Deploy and Run Jobs Spark on Scala in GCP is easy!!
This is a simple tutorial with examples of using Google Cloud to run Spark jobs done in Scala easily! :)
Install the Java 8 JDK or Java 11 JDK
To check if Java is installed on your operating system, use the command below:
java -version
Depending on the version of Java, this command can change … :)
If Java has not been installed yet, install from these links: Oracle Java 8, Oracle Java 11, or AdoptOpenJDK 8/11; always checking the compatibility between the versions of JDK and Scala following the guidelines of this link: JDK Compatibility.
Install Scala
- Ubuntu:
sudo apt install scala
- macOS:
brew update
brew install scala
Set the SCALA_HOME environment variable and add it to the path, as shown in the Scala installation instructions. Example:
export SCALA_HOME=/usr/local/share/scala export PATH=$PATH:$SCALA_HOME/
if you use Windows:
%SCALA_HOME%c:\Progra~1\Scala
%PATH%%PATH%;%SCALA_HOME%\bin
Start Scala.
$ scala
Welcome to Scala 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.9.1).
Type in expressions for evaluation. Or try :help.
Depending on your installation, the version of Scala and Java may change …
Copy and paste the HelloWorld code into Scala REPL (interactive mode via terminal)
object HelloWorld {
def main(args: Array[String]): Unit = {
println(“Hello, world!”)
}
Save HelloWorld.scala and exit REPL.
scala> :save HelloWorld.scala
scala> :q
Compile with: scalac.
$ scalac HelloWorld.scala
List the compiled .class files.
$ ls -al
HelloWorld*.class
HelloWorld$.class
HelloWorld.class
Copying the Scala code
Let’s put an order in the house!
mkdir hello
$ cd hello
$ echo \
'object HelloWorld {def main(args: Array[String]) = println("Hello, world!")}' > \
HelloWorld.scala
Create a sbt.build configuration file to define artifactName (the name of the jar file you will generate below) as “HelloWorld.jar”
echo \
'artifactName := { (sv: ScalaVersion, module: ModuleID, artifact: Artifact) =>
"HelloWorld.jar" }' > \
build.sbt
Start SBT (Scala Package and Dependency Manager) and run the code:
$ sbt
If SBT has not been installed yet, it will be downloaded and installed; it may take some time….
sbt:hello> run
[info] running HelloWorld
Hello, world!
[success] Total time: 0 s, completed 4 de fev de 2021 00:20:26
Package your project to create a .jar file
sbt:hello> package
[success] Total time: 0 s, completed 4 de fev de 2021 00:20:35
sbt:hello> exit
[info] shutting down sbt server
The compiled file is at “./target/scala-version_xpto/HelloWorld.jar”
Google cloud platform (GCP)
To use the Google cloud service, it is necessary to enable its billing; in this example, we will use cloud storage to store the jar file with our Scala code and Cloud Dataproc to execute the used Spark file.
Both services have a free usage fee, and once that quota ends, you will be charged to the credit card linked to the account!
Copy the Jar file to a bucket on cloud storage:

With the link to the bucket where the jar file is, submit a new job in the Cloud Dataproc:

Field references:
Cluster: Select the specific cluster from the list.
Job type: select “Spark”
Main class or jar: paste the link to the bucket where the jar file is located.
Before submitting, check if the Spark cluster has been created :)
After filling out the form, we have to select “submit,” the job will be executed and will appear in the list of jobs:
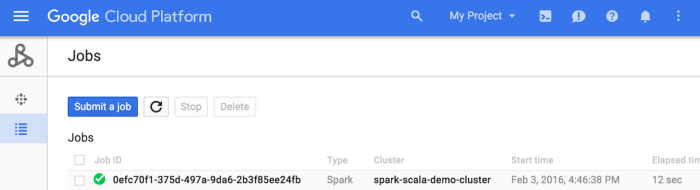
By selecting the Job ID, it will be possible to see its output:
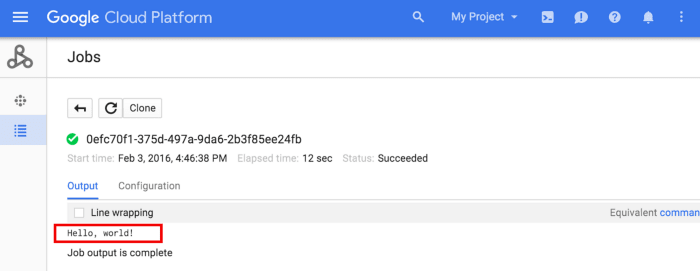
This was a brief example of deploying a Spark routine done in Scala in the Google environment, there is the possibility to interact with the Spark cluster via spark-shell accessing via ssh, and instead of doing the submit via form, we could use the Google CLI CLoud.
References:
https://cloud.google.com/dataproc/docs/tutorials/spark-scala

Follow me on Medium :)

Top comments (0)