
En parcourant la documentation de SQLite j'ai vu qu'il existait une extension nommée JSON1, qui, vous vous en doutez permet de manipuler du JSON au sein de SQLite.
Dans cet article, nous allons voir comment utiliser cette extension sur une base dénormalisée et l'impact que cela peut avoir sur les performances de lecture.
Le code utilisé est disponible ici :
C'est quoi la dénormalisation ?
Si j'en crois cette page. C'est un "Processus consistant à regrouper plusieurs tables liées par des références, en une seule table, en réalisant statiquement les opérations de jointure adéquates."
Ma version, c'est de dire que l'on va s'autoriser à ne pas utiliser les bonnes pratiques enseignées par nos professeurs #ThugLife.
Dans une base dénormalisée on s'éloigne (un peu) du Graal que représente la 3e forme normale et on s'autorise à dupliquer des données notamment en rapatriant les données des tables de jointure dans les "tables normales".
Si ce n'est toujours pas clair, l'exemple qui suit devrait vous aider à mieux comprendre.
Les tables
Plutôt que d'utiliser l'exemple des posts avec des tags, cette fois-ci, on va avoir des bars et des bouteilles de vin. On aura une relation de type many-to-many ou chaque bar peut proposer plusieurs vins et de la même manière, un vin peut être servi dans plusieurs bars.
Nous aurons 4 tables :
- wines : table des vins
- bars_normalized : tables des bars
- bars_wines : table de jointure entre wines et bars_normalized
- bars_denormalized : la table des bars où les vins servis dans ce bar sont stockés en tant que tableau d'identifiant sous le champ wines_ids
CREATE TABLE IF NOT EXISTS wines (
id TEXT PRIMARY KEY,
name TEXT,
country TEXT,
year INTEGER
);
CREATE TABLE IF NOT EXISTS bars_normalized (
id TEXT PRIMARY KEY,
name TEXT
);
CREATE TABLE IF NOT EXISTS bars_wines (
bar_id TEXT,
wine_id TEXT
);
CREATE TABLE IF NOT EXISTS bars_denormalized (
id TEXT PRIMARY KEY,
name TEXT,
country TEXT,
wines_ids JSON /* contiendra: ["wine-uuid-1","wine-uuid-234"...] */
);
Présentation de JSON1
Regardons comment effectuer les opérations usuelles sur la table bar_denormalized.
Insertion
INSERT INTO bars_denormalized (id, name, wines_ids)
VALUES (
'random-uuid',
'La taverne',
/* La méthode json() permet de vérifier que le JSON fourni est valide
et aussi de supprimer les espaces inutiles */
json('["wine-uuid-1", "wine-uuid-45", "wine-uuid-423"]')
);
Lecture
SELECT DISTINCT bars_denormalized.id, bars_denormalized.name
/* 1 - La méthode json_each() permet de sélectionner le champ
sur lequel nous allons itérer */
FROM bars_denormalized, json_each(bars_denormalized.wines_ids)
/* 2 - Une fois qu'un champ a été sélctionné avec json_each(),
on peut utiliser json_each.value pour récupérer la valeur
de chacun des éléments du tableau */
WHERE json_each.value = 'wine-uuid-1';
La requête ci-dessus va, pour chaque bar, itérer sur la tableau wines_ids. Et pour chaque élement du tableau, il va vérifier s'il est égal à l'identifiant wine-uuid-1.
Au final, cette requête renvoie tous les bars proposant le vin ayant pour identifiant wine-uuid-1.
Si nous avions eu un objet nous aurions pu utiliser la méthode json_extract. Si nous avions un tableau d'objets, la méthode json_tree.
Mise à jour et suppression
Ces deux opérations vont fonctionner de manière similaire. Dans un cas, on va venir ajouter un nouvel identifiant dans le tableau wines_ids et dans l'autre cas, on viendra en supprimer un.
UPDATE bars_denormalized
SET wines_ids = (
/* 2 - On insert la valeur à l'indice donné, à la fin du tableau */
SELECT json_insert(
bars_denormalized.wines_ids,
/* 1 - On récupère la longueur du tableau actuel, qui sera l'indice
du nouvel élément */
'$[' || json_array_length(bars_denormalized.wines_ids) || ']',
'wine-uuid-297'
)
)
WHERE id = 'bar-uuid-3';
La fonction json_insert prend trois paramètres :
- le champ dans lequel on va insérer une valeur
- l'indice auquel on va insérer cette valeur
- la valeur
/* 3 - On met à jour le champ wines_ids avec le nouveau tableau */
UPDATE bars_denormalized
SET wines_ids = (
/* 2 - On retourne un tableau sans l'élément dont l'indice a été
retourné par la sous-requête en 1 */
SELECT json_remove(bars_denormalized.wines_ids,
'$[' || (
/* 1 - On cherche l'indice de l'élément à supprimer */
SELECT json_each.key
FROM json_each(bars_denormalized.wines_ids)
WHERE json_each.value = 'wine-uuid-297'
) || ']'
)
WHERE id = 'bar-uuid-3';
La fonction json_remove prend deux paramètres :
- le champ dans lequel on va retirer une valeur
- l'indice de la valeur que l'on souhaite supprimer
Les requêtes
Pour tester les performances des deux schémas de bases de données, les requêtes auront les buts suivants :
- obtenir les noms des bars proposant des vins datant des années supérieures à 2018
- obtenir les noms des vins portugais qui sont servis dans des bars du royaume-uni
Avec ces deux requêtes, on pourra voir comment faire des requêtes "dans les deux sens".
Pour la version normalisée, on va effectuer une jointure entre les tables wines, bars_normalized et bars_wines. On viendra ensuite appliquer les filtres selon nos besoins.
SELECT DISTINCT bars_normalized.id, bars_normalized.name
FROM bars_normalized
LEFT OUTER JOIN bars_wines
ON bars_normalized.id = bars_wines.bar_id
LEFT OUTER JOIN wines
ON wines.id = bars_wines.wine_id
WHERE year > 2018;
SELECT DISTINCT wines.id, wines.name
FROM wines
LEFT OUTER JOIN bars_wines
ON wines.id = bars_wines.wine_id
LEFT OUTER JOIN bars_normalized
ON bars_normalized.id = bars_wines.bar_id
WHERE bars_normalized.country = 'United Kingdom'
AND wines.country = 'Portugal';
Concernant la version dénormalisée on va utiliser les méthodes fournies par l'extension JSON1, json_each dans notre cas.
SELECT DISTINCT bars_denormalized.id, name
FROM bars_denormalized, json_each(bars_denormalized.wines_ids)
WHERE json_each.value IN (
SELECT id
FROM wines
WHERE year > 2018
);
SELECT DISTINCT wines.id, wines.name
FROM wines
WHERE id IN (
SELECT DISTINCT json_each.value AS id
FROM bars_denormalized, json_each(bars_denormalized.wines_ids)
WHERE bars_denormalized.country = 'United Kingdom'
) AND wines.country = 'Portugal';
Petit aparté concernant la requête ci-dessus, ou plutôt la sous-requête. Si on s'en tient au sens de lecture, il peut paraitre bizarre que j'utilise json_each.value dans le SELECT alors que je vais charger ces données dans la clause FROM qui est la ligne suivante. Et justement, il faut comprendre comment les bases relationnelles interprètent les requêtes, elles sont executées comme présentée dans le schema suivant.

Ainsi, même si cela ne semble pas naturel au vu du sens de lecture, c'est en revanche tout à fait valide d'un point de vue technique.
Résultats
Lectures
J'ai effectué les tests en faisant varier différents paramètres. Sur chacune des requêtes ci-dessous, les nombres entre parenthèses représentent :
(nombre de bars, nombre de vins, nombre de vins par bar).
Les résultats sont des médianes d'une série de 5 requêtes.
| Normalisée | Dénormalisée | |
|---|---|---|
| Requête 1 (500, 1000, 100) | 874ms | 74ms |
| Requête 1 (5000, 10000, 100) | 9143ms | 569ms |
| Requête 1 (500, 1000, 500) | 4212ms | 197ms |
| Requête 2 (500, 1000, 100) | 726ms | 16ms |
| Requête 2 (5000, 10000, 100) | 8648ms | 83ms |
| Requête 2 (500, 1000, 500) | 4132ms | 27ms |
Cela saute aux yeux, la version dénormalisée est plus rapide que la version normalisée et de loin lorsque l'on augmente la quantité de données. Les jointures sont des opérations très voraces.
Pour les bases normalisées la durée semble plus ou moins corrélée à la taille de la table de jointure.
Prenons comme exemple la requête 1 :
- 50000 entrées → 874ms
- 500000 entrées → 9143ms (x10 par rapport à ci-dessus)
- 250000 entrées → 4212ms (÷2 par rapport à ci-dessus)
Les valeurs sont similaires pour la requête 2. Ainsi, la durée devrait évoluer linéairement par rapport à la quantité de données. Ce n'est pas un phénomène que l'on peut observer avec la forme dénormalisée, qui semble, mieux supporter l'augmentation de la quantité de données.
De plus, on peut observer quelque chose d'intéressant sur la partie dénormalisée. La requête 2 est plus performante que la requête 1. Autrement dit, requêter sur la table qui ne porte pas le tableau d'identifiant est plus performant. Ce qui veut dire que l'on a intérêt à faire porter le tableau d'identifiants à la table sur laquelle on ne veut pas faire de traitement complexe. Dans mon exemple si j'ai besoin de charger plus souvent les données relatives au bar, j'aurais tout intérêt à faire porter un bars_ids à ma table wines, plutôt que de conserver le wines_ids.
Taille des tables
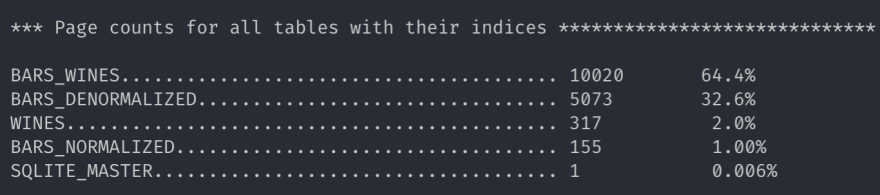
Ces statistiques sont fournies par l'outil sqlite3_analyzer.
La version table des bars en version dénormalisée est environ deux fois plus légère que la version normalisée comprenant les tables bars_normalized et bars_wines.
La dénormalisation en plus d'un gain de performances en lecture permet d'alléger la taille totale de notre base ! Qui l'eût cru ?
Conclusion
La dénormalisation est assurément une bonne solution pour gagner en performance de lecture. Cependant, il faut être vigilant sur les opérations d'écritures. Notamment, lors d'une suppression, on ne pourra pas profiter des suppressions en cascades offertes par les bases relationnelles.
À travers cet article, je voulais aussi montrer que la dénormalisation n'est pas un concept exclusif aux bases NoSQL. D'après les recherches rapides que j'ai pu effectuées, MySQL/MariaDB et PostreSQL supportent aussi la manipulation de JSON. Je ne jette pas le discredit sur les bases NoSQL, elles peuvent être plus adaptées que les bases relationnelles dans certains cas, Redis et ElasticSearch sont de parfaits exemples. Mais il n'est pas nécessaire de mettre de côté les solutions éprouvées.
Merci de m'avoir lu.
Liens
- https://www.sqlitetutorial.net
- https://stackoverflow.com/questions/49451777/sqlite-append-a-new-element-to-an-existing-array
Le mot de la fin
Merci à Jérémy Merle et Marvin Frachet pour la relecture.
Quand à Val, l'autre Jérem et Clapette 🖕😉

Top comments (7)
Bonjour,
C'est avec joie que je me branche sur la toile ce matin et découvre votre nouvel article.
Etant moi même passionné par le Structured Query Language (Oui, je préfère appeler les choses par leur nom plutôt que d'utiliser des acronymes à tir larigot comme un bon gros fdp de ses morts.)
J'ai commencé à lire votre article, sourire au lèvres.
Cependant, après quelques lignes, je me suis rendu compte de l'ignorance gargantuesque dont vous faites preuve !
Mon cher, la dé-normalisation est une technique barbare sortie des cerveaux saugrenus de ces enculés de merde qui ont inventé le NoSQL. Oui, je le cris haut et fort, le NoSQL c'est de la merde et ses utilisateurs sont de véritables pouffiasses !
Je sais bien que vous être une sous race en SQL, je le vois à la qualité de vos jointures. Mais bon sang, ne passez pas du mauvais côté de la requête, par pitié...
Votre pitoyable graphe de performances n'a pas de valeur à mes yeux. Le temps étant relatif, on en reparlera quand il faudra porter quelque chose.
Votre article est aussi insupportable qu'un rassemblement de tafioles sur des chars technos. Ressaisissez vous Monsieur, car, contrairement à vous, j'ai beaucoup d'amis, qui n'hésitent pas à se déplacer en groupe avec des battes de baseball (et ils ne jouent pas au baseball, croyez moi).
C'est bien beau de jouer le keyboard warior, mais mon petit pote, je vais venir t'enculer tu vas moins rigoler.
Je rejoins Jeremyl Martin, si vous voulez porter de tels propos, habillez vous d'une burka, qu'on sache que vous êtes un ennemi de la nation.
Bon rétablissement, Maxime.
Vous faites un amalgame pernicieux entre burka et ennemi de la nation. Je transmets de ce pas votre commentaire aux autorités compétentes qui se chargeront de
vous suicider de trois balles dans le dostraiter votre dossier comme il se doit.Alala qu'est-ce qu'on se marre ici ! 😄
Bonjour Maxime, j'ai lu attentivement votre article et deux choses ont retenues mon attention.
Premièrement vous ne savez pas faire du sql, c'est flagrant. Mais vous véhiculez surtout un message dangereux visant à faire régresser toutes les conventions sur le SQL (dans cet exemple la 3ème forme normale).
Je ne vois qu'une possibilité, vous êtes musulman et surtout terroriste. Vous n'aimez pas le SQL et souhaitez détruire toutes les bases solides établies depuis des décennies.
Je ne vous aime pas Maxime, je vous hais.
Le cours est cependant rédigé dans un jargon technique impressionnant et étant chef de projet sans aucun background technique je souhaiterai vous contacter pour une offre de poste B2C chez le client final.
Très bonne journée baltringue
PS : blabla c pa du sql c du noSQL NTM
Merci pour vos retours construits et toujours plein de sagesse.
Cependant vous mentionnez deux choses qui ont retenues votre attention, et vous n'en mentionnez qu'une seule.
Il s'agirait d'apprendre à compter, il s'agirait d'apprendre à compter
Concernant l'offre B2C, go inbox.
Pensez à boire de la tizane
Allez, la bise
Un bonheur de lire tant de conneries à la lettre. Vous êtes parmi les rares à pouvoir faire une erreur d'orthographe sur une lettre, oui une lettre.
Il semblerait que vous n'ayez jamais codé dans votre vie vu l'horreur écrite dans cet article. En cliquant sur ce titre, bien que putaclic, très attirant, je me disais pouvoir apprendre quelque chose pour une fois mais je me suis trompé. Deux solutions s'offrent à moi, soit je suis bien trop intelligent, soit les insouciantes erreurs sus-dites dans cet article sont bien plus bas niveau que mon propre niveau.
Au plaisir de vous relire,
amoureusement
Votre sottise n'a d'égale que votre couardise, merci de bien vouloir clore votre orifice buccal ad vita eternam.