
Introduction
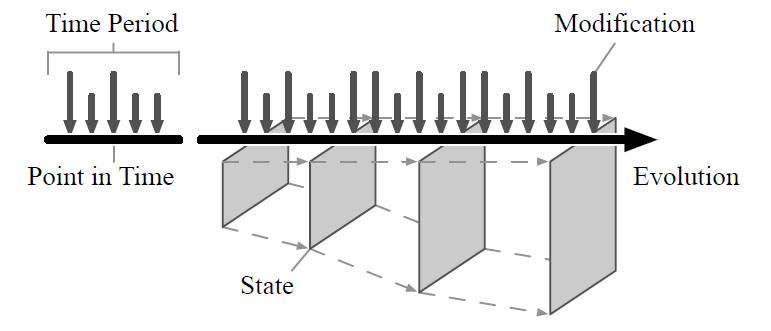
Usually, database systems either overwrite data in-place or do a copy-on-write operation followed by the removal of the outdated data. The latter may be some time later from a background process. Data, however, naturally evolves. It is often of great value to keep the history of your data. You, for instance, might record the payroll of an employee on the first of March in 2019. Let’s say it’s 5000€ / month. Then as of the fifteenth of April, you notice, that the recorded payroll was wrong and correct it to 5300€. Now, what’s the answer to what the salary was on March, first in 2019? Database Systems, which only preserve the most recent version, don’t even know that the payroll wasn’t right. The answer to this question depends on what source we consider most authoritative: the record or reality? The fact that they disagree effectively splits this payroll event into two tracks of time, rendering neither source entirely accurate. Temporal database systems such as SirixDB help answer questions such as these easily. SirixDB sets the transaction time; that is it records the times of transaction commits (when is a fact valid in the database). Application or valid time has to be set by the application itself (when is a fact valid in the real world/reality?).
Data Audits
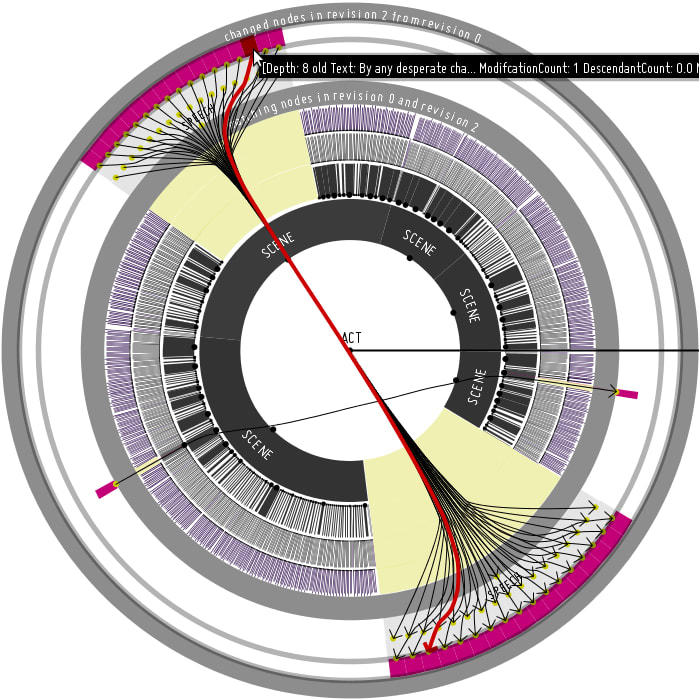
Thus, one usage scenario for SirixDB is data auditing. Unlike other database systems, it is designed from the ground up to retain old data. It keeps track of past revisions in a specialized index structure for (bi)temporal data. SirixDB uses a novel sliding snapshot versioning algorithm by default to version data pages. It balances read and write performance while avoiding any peaks.
SirixDB is very space-efficient, while it stores a lot of additional data which in the future will be used by the query optimizer. Depending on the versioning algorithm during writes, it only copies changed records plus possibly a few more. Thus, SirixDB, for instance, usually does not copy a whole database page if only a single record has changed. Instead, SirixDB syncs page-fragments to persistent storage during a commit. It drops the requirement to cluster related nodes physically. Sequentially accessing physically dispersed nodes on flash-based storage is in the same order of magnitude as accessing physically clustered nodes on a disk. SirixDB never allows to override or delete old revisions. A single read-write transaction appends data at all times. For sure, you can revert a resource to a specific revision and commit changes based on this version. All revisions in-between are accessible for data audits. Thus, SirixDB can support answering questions such as who changed what and when.
Time Travel queries
Data audits are about how specific records have changed. Time travel queries can answer questions like these. However, they also allow reconstructing records as they looked at a particular time or during a specific period. They also help to analyze how the whole document changed over time. You might want to analyze the past to predict the future. Through additional temporal XPath axes and XQuery functions, SirixDB encourages you to look into how your data has evolved.
The following time-travel query gives an initial impression of what's possible:
let $doc := jn:open('database','resource', xs:dateTime('2019-04-13T16:24:27Z'))
let $statuses := $doc=>statuses
let $foundStatus := for $status in bit:array-values($statuses)
let $dateTimeCreated := xs:dateTime($status=>created_at)
where $dateTimeCreated > xs:dateTime("2018-02-01T00:00:00")
and not(exists(jn:previous($status)))
order by $dateTimeCreated
return $status
return {"revision": sdb:revision($foundStatus), $foundStatus{text}}
The query opens a database and therein a resource in a specific revision based on a timestamp (2019–04–13T16:24:27Z). It then searches for all statuses, which have a created_at timestamp, that has to be greater than the first of February in 2018 and did not exist in the previous revision. => is a dereferencing operator to dereference keys in JSON objects. You can access array values as shown with the function bit:array-values or through specifying an index, starting with zero: array[[0]], for instance, specifies the first value of the array.
Fixing application or human errors
Introducing application or human error is very common. Some code, for instance, might delete the wrong customer from your database. Maybe you want to revert the last hour of changes in a document. In these and similar cases, you can revert to a specific point in time where everything was in a known good state and commit the revision again. Alternatively, you might select a particular record, correct the error, and commit a new revision.
SirixDB
SirixDB is a storage system, which brings versioning to a sub-file granular level while taking full advantage of flash-based drives as SSDs. As such, per revision as well as per page deltas are stored. Time-complexity for retrieval of records and the storage are logarithmic (O(log n)). Space complexity is linear (O(n)). Currently, we provide several APIs which are layered. A very low-level page-API, which handles the storage and retrieval of records on a per page-fragment level. A transactional cursor-based API to store and navigate through records (currently XML as well as JSON nodes) on top. A DOM-alike node layer for simple in-memory processing of these nodes, which is used by Brackit, a sophisticated XQuery processor and last but not least a RESTful asynchronous HTTP-API. SirixDB provides
- The current revision of the resource or any subset thereof
- The full revision history of the resource or any subset thereof
- The full modification history of the resource or any subset thereof
SirixDB not only supports all XPath axes to query a resource in one revision but also temporal axes which facilitate navigation in time. A transactional cursor on a resource can be started either by specifying a specific revision number or by a given point in time. The latter starts a transaction on the revision number which was committed closest to the given timestamp.
Conclusion
SirixDB is built from the ground up to retain the histories of resources. It takes care of storing each new revision in a space-efficient manner. Querying is still very efficient. Every revision is indexed together with user-defined secondary indexes. We provide several APIs as a RESTful non-blocking asynchronous API and XQuery plus a lot of custom temporal functions for both querying XML and JSON data stored in our native, binary format.
Give it a try/Help needed
If you like this, please share this on Twitter, give me a star on Github and most importantly check it out and let me know. Since a few years I'm the only maintainer of SirixDB, now more eager than ever to put forth the idea of a versioned, secure temporal analytics platform as a community. I'd love to hear any suggestions, feedback, suggestions for future work, as for instance work on horizontal scaling, bug reports, just everything… please get in contact) :-)
The Open Source repository: https://github.com/sirixdb/sirix
The new community forum: https://sirix.discourse.group
SirixDB website: https://sirix.io




Top comments (0)