
If you do not know, HTTP was around us for a bit of time and even older than you think. It is a core of the World Wide Web that allows web applications to communicate with the servers to render data into our view.
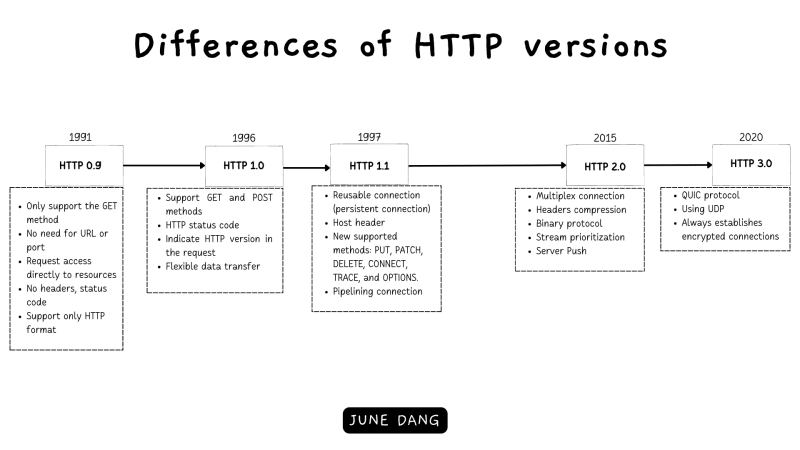
As modern technologies and the Internet continuously emerge and so HTTP has evolved time over time to meet the need of the Internet infrastructure and now encompasses five versions that have been introduced since its inception: 0.9, 1.0, 1.1, and 2.0, with a future version, 3.0, on the horizon.
In today’s article, let us explore the changes in each HTTP version and how each version solves its previous problems.
If you are looking for a deep-dive explanation of how HTTP works, feel free to visit here. No more talking, let us drive into exploring the versions of HTTP.
The Invention of The World Wide Web and The Hyper Text Transfer Protocol
HTTP (Hypertext Transfer Protocol) is a network protocol invented by Tim Berners-Lee between 1989 and 1991. (Note: Tim Berners-Lee is also the founder of the World Wide Web.) It operates on the client-server model, where clients send requests and servers respond with data for browsers to render into the user’s screen.
While we often celebrate the creation of the Internet and the World Wide Web, it is important not to overlook the silent hero that enables communication between websites: HTTP.
HTTP/0.9
The first version of HTTP was released in 1991 and with extremely limited features when compared to its descendants. The first version does not even have a name and later was called HTTP/0.9. Here are some basic features that were introduced with HTTP/0.9:
- The one-line portal: The request is a simple line that calls directly to the resource. For example:
/mypage.html - The first version only supported a single HTTP method:
GET - Neither HTTP error code nor HTTP headers at that time. If there is a problem happen during the connection, a simple HTTP page will display for human understanding.
- Because of no HTTP headers, the first version only supports pure HTML file content.
A request/response these days was something like this:
GET /index.html HTTP/0.9
<HTML>
This is the content of the index.html document.
</HTML>
HTTP/1.0
As the need for the Internet moved from statistic/documentary websites to dynamic/content-based websites, HTTP evolved to fit that requirement and HTTP/1.0 was introduced in 1996 with many advancements from the previous one:
- Headers: The golden feature that opens many opportunities for web development that supports a range of features like variation of file transfer with Content-Type, caching, and authentication.
- Flexible data transfer: Clients and servers were now allowed to transfer multiple types of data through the Content-Type header: media, scripts, stylesheets, etc…
- HTTP status code: Supported HTTP status code to check whether the request success or failed.
- Versioning: Indicate the version of HTTP in the request (HTTP/1.0 was appended to the GET line).
- POST method: Besides the GET method, an HTTP POST request was introduced enabling more complex interactions between clients and servers.
A common HTTP/1.0 request/response now looks more like the HTTP we see this day:
GET /image.jpg HTTP/1.0
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
HTTP/1.0 200 OK
Date: Mon, 18 July 2023 12:00:00 GMT
Server: Apache/2.4.6 (Ubuntu)
Content-Type: image/jpeg
Content-Length: 5000
<Binary data representing the image>
A major problem with HTTP/0.9 and HTTP/1.0
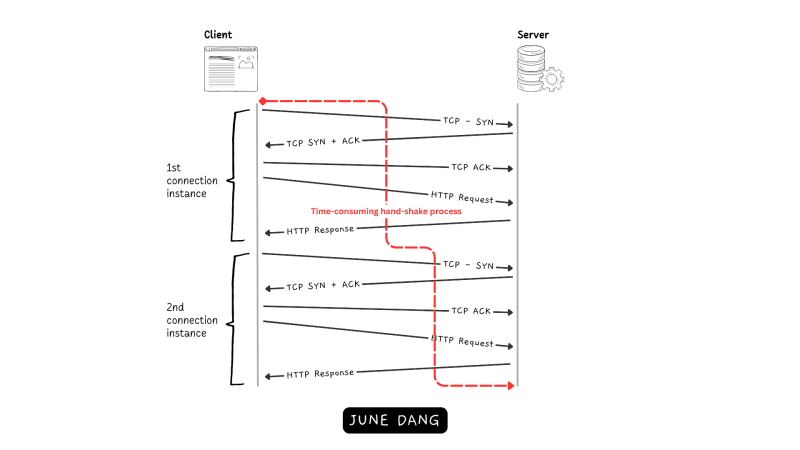
If you have read my previous article about how HTTP works, you know that establishing the connection between the client and the server requires the use of TCP protocol which employs a three-way handshake to establish a communication channel. Although this approach at first improves the reliability between clients and servers, it can lead to performance issues as every HTTP request triggers a TCP three-way handshake which is a time-consuming task. To optimize the performance, there needs to be a solution to reduce the number of TCP connections between clients and servers as fewer connections are created which means less wait time for the clients. This issue was addressed in the introduction of HTTP/1.1.
HTTP 1.1
HTTP/1.1 has been in the development process which is parallel with the release of HTTP/1.0 a goal that aims for standardized the HTTP protocol. And one year after the release of HTTP/1.0, HTTP/1.1 was introduced which improves server functions from its father while clarifying the ambiguities.
- Reused connection: The connection now can be reused to execute several requests within a single TCP connection. This dramatically improves the performance of the new HTTP when eliminating the need to establish a new TCP connection for each request.
- Host Header: HTTP/1.1 is required to include the Host header in the request which allows servers to handle multiple domain names using the same IP address enabling better server resource utilization and facilitating the hosting of multiple websites on a single server.
- Pipelining: One of the new features of HTTP/1.1 was that it allows a second request to be sent while waiting for a response from the first one. This helps in reducing the latency of the connection.
- New supported HTTP methods: This version added six new methods: PUT, PATCH, DELETE, CONNECT, TRACE, and OPTIONS.
- Content negotiation: The new HTTP standardized which content will be exchanged by clients and servers.
- Caching: Additionally, a bunch of new caching mechanisms were introduced such as the Cache-Control header, allowing clients and servers to control caching behavior more effectively.
18 years of improvement
HTTP/1.1 was such a game changer for the Internet that it works so well that even through two revisions, RFC 2616 published in June 1999 and RFC 7230– RFC 7235 published in June 2014, HTTP/1.1 was extremely stable until the release of HTTP/2.0 in 2014 — Nearly 18 years later. Before continuing to the next section about HTTP/2.0, let us revisit what journey HTTP/1.1 has been through.
The introduction of HTTPS for better web security
One of the most significant improvements of HTTP was the introduction of HTTPS. In 1994, Netscape Communications bring out the concept of an encrypted transmission layer on top of the HTTP protocol. Following that was the development of HTTPS protocol which utilizes the SSL (Secure Sockets Layer) protocol to encrypt data into binary code, ensuring secure communication and preventing unauthorized interception of data transmitted between HTTP connections.
As the Internet grew in users and traffic. Websites are no longer just academic networks but more like the jungle. And so, the need for an encrypted transport layer became paramount. The success of SSL demonstrated the importance of securing online communication which then formed the creation of e-commerce websites. Over time, SSL evolved into TLS (Transport Layer Security), which is now the industry standard for securing web communication.
The creation of RESTful API
In 2000, a new concept called representational state transfer (or REST) was introduced for HTTP. The story begins with Roy Fielding’s doctoral dissertation, where he introduced REST as an architectural style that provides a set of principles for designing networked applications. The key characteristic of REST relies on making requests to specific URIs using basic HTTP/1.1 methods to access or update resources.
This approach quickly gained popularity due to its simplicity, scalability, and widespread adoption of HTTP as a protocol for web communication. REST provides a flexible and interoperable means for different applications and systems to communicate and exchange data. In fact, during the 2010s, RESTful APIs became so commonly used that they became the standard choice for web developers when building web APIs.
Cross-Origin Resource Sharing
With the birth of HTTP/1.1, web development emerges a surge in dynamic websites, powered by JavaScript, which enables client-side rendering and API calls from the client to the server. However, this shift also exposed potential security vulnerabilities in HTTP requests.
To overcome these concerns, it is important to address some of the constraints on which client domains were able to access the server’s resources. And so, two essential mechanisms were introduced: Cross-Origin Resource Sharing (CORS) and Content Security Policy (CSP).
Head of Line issue of HTTP/1.1
In HTTP/1.1, requests can run in parallel, and one TCP connection can handle multiple HTTP requests. However, the handling of each request occurs sequentially. This means that as the number of HTTP requests increases, subsequent requests will have to wait until the previous requests finish processing. Consequently, this scenario can lead to head-of-line (HOL) blocking, wherein a slow or large response from the server hinders other smaller, quicker responses from being sent to the client, causing a bottleneck in the connection.

HTTP 2
Accounting for the drawback of HTTP/1.1, during the 2010s Google was developing an experimental protocol called SPDY that allows more effective data transmission which then serves as the foundation of the HTTP/2 protocol in 2015.
As mentioned earlier, the main goal of HTTP/2 is to improve the performance of its previous version, which implements the following features:
- Multiplex connection: HTTP/2 eliminates the HOL problem with multiplexing and allows clients and servers to send multiple requests and responses on a single TCP connection.
- Binary protocol: instead of a text-based format like HTTP/1.1, HTTP/2 is a binary protocol making it better at parsing and processing data.
- Header compression: to resolve headers that got duplicated when sending massive HTTP request, HTTP/2 compresses request and response headers which removes the duplication and improve the efficiency of the overall size of HTTP requests and responses.
- Server Push: HTTP/2 introduced the server push mechanism that allows servers to initially send the resources to clients and store them in the client’s cache without waiting for clients to send requests.
- Stream Prioritization: HTTP/2 allows clients and servers to assign priorities on a batch of requests which we can control the order of expected responses. This prioritization helps ensure that more critical resources are delivered first, improving user experience and page load times.
With the adaptation of modern technology, HTTP/2 steadily reduces the number of TCP connections when compared with its predecessor.
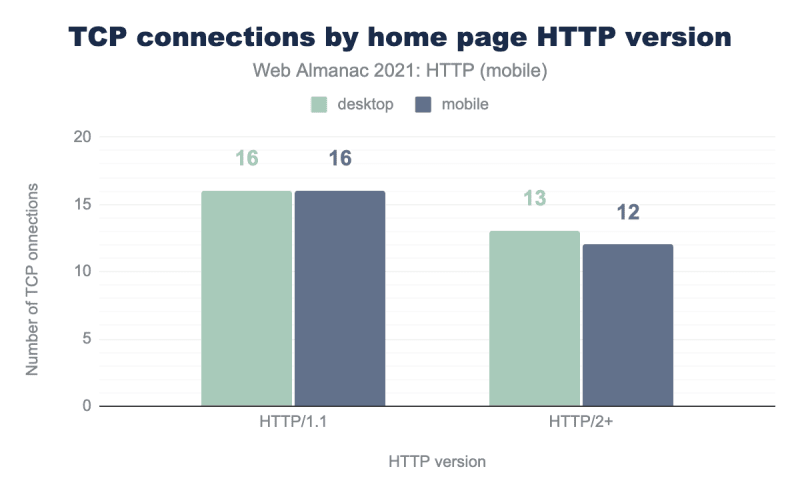
As a result of the significant performance improvements, an increasing number of websites are shifting towards adopting the HTTP/2 protocol. According to the HTTP Archive report in 2021, approximately 60% of web pages are now using HTTP/2.
HTTP 3 – Delegation to QUIC protocol
As HTTP has evolved for around three decades, its core client-server connection protocol is still the same. In the next major version of HTTP, HTTP/3’s first draft version is to overcome the use of TCP but instead replace it with QUIC (Quick UDP Internet Connections) protocol which is proven more efficient in reducing latency, improving congestion control, and offering better error recovery.
Just like TCP, QUIC is multiplexed but the key difference here is that QUIC runs over UDP protocol. UDP is simple, lightweight, and faster than TCP but has a drawback of data reliability and security. Thus, to compromise with this issue, QUIC also implements a higher-level feature of packet loss detection and retransmission independently that dramatically decreases the effect of packet loss where one packet of information does not make it to its destination, it will no longer block all streams of information.
Another advantage of HTTP/3 is that it differs from HTTP/2, which still relies on HTTPS for security connections. Meanwhile, HTTP/3 always establishes encrypted connections through the integration of the TLS security protocol.
The Future of HTTP
With the new introduction of the latest versions of HTTP, the future of HTTP aims for better web performance, default encrypted security connection, and higher user experience. For now, HTTP/3 is still in the standardization process, but soon more websites and applications are likely to transition to this new protocol. As of 2022, 26% of websites have already used HTTP/3.
Questions
To get the most out of this article, feel free to complete these challenges👇:
🐣Easy mode:
- What is the current HTTP version used for your project?
Since when has HTTPS been in use?
🔥Hard mode:What main aspects allow HTTP/3 faster than its predecessor?
References
- https://blog.bytebytego.com/p/http-10-http-11-http-20-http-30-quic
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP
- https://www.baeldung.com/cs/http-versions
- https://www.cloudflare.com/learning/performance/what-is-http3/
- https://almanac.httparchive.org/
- https://httpwg.org/specs/rfc9114.html
- https://w3techs.com/technologies/details/ce-http3

Top comments (0)