An awesome 😎 reading list

An ever-increasing number of organizations are developing applications that involve machine learning components. The complexity and diversity of these applications calls for software engineering techniques to ensure that they are built in a robust and future-proof manner.
Do traditional software engineering practices apply equally to the development of applications with ML components, or do these practices need to be adapted to cater for particular ML characteristics?
To investigate this question, we have reviewed both scientific literature and popular publications to identify software engineering best practices that are recommended or used by teams that develop machine learning applications.
Awesome literature
Before diving into the best practices that we identified, let me share some early observations about the literature we collected. For more details, you can take a look at the awesome reading list that we compiled.
- Even though the surge of interest in machine learning started relatively recently, there is already a large number of articles, blogs, white papers, etc. readily available. Out of everything we encountered, we selected close to 40 articles to include on our recommended reading list.
- Very few articles cover the entire lifecycle of developing and deploying machine learning applications. Only 3 qualified for our category of Broad Overviews.
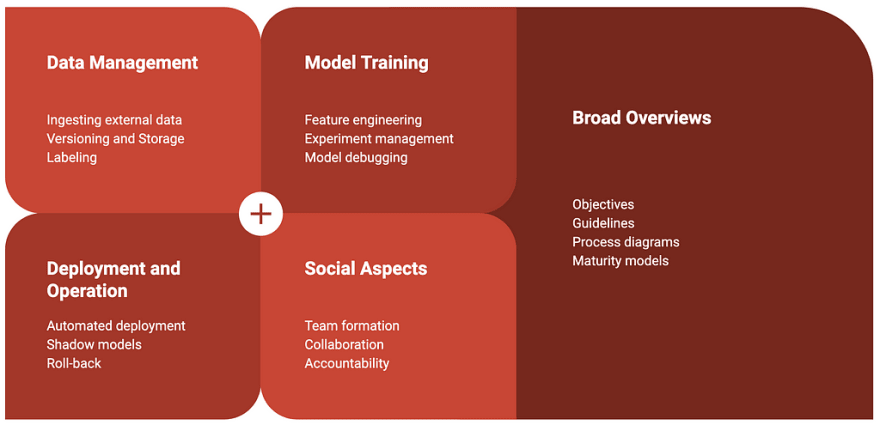
- The scientific literature on the topic of software engineering practices for machine learning is still fairly limited. Only about half of our recommended readings are scientific articles.
- Among authors, there is a lot of variation in how they describe the development process of applications with ML components. There seems to be no clear consensus on the names of steps in the process and the boundaries between them. That said, some broad categories of activities can be recognized. We divided the selected literature into the categories of (1) Data Management , (2) Model Training , and (3) Deployment and Operation , depending on the activities in their scope.
- Additionally, we found valuable articles on how to organize teams and projects involved in development of ML applications. We grouped those into the category of Social Aspects. So far, we identified only one scientific article for that category.
Best practices
Throughout the collected literature, we identified about 40 best practices. These concern for instance data versioning, feature testing, model deployment, and model performance measurement.
We are currently in the course of creating clear descriptions of these best practices, documenting their literature sources, and organizing them into development process stages.
We are also investigating to what extent these best practices are actually adopted by practitioners. For this purpose, we are engaging with practitioners through interviews as well as an online survey. This will allow us to measure adoption, but also to identify common challenges for practitioners and researchers in the field.
Help us
If you are involved in developing a machine learning application, you can help us by taking the survey and inviting your colleagues and friends to do the same.
As our research progresses, we will be sharing our results right here.
Joost Visser is professor of Software and Data Science at Leiden University. Previously, Joost held various leadership positions at the Software Improvement Group. He is the author of numerous publications on software quality and related topics.
Joint work with Alex Serban, Holger Hoos, and Koen van der Blom.





Top comments (0)