
I've been exploring the GPT-4 with Vision API and I have been blown away by what it is capable of. As OpenAI describes it, ChatGPT can now see, hear, and speak. But how effective is the API? In this article, I'm doing a deep dive into the GPT-4 with Vision API describing the technical details to use it.
What is GPT-4 with Vision API to start with?
GPT-4 with Vision (also called GPT-V) is an advanced large multimodal model (LMM) created by OpenAI, capable of interpreting images and offering textual answers to queries related to these images. This model blends the capabilities of visual perception with the natural language processing. There are several use cases for the Vision API, from recognising objects to translating mockups into real software or generating real time descriptions on images and videos.
The Basic - How to use the API?
The API is used similarly to the standard completion API, I recommend using Python for integration with the API, as it's the best-supported language in Open AI's documentation. If you are new to this - and perhaps using Windows like me - you might find my article Getting started with OpenAI in Python helpful where I explain all the details on how to set up Python and interact with OpenAI.
Once your Python environment is setup, the following code can connect to OpenAI and answer a simple question:
What can you see in the image?
from openai import OpenAI
import os
# create OpenAI client
client = OpenAI(
api_key = os.environ.get("OPENAI_API_KEY"),
)
# call the API with prompt "What can you see in the image?"
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What can you see in the image?"},
{
"type": "image_url",
"image_url": {
"url": "https://jstoppa.com/posts/exploring_the_GPT_with_Vision_api_image_and_video/GPTVision_example.png",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
here's the image used in the example:

and the result from the GPT with Vision API...
The image shows a part of a building that looks to be residential in nature. It has a slanted roof covered with dark grey slate tiles. There's a dormer with a window, which suggests an attic or loft space, and the facade includes red brickwork with stone elements that provide a decorative pattern. Below the bricks and stone there’s a ledge or overhang, possibly indicating that this section of the building is above ground level, such as on the first floor or higher. The windows are white-framed and double-glazed. Above the dormer, there are red chimney pots visible, indicating the presence of one or more fireplaces within the building. It appears to be a cloudy day, as the sky is overcast.
Very impressive results! It's able to describe the image including minimal details using very comprehensive words, it even highlights that the day is cloudy like most days in London.
Looking at more complex scenarios
I've noticed the model to start struggling when is asked more complex questions such as explaining a chart or giving the specific location of items in images. OpenAI highlights in their website that the model may not be accurate in certain scenarios, including spatial reasoning, counting, resolving CAPTCHAs or analysing medical images, last two most likely due to security concerns.
I was particularly interested in exploring how I could use the model to automate simple tasks in the computer. ChatGPT is very good at explaining tasks and meticulously outlines the steps to carry those tasks, but executing them is well beyond the model's and vision's capabilities.
My first attempt to test the above involved creating a Python script that captures a screenshot of my desktop and identifies Google Chrome on the screen. When I asked the model to provide the exact coordinate of the Google Chrome icon, it would always return very vague answers. In these cases, I realised that the model needs some hint, I tried with an overlaid grid with references
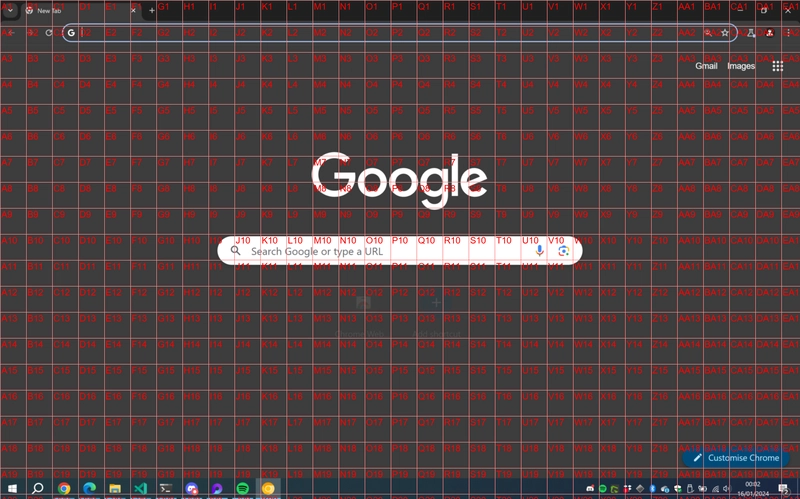
and prompt the following:
Using the alphanumeric grid overlaid on the image, identify the quadrant where the Google Chrome Icon is located. Please respond with only the quadrant reference (e.g., 'G3') if the icon is found, or 'not found' if the icon is not in the image. The output will be used for automated processing, so ensure the response is in the correct format.
This approach was still not great, GPT would correctly guess the quadrant about 50% of the time. To improve accuracy, I gave GPT a second chance: I zoomed in around the area of the first quadrant chosen and requested GPT to find the quadrant again.
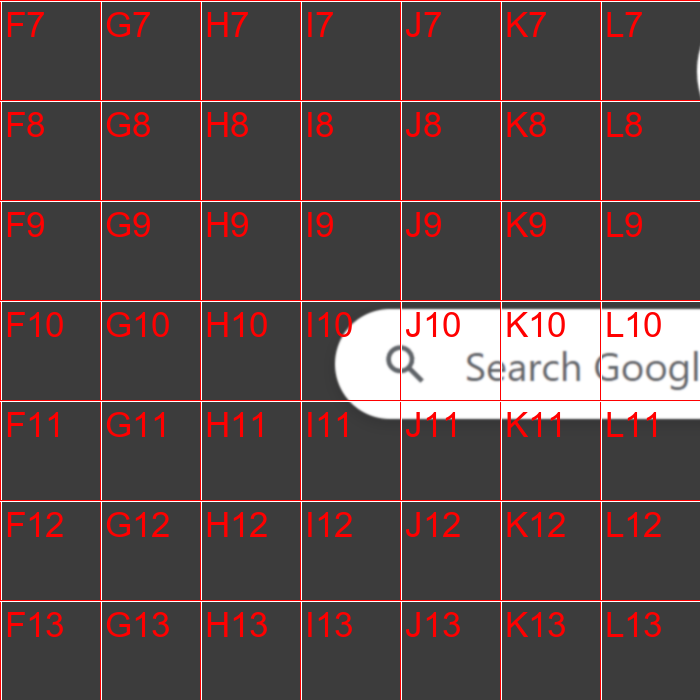
this time GPT would get it right most of the times which gives a much more accurate result.
The final result was great, with that info I'd then drive the mouse to locate the icon and double click on Google Chrome. In the example below, I've run the script and GPT handled the rest, the task was to find Italian restaurants in London.
What about Videos?
The GPT with Vision API doesn't provide the ability to upload a video but it's capable of processing image frames and understand them as a whole. A good example could involve streaming video from a computer's camera and asking GPT to explain what it can see. I've put together an example on how this can be done using Python.
We first need to switch on the camera and take some frames, for this we can use the great OpenCV library to take frames from the video and send them to Chat GPT API.
The code below will capture 200 frames at an interval of 100ms and store them in an array
import cv2, base64, time
# Initiate the video capturing object
cap = cv2.VideoCapture(0)
# Set an array to store the frames
base64Frames = []
for i in range(200):
# Capture the frame
ret, frame = cap.read()
# Store the frame in the base64Frames array
_, buffer = cv2.imencode(".jpg", frame)
encoded_image = base64.b64encode(buffer).decode("utf-8")
base64Frames.append(encoded_image)
# Wait for 100ms before capturing the next frame
time.sleep(0.01)
the array can then be sent to the GPT Vision API including a prompt to describe what it can see in the video
from openai import OpenAI
import os
# Initialise Open AI client
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
# Frames from previous example
base64Frames = []
message = [
{ "role": "user",
"content": [
"These are frames of a video. Can you describe what you can see in no more than 20 words?",
*map(lambda x: {"image": x, "resize": 768}, base64Frames[0::60]), ],
},
]
parameters = { "model": "gpt-4-vision-preview", "messages": message, "max_tokens": 500 }
result = client.chat.completions.create(**parameters)
print(result.choices[0].message.content)
I took a video of a beautiful marble run I recently bought in China for my daughter, let's see what GPT Vision has to say about it...
And the result was the following:
I can see a mechanical device made of wood and some transparent materials, possibly acrylic or glass. It has several circular elements, which look like they could be tracks or pathways for a ball to roll on. The construction also includes gear-like components, suggesting that the device has moving parts and might be operated by turning the gears, possibly as part of a kinetic installation or a marble machine. The repeated frames suggest that the device might be in motion during the video.
The model has taken the group of images and analysed them as a whole, the description gives a high level understanding of what i can see although is not entirely sure about the motions.
Combining Vision and Text to Speech
The final test I wanted to do involved testing it with the Text to speech API, rather than displaying the text on the screen it would directly say it out loud. This is also a powerful API as you could have different agents interacting with each other, that's probably an example for another day.
The Python script below simulates a conversation between "Nova" and "Onyx", two voices from the Text to speech API. The script turns on the camera and "Nova" asks "Onyx" what it can see, it iterates until the letter Q is pressed. The video is displayed in the screen and the scripts takes a frame every 100ms until it capture 200, the result is then sent to the Text to speech API to reproduce it.
from openai import OpenAI
import os, cv2, base64, requests, soundfile as sf, sounddevice as sd, io, time
def capture_and_process_frames():
_, buffer = cv2.imencode(".jpg", frame)
encoded_image = base64.b64encode(buffer).decode("utf-8")
base64Frames.append(encoded_image)
cv2.imshow('Real-time Video', frame)
def process_frames():
print('\nGetting results from GPT Vision')
message = [
{ "role": "user",
"content": [
"These are frames of a video. Can you describe what you can see? Start the phrase with 'I can see' followed by your answer",
*map(lambda x: {"image": x, "resize": 768}, base64Frames[0::60]), ],
},
]
parameters = { "model": "gpt-4-vision-preview", "messages": message, "max_tokens": 500 }
result = client.chat.completions.create(**parameters)
return result.choices[0].message.content
def play_audio(message: str, voice: str):
response = requests.post(
"https://api.openai.com/v1/audio/speech",
headers={ "Authorization": f"Bearer { os.environ.get("OPENAI_API_KEY") }", },
json={ "model": "tts-1-1106", "input": message, "voice": voice, "response_format": "opus" },
)
with io.BytesIO(response.content) as audio_io:
data, samplerate = sf.read(audio_io, dtype='float32')
sd.play(data, samplerate)
sd.wait()
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # Codec for MP4
out = cv2.VideoWriter('output.mp4', fourcc, 20.0, (640, 480)) # Output file, codec, frame rate, and size
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
cap = cv2.VideoCapture(0)
intro_message = """This experiment will switch on your camera, take frames,
send them to ChatGPT Vision and produce an audio with the description.
It will continue doing it until (Q) key is pressed. Let's get started, what can you see Onyx?"""
print(intro_message)
play_audio(intro_message, "nova")
base64Frames = []
i = 0
while True:
ret, frame = cap.read()
out.write(frame)
print("\r" + " " * 50, end='\r')
print(f"Capturing frames: {i}", end='', flush=True)
if ret:
capture_and_process_frames()
if i == 200:
out.release()
result = process_frames()
print(result)
play_audio(result, "onyx")
base64Frames = []
i = -1
play_audio("Let's do it again, what can you see now GPT?", "nova")
out = cv2.VideoWriter('output.mp4', fourcc, 20.0, (640, 480))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
time.sleep(0.01)
i = i + 1
cap.release()
cv2.destroyAllWindows()
I took a video to show what the script does, you can run it in your own machine to test it.
Conclusion
This should give a good understanding of what's possible and help to dig even deeper into GPT with Vision API. With some imagination, one can bridge the gap between the model's limitations and strengths.
Some key points from this post:
- The model can handle both images and videos, although a bit of image processing is required for videos.
- Taking images is straightforward, it can process URLs or local images converted to Base64.
- The model struggles with tasks such as counting, understanding charts or anything that involves spatial reasoning.
- For spatial reasoning, it's possible to give the model hints such as highlighting areas in the image, this helps the model to produce a more accurate result.
- It can process frames of a video and understand them as a whole.
If you liked this article and would like to read more, then follow me on X at @juanstoppa, where I post regularly about AI.

Top comments (1)
Hello, do you have any e-mail that we can contact you for a paid article?