“A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.” -- Tom Mitchell
This description of Machine Learning by Tom Mitchell in his introductory ML book is often cited. What exactly does it mean? In this article, I hope to clear up this definition and explain some of the jargon used in Machine Learning. I will mainly focus on supervised learning, which includes regression, logistic regression, and neural networks. Supervised learning enables you to create a model from labeled data, which means that the inputs you use to train your model have been assigned the correct outputs by humans beforehand.
Concretely, Machine Learning is nothing more than creating a function (like f(x)) that gives you a desired output or outputs. The only catch is that you only determine the structure of the function and a computer program controls the parameters or weights of the function. In more complex uses of Machine Learning, you might have a series of programs that break your goal down into different parts, which allows you to perform more difficult tasks like text detection.
Here are some key terms associated with Machine Learning (read in order):
Parameters: Imagine you are trying to create a line of best fit:

You need to find its slope and intercept. These are called the parameters of your line because they determine its shape, and therefore what value this line predicts for a given input. This can be written as y = parameter1x + parameter0. You might see people using Θ, or 𝛽 to denote parameters: 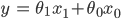
where x0=1.
Features: In machine learning, "features" are different characteristics of your data. If each row in your dataset represented a different customer, you might have columns that tell you more information about that customer, like how long they have been your customer, their last purchase, how old they are, etc. Each of those columns is considered a "feature."
Model: The prediction function you use to turn your inputs into an output or outputs.
Example: One record, or row in your dataset that features describe.
Dataset: A table with each example as a row, and features as the columns. Often you will see your dataset as an mxn matrix, where m is the number of examples and n is the number of columns.
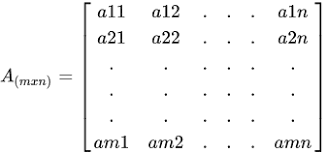
Cost Function: The function you use to evaluate your model. Imagine you have a prediction model to classify images as images of eyes or images not of eyes. For one “example,” your input will be an image. Your output will be 0 if it is not an eye, 1 if it is an eye. To represent your image (which is black and white), you translate it into a grid of pixels, which are represented by a number from 0 to 1. Your prediction function will take in all of these pixels, and output a number from 0 to 1 representing how much it resembles an eye. Informally, you can use your cost function to grade your prediction function. Your cost function gives you a high penalty (or "cost") if your prediction isn't very accurate. In scoring your model’s performance on an entire mxn dataset, you will often see an average cost divided by 2. This is represented as 1/(2m) * cost for each example, where m is the number of examples in your dataset.
Example cost function for regression: 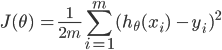 Here, J(Θ) is your cost, h(xi) is your prediction value for example xi , and yi is the true label value of xi. Your cost function is always a function of your parameters. When you adjust the parameters of your model, this can increase or decrease your model’s cost.
Here, J(Θ) is your cost, h(xi) is your prediction value for example xi , and yi is the true label value of xi. Your cost function is always a function of your parameters. When you adjust the parameters of your model, this can increase or decrease your model’s cost.
Gradient Descent: The basic procedure you use to improve your model in a supervised learning algorithm. Gradient descent adjusts your parameters in the correct direction by using your cost function. In 2-D, if you graphed your cost output on the y axis and a parameter on the x axis you would see a bowl like graph. The goal of gradient descent is to minimize the error of your model by going through many iterations to get to the bottom of the bowl. In each iteration, you set your parameters equal to your current parameters minus 𝛼 * the derivative of your cost function with respect to your parameters. 𝛼 is some positive number (called the learning rate). If you are on the left side of the bowl and your parameters are too low, the derivative of your cost function is negative. Therefore, if you set your parameters equal to your parameters minus 𝛼 times the derivative of your cost function with respect to your parameters, that is, parameters = parameters - some negative number, you get parameters = parameters + some positive number, which increases your parameters. This is equivalent to taking a step to the right of your cost function bowl. You can follow this until you get to the bottom of the bowl. If your parameters are too high, your parameters = parameters - some positive number, and you step to the left (which gets you closer to the cost function’s minimum). This is a sure fire way for your prediction function to converge to the best possible parameters.
If you understand gradient descent and the other terms, you understand the most fundamental concepts of supervised Machine Learning. In essence, supervised Machine Learning is the process of stepping down the cost function, to get a model with the smallest cost. If you want to get started quickly with implementing Machine Learning for your business, check out Telepath AI's solutions.




Top comments (2)
No nonsense and crisp intro to ML. Like it. A very different (and complementary) intro is at devopedia.org/machine-learning
Thank you so much, I will check that out!