
Original Blog Post: My Blog - How to Create Jobs With Multiple Tasks in Databricks
Note: This video is in Filipino/Tagalog.
When working with data it's very useful to be able to create data pipelines where we can have tasks in a pipeline run in sequence or in parallel or have dependencies witch each other, where the next tasks will only run when their dependencies or previous tasks have finished running.
To accomplish, usually we'd use external task orchestrators like Airflow, Prefect, Nifi, or Oozie.
In the version of Databricks as of this writing, by default we are unable to create jobs with multiple tasks as shown here:
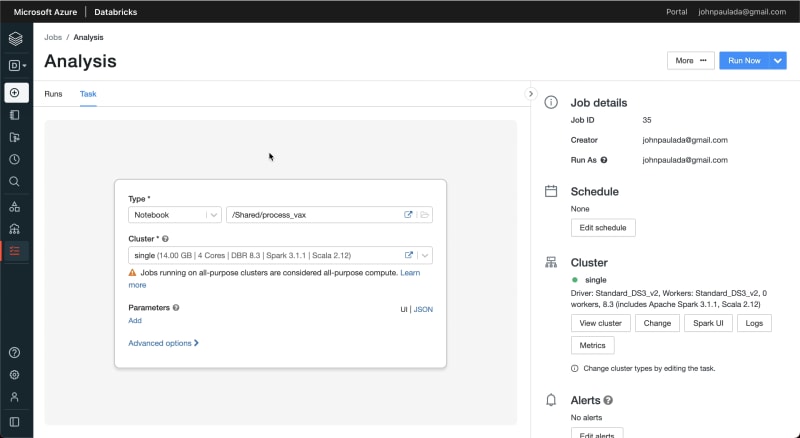
But there's a way to add multiple tasks to a job in Databricks, and that's by enabling Task Orchestration. At the time of this writing, Task Orchestration is a feature that's in public preview. This means that it's currently available for everyone, but it's not enabled by default.
To enable it we first go to the the Admin Console:
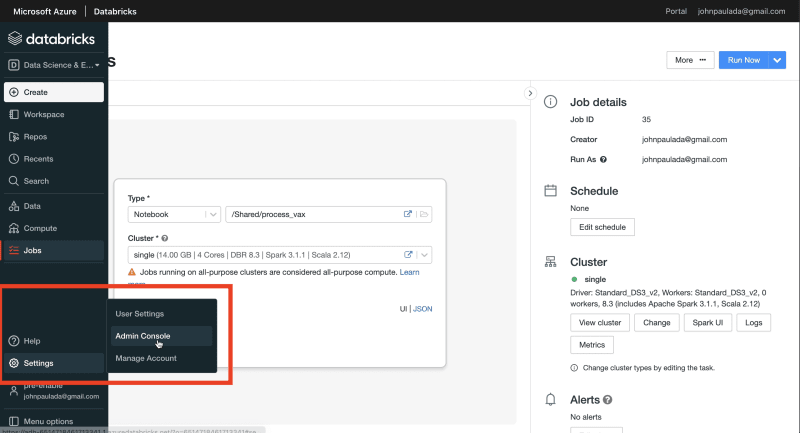
Then go to Workspace Settings tab:
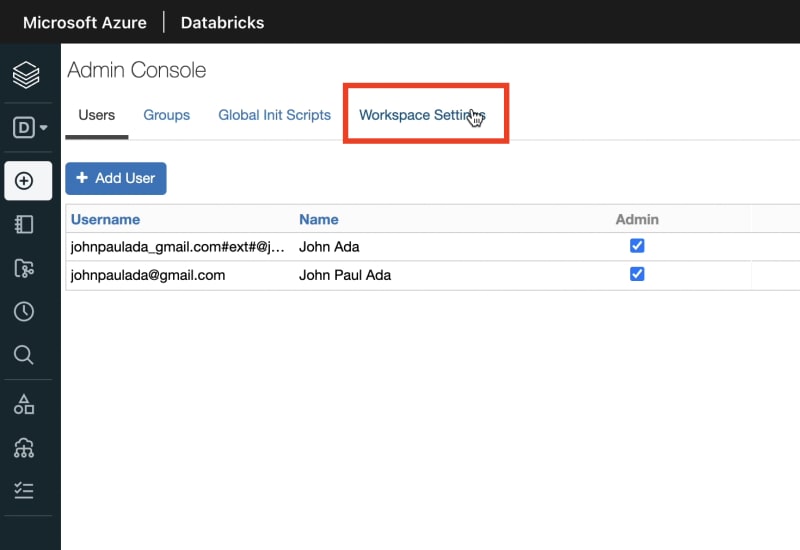
Then we'll search Task on the search bar. We'll then be able to see the switch for Task Orchestration:

It might take some time to take effect but once that's enabled, we will now be able to see a button for adding another task to our job:

After that we can just add a task similar to what we're used to. The only difference is now there is a Depends on field where we can specify the dependencies of our current task:

Once we're done adding that, we can run our job and see something like this when it's complete!

And that's a wrap! I hope this helps you setup your own data pipeline in Databricks!

Top comments (0)