
MongoDB 6.0.0 was just released yesterday and is now available for download.
This version has improvements to existing features, also new products have been introduced to empower you to build faster, troubleshoot less, and removes complexity from your workflows.
Here are some of the latest features recently added:
Time Series
Time series data is a sequence of measurements over some time with common metadata. Managing time series workloads is required across a variety of industries. Examples include sensor readings for manufacturing; vehicle-tracking device logs for transportation and logistics; data from consumer IoT devices, such as smartwatches; customer interaction data in e-commerce; and financial transactions data for the securities and cryptocurrency industries.
Time series data is everywhere, and companies need to collect and analyze it to understand what is happening in their businesses and assess future needs quickly.
Time series workloads typically have the following attributes:
- Inserts arrive in batches that are sequentially ordered by time
- Data sets are typically append-only
- Older data can be deleted or archived
- Queries and aggregations are typically applied to data within a specified time range
These unique qualities come with various challenges for developers looking to build applications that leverage time series data. One is data volume: Time series workloads can generate data many times per second, making storage capacity (and associated costs) a significant concern. Another is continuity of data. Gaps in time series data — for example, when sensors go offline — can make analyzing the data significantly more difficult.
With that in mind, the following improvements have been made to MongoDB 6.0's time series performance:
- Add a compound index on time, metadata, or measurement fields
- Use the $or, $in, and $geoWithin operators with partial indexes on a time series collection
- Secondary indexes on measurements:
MongoDB customers can create a secondary or compound index on any field in a time series collection. This enables geo-indexing (for example, tracking changes over time on a fleet of vehicles or equipment). These new index types also provide improved read performance.
- Sort operations:
Optimizations to last point queries, which let the user find the most recent entry in a time series data collection. The query executes a distinct scan looking only for the last point rather than executing a scan of the full collection. Also included in this release will be a feature that enables users to leverage a clustered index or secondary index to perform sort operations on time and metadata fields in most scenarios in a more optimized way.
Change Streams
Users now anticipate real-time, event-driven experiences, such as activity feeds, notifications, or recommendation engines, thanks to the emergence of apps like Seamless or Uber. However, moving at real-world speeds is challenging as your application must be able to quickly identify and respond to data changes.
Change streams, which were first introduced in MongoDB 3.6, offer an API for streaming any changes to a MongoDB database, cluster, or collection without the significant overhead associated with having to poll your entire system. This way, your application can automatically react, producing an in-app message notifying you that your delivery has left the warehouse or creating a pipeline to index new logs as they are produced.
With MongoDB 6.0, change streams have a new functionality that supports a wider range of use cases while enhancing efficiency.
When a document is modified or deleted, users can now simply access the before and after states of the full document, also known as pre- and post-images, respectively. Assume you are using a time-to-live (TTL) index to delete user sessions as they approach their expiration date while storing user sessions in a collection. You can make references to information in the destroyed documents to give the user more details about their session after the fact. Or perhaps you need to send an updated version of the entire document to a downstream system each time there is a data change. Added support for retrieving the before and after states of a document greatly expands the use cases change streams can address.
Before MongoDB 6.0, change streams supported data manipulation language (DML) operations. Now, they support data definition language (DDL) operations such as creating and dropping indexes and collections so you can react to database events in addition to data changes.
Change streams are built on MongoDB’s aggregation framework, which allows teams to capture and react to data changes and filter and transform the associated notifications as needed. By leveraging filtering they have those stages automatically pushed to the optimal position within a change stream pipeline, dramatically improving performance.
New aggregation operators
These new operators enabe you to push more work to the database — while spending less time writing code or manipulating data manually. They will automate key commands and long sequences of code, freeing up more developer time to focus on other tasks.
For instance, you can easily discover important values in your data set with operators like $maxN , $minN , or $lastN. Additionally, you can use an operator like $sortArray to sort elements in an array directly in your aggregation pipelines.
Below is a list with all new operators:
-
$bottom: Returns the bottom element within a group according to the specified sort order -
$bottomN: Returns an aggregation of the bottom n elements within a group, according to the specified sort order -
$firstN: Returns an aggregation of the first n elements within a group. Distinct from the $firstN array operator -
$firstN(array operator): Returns a specified number of elements from the beginning of an array. Distinct from the $firstN accumulator -
$lastN: Returns an aggregation of the last n elements within a group. Distinct from the $lastN array operator -
$lastN(array operator): Returns a specified number of elements from the end of an array. Distinct from the $lastN accumulator -
$linearFill: Fills null and missing fields in a window using linear interpolation based on surrounding field values -
$locf: Last observation carried forward. Sets values for null and missing fields in a window to the last non-null value for the field -
$maxN: Returns an aggregation of the n maximum valued elements within a group. Distinct from the $maxN array operator -
$maxN(array operator): Returns the n largest values in an array. Distinct from the $maxN accumulator -
$minN: Returns an aggregation of the n minimum valued elements within a group. Distinct from the $minN array operator -
$minN(array operator): Returns the n smallest values in an array. Distinct from the $minN accumulator -
$sortArray: Sorts an array based on its elements -
$top: Returns the top element within a group according to the specified sort order. Distinct from the command top -
$topN: Returns an aggregation of the top n elements within a group, according to the specified sort order -
$tsIncrement: Returns the incrementing ordinal from a timestamp as a long -
$tsSecond: Returns the seconds from a timestamp as a long
Queryable encryption
With the introduction of Queryable Encryption, MongoDB is the only database provider that allows customers to run expressive queries, such as equality (available now in preview) and range, prefix, suffix, substring, and more (coming soon) on fully randomized encrypted data. This is a huge advantage for organizations that need to run expressive queries while also confidently securing their data.
Why is Queryable Encryption an important technology?
Businesses with highly sensitive workloads need more technical tools to manage and restrict access to private and regulated data. Due to compliance requirements, many commercial and federal customers must separate people responsibilities due to the sensitivity of some workloads. For instance, database administrators (DBAs) handle the data while analysts at a stock brokerage firm query to locate clients and the quantity of shares. However, sensitive and personally identifiable information (PII), such as the social security number (SSN), should be totally hidden.
Current state and challenges around data security
Although existing encryption solutions (in-transit and at-rest) cover many regulatory use cases, none of them protects sensitive data while it is in use. In-use data encryption is often required for high-sensitivity workloads for customers in financial services, healthcare, and critical infrastructure organizations. Currently, challenges around in-use encryption technologies include:
In-use encryption is highly complex, involving custom code from the application side to encrypt, process, filter, and decrypt the data to show it to the users. It also involves managing encryption keys to encrypt/decrypt the data.
Developers need cryptography experience to design a secure encryption solution.
Current solutions have limited or no querying capabilities, which makes using encrypted data in applications difficult.
Some existing tools, such as homomorphic encryption or secure enclaves, have performance unsuited to scalable encrypted search, require proprietary hardware, or have uncertain security properties.
Queryable Encryption
Queryable Encryption removes operational heavy lifting, resulting in faster app development without sacrificing data protection, compliance, and privacy security requirements.
Below is a sample flow of operations in which an authenticated user wants to query the data, but now the user can query on fully randomly encrypted data.
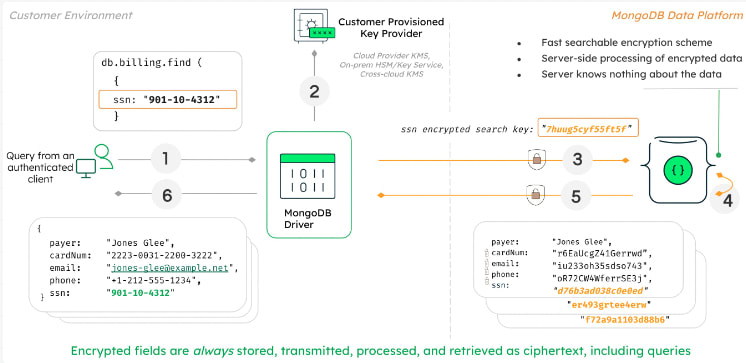
In this example, let’s assume we are retrieving the SSN of a user. When the applicant submits the query, MongoDB drivers first analyze the query.
Recognizing the query is against an encrypted field, the driver requests the encryption keys from the customer-provisioned key provider, such as AWS Key Management Service (AWS KMS), Google Cloud KMS, Azure Key Vault, or any KMIP-enabled provider, such as HashiCorp Vault.
The driver submits the query to the MongoDB server with the encrypted fields rendered as ciphertext.
Queryable Encryption implements a fast, searchable scheme that allows the server to process queries on fully encrypted data without knowing anything about the data. The data and the query itself remain encrypted at all times on the server.
The MongoDB server returns the encrypted results of the query to the driver.
The query results are decrypted with the keys held by the driver and returned to the client and shown as plaintext.
Advantages of Queryable Encryption
Rich querying capabilities on encrypted data:
Only MongoDB's database service enables users to execute complex query expressions on encrypted data, including range, equality, prefix, suffix, and more. (The remainder will be included in subsequent releases; equality search is included in the Preview release.) Customers benefit greatly from this since they can perform expressive queries with confidence and data security.Data encrypted throughout its lifecycle:
Your most sensitive data is further protected by Queryable Encryption, which adds an additional layer of protection. Data is safe while in storage, transit, memory, logs, and backups. Queryable Encryption also fully randomizes data on the server before encryption.Strong technical controls for critical data privacy use cases:
Strong technical controls allow customers to meet the strictest data privacy requirements for confidentiality and integrity using standards-based cryptography. Customers always maintain control of encryption keys, and data encryption/decryption happens only on the client side. This guarantees that only authorized users with access to the client-side application and the encryption keys can see the plaintext data. These strong controls can help customers meet data privacy requirements mandated by HIPAA, GDPR, CCPA, and more.Faster application development:
Utilizing standards-based cryptography, clients are able to adhere to the most stringent data privacy requirements for confidentiality and integrity. Data encryption and decryption only take place on the client side, and encryption keys are always under the control of the customer. This ensures that the plaintext data can only be viewed by authorized people who have access to the client-side application and the encryption keys. These effective controls can assist clients in complying with data privacy laws like HIPAA, GDPR, CCPA, and others.Reduce institutional risk:
Customers who move their data to the cloud can entrust MongoDB Atlas with their more delicate information. Customers can preserve control over their data while fully randomized encrypted data can be subject to rich, expressive querying thanks to queryable encryption.
To make it simple for users to build and concentrate on their business needs, MongoDB supports robust security defaults to ensure that security configurations like authentication, authorization, in-transit and at-rest encryption are always on. With Queryable Encryption, you can perform sophisticated queries on the encrypted data, which adds still another layer of protection and a powerful technological control allowing our customers to protect data throughout its lifecycle.
You can also review the release notes to learn more about the new features and the upgrade procedures.
MongoDB 6.0 is not an automatic upgrade unless you use Atlas serverless instances if you are not an Atlas user, download MongoDB 6.0 directly from the download center.
If you are already an Atlas user with a dedicated cluster, take advantage of the latest, most advanced version of MongoDB. Here’s how to upgrade your clusters to MongoDB 6.0.




Latest comments (1)
Very complete, thanks !