freese this copy (make it immutable-shareable)
// and store it back to the variable `normal`.
normal := *(@normal).weight(800);
// Check if associative link pointes to the object and protect if from being deleted
// if it is not empty, call its method.
// after that remove the protection.
root.focused ? _.hide(); // if root.focused exists, hide _it_
All operations for copying, freezing, thawing, deletion, passing between threads, etc., are performed automatically. The compiler constructs these operations using objects fields' association-composition-aggregation declarations.
For example the following construction:
newScene := @root;
...makes the full deep copy of Scene with correct topology of internal interconnections:

Automatically generated copy of the scene subtree with the preservation of the topology of internal references.
This operation follows well defined rules:
- All sub-objects by composition references, that should have a single owner, are copied cascading.
- Objects that are marked as shared with aggregation references (e.g., Style) are not copied, but shared.
- In the copied scene, the 'focused' field correctly references the copy of the label, because copy operation distinguishes internal and external references:
- All references to the objects that are not affected by this copy operation, point to the original.
- All internal references point to the copied instance preserving the topology of the original data structure.
Why Argentum automates operations:
- It ensures memory safety
- It ensures absence of memory leaks (making the garbage collector unnecessary).
- It guarantees timely object deletion, enabling automatic management of resources other than RAM through RAII, like automatically closing files, sockets, handles, etc.
- It ensures the absence of corruptions in the logical structure of the object model.
- It relieves the programmer from the routine manual implementation of these operations.
- It makes the data structures and code virtual-memory-friendly. Because garbage doesn't pile up and is never evicted from RAM but instead disposed of in a timely manner.
Interim Results
The Argentum language is built on a new, but already familiar UML reference model that is free from the limitations and drawbacks of garbage-collected, reference-counted, and manually memory-managed systems. As of today, the language includes: parameterized classes and interfaces, multithreading, control structures based on optional data types, fast type casts, very fast interface method calls, modularity and FFI. It ensures memory safety, type safety, absence of memory leaks, races, and deadlocks. It utilizes LLVM for code generation and produces stand-alone executable applications.
Argentum is an experimental language. Much remains to be done: numerous code generation optimizations, bug fixes, test coverage, stack unwinding, improved debugger support, syntactic sugar, etc., but it is rapidly evolving, and the listed improvements are in the near future.
- The project's homepage: https://aglang.org.
- The Windows demo can be found here github.com/karol11/argentum/releases:
In the next article I'm going to cover the semantics of operations on association-composition-aggregation (ACA-pointers) and their implementation in Argentum.
Any questions and suggestions are warmly welcomed.





Top comments (0)