
Intro
This is a part of the series of blog posts related to Artificial Intelligence Implementation. If you are interested in the background of the story or how it goes:
#1) How to scrape Google Local Results with Artificial Intelligence?
#2) Real World Example of Machine Learning on Rails
#3) AI Training Tips and Comparisons
#4) Machine Learning in Scraping with Rails
#5) Implementing ONNX models in Rails
#6) How ML Hybrid Parser Beats Traditional Parser
#7) How to Benchmark ML Implementations on Rails
#8) Investigating Machine Learning Techniques to Improve Spec Tests
#9) Investigating Machine Learning Techniques to Improve Spec Tests — II
This week we’ll showcase the database creation process for implementing Machine Learning models for general testing purposes. We will be using SerpApi’s Google Organic Results Scraper API for the data collection. Also, here is a link containing the detailed view on the data we will use.

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
I — Creating a Linerized CSV out of a Hash
Let’s initalize class variable @@pattern_data and define @@vocab inside Database class. The default for vocabulary we will use to vectorize words and sentences should be { "" => 0, " " => 1 }.
class Database
def initialize json_data, vocab = { "<unk>" => 0, " " => 1 }
super()
@@pattern_data = []
@@vocab = vocab
end
Next, we need a recursive way to translate hashes into lines of understandable bits consisting of the value, and its key type.
For instance we need to translate this:
{
"position": 1,
"title": "Coffee - Wikipedia",
"link": "https://en.wikipedia.org/wiki/Coffee",
"displayed_link": "https://en.wikipedia.org › wiki › Coffee",
"thumbnail": "https://serpapi.com/searches/62436d12e7d08a5a74994e0f/images/ed8bda76b255c4dc4634911fb134de5319e08af7e374d3ea998b50f738d9f3d2.jpeg",
"snippet": "Coffee is a brewed drink prepared from roasted coffee beans, the seeds of berries from certain flowering plants in the Coffea genus. From the coffee fruit, ...",
...
}
to this:
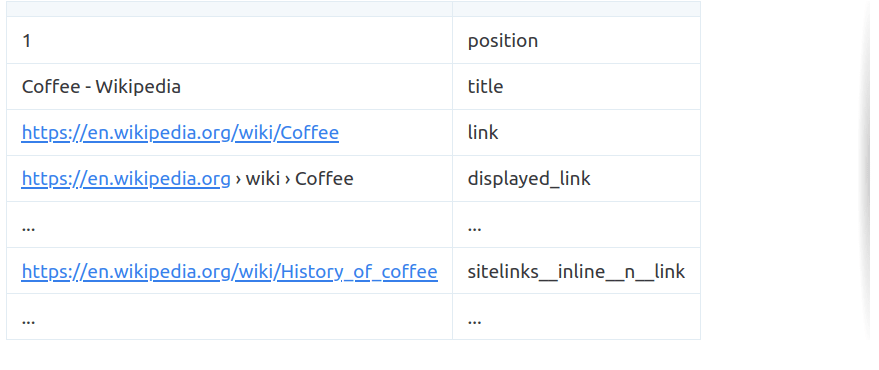
Notice that position doesn’t matter for some elements. So we call them with n, and inner keys are separated by __.
Now let’s define the main function that’ll fill @@pattern_data (master_array), and write it to a CSV file for future use.
def self.add_new_data_to_database json_data, csv_path = nil
json_data.each do |result|
recursive_hash_pattern result, ""
end
@@pattern_data = @@pattern_data.reject { |pattern| pattern.include? nil }.uniq.compact
path = "#{csv_path}master_database.csv"
File.write(path, @@pattern_data.map(&:to_csv).join)
end
Let’s break down recursive_hash_pattern and its relevant functions:
## For keys that directly contain String, Integer, Float etc.
def self.element_pattern result, pattern
@@pattern_data.append([result, pattern].flatten)
end
## For Arrays that contain String, Integer, Float etc.
def self.element_array_pattern result, pattern
result.each do |element|
element_pattern element, pattern
end
end
## Main Process
def self.assign hash, key, pattern
## If the key contains a hash, it has to be recursed until all
## child components are collected.
if hash[key].is_a?(Hash)
if pattern.present?
pattern = "#{pattern}__#{key}"
else
pattern = "#{key}"
end
recursive_hash_pattern hash[key], pattern
## If the key contains an array, containing multiple hashes, ## all the hashes should be recursed to their components
elsif hash[key].present? && hash[key].is_a?(Array) && hash[key].first.is_a?(Hash)
if pattern.present?
pattern = "#{pattern}__#{key}__n"
else
pattern = "#{key}"
end
hash[key].each do |hash_inside_array|
recursive_hash_pattern hash_inside_array, pattern
end
## If the key contains an array consisting of base elements,
## each element should be added with the right key pattern.
elsif hash[key].present? && hash[key].is_a?(Array)
if pattern.present?
pattern = "#{pattern}__n"
else
pattern = "#{key}"
end
element_array_pattern hash[key], pattern
## If the element contains String, Float, etc.
else
if pattern.present?
pattern = "#{pattern}__#{key}"
else
pattern = "#{key}"
end
element_pattern hash[key], pattern
end
end
def self.recursive_hash_pattern hash, pattern
hash.keys.each do |key|
assign hash, key, pattern
end
end
Notice that each recursive action carries its pattern to next iteration to make the key classifying distinct.
Now, if we apply these commands, it’ll create a csv file called master.csv inside organic_results folder.
json_data represents the organic_results array containing every organic_result hash we have.
Database.new json_data Database.add_new_data_to_database json_data, csv_path = "organic_results/"
End result is as desired:
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
II — Tokenizing, and Vocabulary Creation
Before we dive into creating hash specific tables to be tokenized with ngram iterator, let's define functions responsible for tokenizing:
def self.default_dictionary_hash
{
/\"/ => "",
/\'/ => " \' ",
/\./ => " . ",
/,/ => ", ",
/\!/ => " ! ",
/\?/ => " ? ",
/\;/ => " ",
/\:/ => " ",
/\(/ => " ( ",
/\)/ => " ) ",
/\// => " / ",
/\s+/ => " ",
/<br \/>/ => " , ",
/http/ => "http",
/https/ => " https ",
}
end
This function is responsible for creating a default dictionary hash for splitting words fed in the tokenizer, and what they will be replaced with. We will be able to create understandable bits of vectors from these split points. Notice that I have included http and https in them since it is widely used in organic_results.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
def self.tokenizer word, dictionary_hash = default_dictionary_hash word = word.downcase dictionary_hash.keys.each do |key| word.sub!(key, dictionary_hash[key]) end word.split end
This is our main tokenizer. To give an example, if we apply such command:
Database.tokenizer "SerpApi, to. the: Moon"
We get such output:
["serpapi,", "to", ".", "the", "moon"]
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
def self.iterate_ngrams token_list, ngrams = 1
token_list.each do |token|
1.upto(ngrams) do |n|
permutations = (token_list.size - n + 1).times.map { |i| token_list[i...(i + n)] }
permutations.each do |perm|
key = perm.join(" ")
unless @@vocab.keys.include? key
@@vocab[key] = @@vocab.size
end
end
end
end
end
This is our ngram iterator. token_list in here is the output of the tokenizer function. With this function, we create permutaitons out of different cut points. ngrams define how wide the permutations should be.
To give an example, if we apply such command:
Database.iterate_ngrams ["serpapi,", "to", ".", "the", "moon"], ngrams=3
Our vocabulary (@@vocab) will be updated as such:
{
"<unk>"=>0,
" "=>1,
"serpapi,"=>2,
"to"=>3,
"."=>4,
"the"=>5,
"moon"=>6,
"serpapi, to"=>7,
"to ."=>8,
". the"=>9,
"the moon"=>10,
"serpapi, to ."=>11,
"to . the"=>12,
". the moon"=>13
}
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
We will be covering how to use vectors in classifying in next week’s blog post. But to give an idea about what it will look like, the function responsible is:
def self.word_to_tensor word
token_list = tokenizer word
token_list.map {|token| @@vocab[token]}
end
So, if we feed our sentence:
Database.word_to_tensor "SerpApi, to. the: Moon"
We get the corresponding tokens:
[2, 3, 4, 5, 6]
This way we can express strings in a mathematical way.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
III — Key Specific CSV Creation
Let’s define functions that’ll help in the creation of key specific databases, and for their later uses.
First, we need to define a function to save the end result of our vocabulary that will be created by each word fed to key specific databases:
def self.save_vocab vocab_path = ""
path = "#{vocab_path}vocab.json"
vocab = JSON.parse(@@vocab.to_json)
File.write(path, JSON.pretty_generate(vocab))
end
The end result of this will be:
{
"<unk>": 0,
" ": 1,
"1": 2,
"coffee": 3,
"-": 4,
"wikipedia": 5,
"coffee -": 6,
...
}
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Just to check if a string consists of only numeric values:
def self.is_numeric?
return true if self =~ /\A\d+\Z/
true if Float(self) rescue false
end
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
To create example key-value pairs for each key type:
def self.create_keys_and_examples
keys = @@pattern_data.map { |pattern| pattern.second }.uniq
examples = {}
keys.each do |key|
examples[key] = @@pattern_data.find { |pattern| pattern.first.to_s if pattern.second == key }
end
[keys, examples]
end
The end result will be a collection of unique keys and a hash containing one example to eliminate errors with conditions.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
def self.create_key_specific_databases result_type = "organic_results", csv_path = nil, dictionary = nil, ngrams = nil, vocab_path = nil
keys, examples = create_keys_and_examples
keys.each do |key|
specific_pattern_data = []
@@pattern_data.each_with_index do |pattern, index|
word = pattern.first.to_s
next if word.blank?
if dictionary.present?
token_list = tokenizer word, dictionary
else
token_list = tokenizer word
end
if ngrams.present?
iterate_ngrams token_list, ngrams
else
iterate_ngrams token_list
end
if key == pattern.second
specific_pattern_data << [ 1, word ]
elsif (examples[key].to_s.to_i == examples[key]) && word.to_i == word
next
elsif (examples[key].to_s.to_i == examples[key]) && word.numeric?
specific_pattern_data << [ 0, word ]
elsif examples[key].numeric? && word.numeric?
next
elsif key.split("__").last == pattern.second.to_s.split("__").last
specific_pattern_data << [ 1, word ]
else
specific_pattern_data << [ 0, word ]
end
end
path = "#{csv_path}#{result_type}__#{key}.csv"
File.write(path, specific_pattern_data.map(&:to_csv).join)
end
if vocab_path.present?
save_vocab vocab_path
else
save_vocab
end
end
This is the main function responsible for creating a database for each key. Notice that keys that are integers within the table are omitted for csv for a key that contains an integer. This way we can eliminate confusion in cases such as rating:"5" which could be confused with reviews:"5". We also generalize the cases where the last inner keys are the same to avoid the confusion on same kind of elements. Example would be position in the main hash and in one of its keys. They represent the same key, so marking them with 1 could come in handy. We also add each word to our vocabulary to expand it, later to be saved to csv.
The end result for one of the CSV files created( organic_results__about_page_link):

1 represents that this is the kind of result we want for such a key, and 0 represents the opposite.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
IV — Entire Code
Here’s a mindmap of the entire process:

Here’s the full code for the class below:
class Database
def initialize json_data, vocab = { "<unk>" => 0, " " => 1 }
super()
@@pattern_data = []
@@vocab = vocab
end
## Related to creating main database
def self.add_new_data_to_database json_data, csv_path = nil
json_data.each do |result|
recursive_hash_pattern result, ""
end
@@pattern_data = @@pattern_data.reject { |pattern| pattern.include? nil }.uniq.compact
path = "#{csv_path}master_database.csv"
File.write(path, @@pattern_data.map(&:to_csv).join)
end
def self.element_pattern result, pattern
@@pattern_data.append([result, pattern].flatten)
end
def self.element_array_pattern result, pattern
result.each do |element|
element_pattern element, pattern
end
end
def self.assign hash, key, pattern
if hash[key].is_a?(Hash)
if pattern.present?
pattern = "#{pattern}__#{key}"
else
pattern = "#{key}"
end
recursive_hash_pattern hash[key], pattern
elsif hash[key].present? && hash[key].is_a?(Array) && hash[key].first.is_a?(Hash)
if pattern.present?
pattern = "#{pattern}__#{key}__n"
else
pattern = "#{key}"
end
hash[key].each do |hash_inside_array|
recursive_hash_pattern hash_inside_array, pattern
end
elsif hash[key].present? && hash[key].is_a?(Array)
if pattern.present?
pattern = "#{pattern}__n"
else
pattern = "#{key}"
end
element_array_pattern hash[key], pattern
else
if pattern.present?
pattern = "#{pattern}__#{key}"
else
pattern = "#{key}"
end
element_pattern hash[key], pattern
end
end
def self.recursive_hash_pattern hash, pattern
hash.keys.each do |key|
assign hash, key, pattern
end
end
## Related to tokenizing
def self.default_dictionary_hash
{
/\"/ => "",
/\'/ => " \' ",
/\./ => " . ",
/,/ => ", ",
/\!/ => " ! ",
/\?/ => " ? ",
/\;/ => " ",
/\:/ => " ",
/\(/ => " ( ",
/\)/ => " ) ",
/\// => " / ",
/\s+/ => " ",
/<br \/>/ => " , ",
/http/ => "http",
/https/ => " https ",
}
end
def self.tokenizer word, dictionary_hash = default_dictionary_hash
word = word.downcase
dictionary_hash.keys.each do |key|
word.sub!(key, dictionary_hash[key])
end
word.split
end
def self.iterate_ngrams token_list, ngrams = 1
token_list.each do |token|
1.upto(ngrams) do |n|
permutations = (token_list.size - n + 1).times.map { |i| token_list[i...(i + n)] }
permutations.each do |perm|
key = perm.join(" ")
unless @@vocab.keys.include? key
@@vocab[key] = @@vocab.size
end
end
end
end
end
def self.word_to_tensor word
token_list = tokenizer word
token_list.map {|token| @@vocab[token]}
end
## Related to creating key-specific databases
def self.create_key_specific_databases result_type = "organic_results", csv_path = nil, dictionary = nil, ngrams = nil, vocab_path = nil
keys, examples = create_keys_and_examples
keys.each do |key|
specific_pattern_data = []
@@pattern_data.each_with_index do |pattern, index|
word = pattern.first.to_s
next if word.blank?
if dictionary.present?
token_list = tokenizer word, dictionary
else
token_list = tokenizer word
end
if ngrams.present?
iterate_ngrams token_list, ngrams
else
iterate_ngrams token_list
end
if key == pattern.second
specific_pattern_data << [ 1, word ]
elsif (examples[key].to_s.to_i == examples[key]) && word.to_i == word
next
elsif (examples[key].to_s.to_i == examples[key]) && word.numeric?
specific_pattern_data << [ 0, word ]
elsif examples[key].numeric? && word.numeric?
next
elsif key.split("__").last == pattern.second.to_s.split("__").last
specific_pattern_data << [ 1, word ]
else
specific_pattern_data << [ 0, word ]
end
end
path = "#{csv_path}#{result_type}__#{key}.csv"
File.write(path, specific_pattern_data.map(&:to_csv).join)
end
if vocab_path.present?
save_vocab vocab_path
else
save_vocab
end
end
def self.create_keys_and_examples
keys = @@pattern_data.map { |pattern| pattern.second }.uniq
examples = {}
keys.each do |key|
examples[key] = @@pattern_data.find { |pattern| pattern.first.to_s if pattern.second == key }
end
[keys, examples]
end
def self.is_numeric?
return true if self =~ /\A\d+\Z/
true if Float(self) rescue false
end
def self.save_vocab vocab_path = ""
path = "#{vocab_path}vocab.json"
vocab = JSON.parse(@@vocab.to_json)
File.write(path, JSON.pretty_generate(vocab))
end
end
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
V — Conclusion
Next week we’ll utilize these csv files to vectorize them using tokenizer, and create key-specific models for each key. The end aim of this project is to create an open-source gem to be implemented by everyone using a JSON Data Structure in their code. I'd like to thank the reader for their attention, and the brilliant people of SerpApi creating wonders even in times of hardship for all their support.
Originally published at https://serpapi.com on March 30, 2022.





Top comments (0)