What? A programming language coding in a grid?
Yes, you read that right, SPL (Structured Process Language) is a programming language that codes in a grid, and specially used for processing structured data.
We know that almost all programming languages write code as text, so what does SPL code look like, and what is the difference between the grid-style code and the text-style code? Let's take a look at the programming environment of SPL first.
Code in a grid
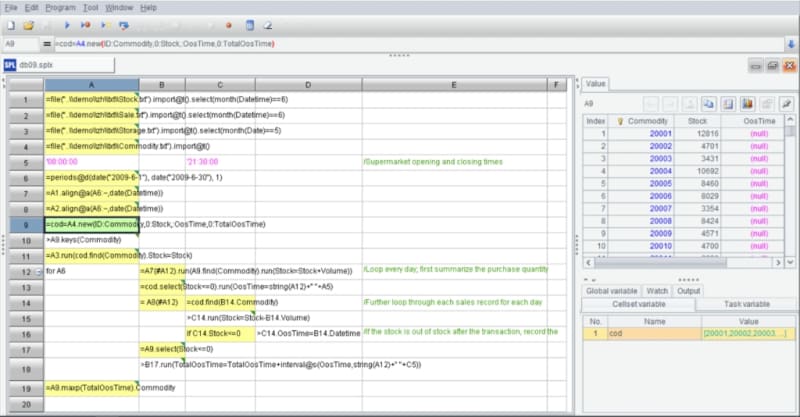
The middle part is the grid-style code of SPL.
What are the benefits of writing code in a grid?
When programming, we always need to use intermediate variables and name them. However, when we program in SPL, naming variables is often unnecessary. SPL allows us to reference the name of previous cell directly in subsequent steps and get the calculation result of the cell (such as A1), for example, =A2.align@a(A6:~,date(Datetime)). In this way, racking our brains to define variables is avoided (as the variable has to be given a meaningful name, which is annoying); Of course, SPL also supports defining variables, yet there is no need to define the type of variable, and hence we can name a variable and use it directly, for example: =cod=A4.new(ID:Commodity,0:Stock,:OosTime,0:TotalOosTime). In addition, we can temporarily define a variable in expression, for example: = A1.group@o(a+=if(x,1,0)).
You may worry that a problem will occur when using cell name as variable name, that is, cell’s name (position) will change after inserting or deleting a row and column, and the original name will be referenced. Don't worry, this problem is already solved in SPL’s IDE, and the cell name will automatically change when inserting or deleting a row. For example, when inserting a row, the name of cells (red underlined names) changes accordingly, is it convenient?
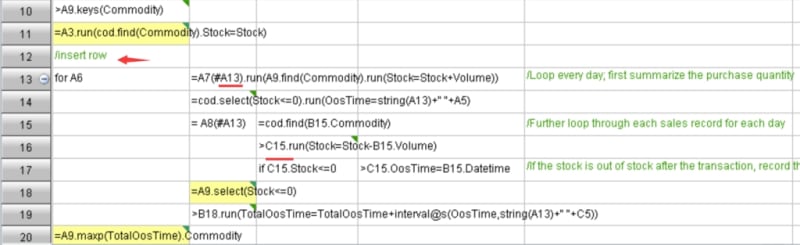
The grid-style code will make us feel that the code is very neat. Because code is written in cells, it is naturally aligned. For instance, the indentation of cells indicates it is a code block (the for loop statement from A12 to A18), and any modifier is not needed, and thus it looks very neat and intuitive. Moreover, when the code in a cell is long due to the processing of a complicated task, the code occupies one cell only and will not affect the structure of entire code (it will not affect the read of the codes on the right and below since the code in a certain cell will not exceed the boundary of cell even though it is too long). In contrast, the text-style code doesn’t have this advantage because it has to display entire code.
Besides, it should be noted that there is a collapse button at the row where the for loop is located, this button can collapse entire code block. Although such button is available in the IDE of multiple text-style programming languages, it will make entire code more neat and easier to read when it is used in SPL.

Now let's look at the debug function. In the IDE of SPL, the upper toolbar provides multiple execution/debugging buttons, including run, debug, run to cursor, step in, as well as other buttons like set breakpoints, calculate current cell, which can fully meet the needs of editing and debugging program. It executes one cell in each step, the breakpoint of code is very clear. In contrast, the execution/debugging of text-style code is different, there may be multiple actions in one line, which are not easy to distinguish, and breakpoint is not easy to be located when some statements are too long and have to be divided into multiple lines.

Attention should also be paid to the result panel on the right. Because SPL adopts grid-style programming, the result of each step (cell) is retained after execution/debugging, which allows the programmer to view the calculation result of that step (cell) in real time by clicking on a cell, so whether the calculation is correct or not is clear, and the convenience of debugging is further enhanced as a result of eliminating the need to export result manually and viewing the result of each step in real time.
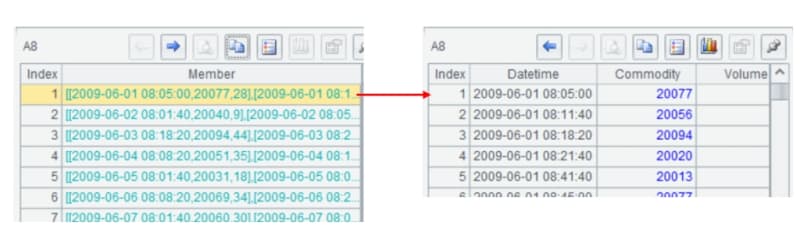
Multi-layer result set
The benefits don't stop at grid-style programming
Writing code in cells will make programming convenient, for example, it’s easier to edit or debug. However, it will not simplify writing each statement. Let's take a look at SPL syntax itself.
When processing data, especially complex scenario, we will definitely use loop and branch, which are the relatively basic functionalities of a programming language. Of course, SPL provides such functionalities. In addition, SPL provides many features, such as option syntax, multi-layer parameters, and advanced Lambda syntax.
Function option
Each programming language has a large number of built-in library functions, and the richer the library functions, the more convenient it is for us to implement functionality. Functions are distinguished by different name or parameter (and parameter type). However, when it is impossible to distinguish even by parameter type sometimes, we need to explicitly add an option parameter to tell the compiler or interpreter what we want to do. For example, processing files in Java will involve multiple OpenOptions, when we want to create a file that does not exist, the code is:
Files.write(path, DUMMY_TEXT.getBytes(),StandardOpenOption.CREATE_NEW);
When we want to open an existing file and create a new one that does not exist, the code is:
Files.write(path, DUMMY_TEXT.getBytes(),StandardOpenOption.CREATE);
When we want to append data to a file and ensure that the data will not lose in the case of system crash, the code is:
Files.write(path,ANOTHER_DUMMY_TEXT.getBytes(),StandardOpenOption.APPEND, StandardOpenOption.WRITE, StandardOpenOption.SYNC)
As we can see from the above codes that if we want to implement different functionalities with the same function, we need to select different options. Usually, an option is regarded as a parameter, but this will result in complexity in use, and often makes us confused about the real purpose of these parameters, and for some functions with unfixed number of parameters, there is no way to represent option with parameter.
SPL provides very unique function option, which allow the functions with similar functionality to share one function name, and the difference between functions is distinguished with function option, thus really playing the role of function option. In terms of form of expression, it tends to be a two-layer classification, making both remembering and using very convenient. For example, the pos function is used to search for the position of substring in a parent string, if we want to search from back to front, we can use the option @z:
pos@z("abcdeffdef","def")
To perform a case-insensitive search, we can use the option @c:
pos@c("abcdef","Def")
The two options can also be used in combination:
pos@zc("abcdeffdef","Def")
With the function option, we only need to be familiar with fewer functions. When we use the same function with different functionalities, we just need to find a corresponding option, it is equivalent that SPL classifies the functions into layers, which makes it more convenient to search and utilize.
Cascaded parameter
The parameters of some functions are very complex and may be divided into multiple layers. In view of this situation, conventional programming languages do not have a special syntax solution, and can only generate multi-layer structured data object and then pass them in, which is very troublesome. For example, the following code is to perform a join operation in Java (inner join between Orders table and Employee table):
Map<Integer, Employee> EIds = Employees.collect(Collectors.toMap(Employee::EId, Function.identity()));
record OrderRelation(int OrderID, String Client, Employee SellerId, double Amount, Date OrderDate){}
Stream<OrderRelation> ORS=Orders.map(r -> {
Employee e=EIds.get(r.SellerId);
OrderRelation or=new OrderRelation(r.OrderID,r.Client,e,r.Amount,r.OrderDate);
return or;
}).filter(e->e.SellerId!=null);
It can be seen that it needs to pass a multi-layer (segment) parameter to Map to perform association, which is hard to read, let alone write. If we perform a little more calculations (other calculations are often involved after association), for example, group the Employee.Dept and sum the Orders.Amount, the code is:
Map<String,DoubleSummaryStatistics>c=ORS.collect(Collectors.groupingBy(r->r.SellerId.Dept,Collectors. .summarizingDouble(r->r.Amount)));
for(String dept:c.keySet()){
DoubleSummaryStatistics r =c.get(dept);
System.out.println("group(dept):"+dept+" sum(Amount):"+r.getSum());
}
There is no need to explain more about the complexity of such function because programmers have deep experience. In contrast, SQL is more intuitive and simpler.
select Dept,sum(Amount) from Orders r inner join Employee e on r.SellerId=e. SellerId group by Dept
SQL employs some keywords (from, join, etc.) to divide the calculation into several parts, which can be understood as a multi-layer parameter. Such parameters are just disguised as English for easy reading. However, this way is much less universal, because it needs to select special keywords for each statement, resulting in inconsistent statement structure.
Instead of using keyword to separate parameters like SQL, and nesting multiple layers like Java, SPL creatively invents cascaded parameter. SPL specifies that three layers of parameters are supported, and they are separated by semicolon, comma, and colon respectively. Semicolon represents the first level, and the parameters separated by semicolon form a group. If there is another layer of parameter in this group, separate them with comma, and if there is third-layer parameter in this group, separate them with colon. To implement the above association calculation in SPL, the code is:
join(Orders:o,SellerId ; Employees:e,EId).groups(e.Dept;sum(o.Amount))
This code is simple and straightforward, and has no nested layer and inconsistent statement structure. Practice shows that three layers can basically meet requirement, we hardly meet a relationship of parameters which cannot be clearly described in three layers.
Advanced Lambda syntax
We know that Lambda syntax can simplify coding, some programming languages have begun to support this syntax. For example, counting the number of empty strings in Java8 or higher version can be coded like this:
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
long count = strings.stream().filter(string -> string.isEmpty()).count();
This “(parameter)-> function body” Lambda expression can simplify the definition of anonymous function and is easy to use.
Nevertheless, for some slightly complex calculations, the code will be longer. For example, perform a grouping and aggregating calculation on two fields:
Calendar cal=Calendar.getInstance();
Map<Object, DoubleSummaryStatistics> c=Orders.collect(Collectors.groupingBy(
r->{
cal.setTime(r.OrderDate);
return cal.get(Calendar.YEAR)+"_"+r.SellerId;
},
Collectors.summarizingDouble(r->{
return r.Amount;
})
)
);
for(Object sellerid:c.keySet()){
DoubleSummaryStatistics r =c.get(sellerid);
String year_sellerid[]=((String)sellerid).split("_");
System.out.println("group is (year):"+year_sellerid[0\]+"\t(sellerid):"+year_sellerid[1]+"\t sum is:"+r.getSum()+"\t count is:"+r.getCount());
}
In this code, any field name is preceded by a table name, i.e., “table name.field name”, and the table name cannot be omitted. The syntax of anonymous function is complex, and the complexity increases rapidly as the amount of code increases. Two anonymous functions will form a nested code, which is harder to understand. Implementing a grouping and aggregating calculation will involve multiple functions and libraries, including groupingBy, collect, Collectors, summarizingDouble, DoubleSummaryStatistics, etc., the complexity is very high.
SPL also supports Lambda syntax, and the support degree is more thoroughly than other languages like Java. Now let's perform the above calculations in SPL.
Count the number of empty strings:
=["abc", "", "bc", "efg", "abcd","", "jkl"].count(~=="")
SPL directly simplifies A.(x).count() to A.count(x), which is more convenient. However, this code doesn't seem to differ much from Java code. Let's see another calculation:
=Orders.groups(year(OrderDate),Client; sum(Amount),count(1))
See the difference? There are many advantages when performing grouping and aggregating calculation in SPL: i)it doesn’t need to define data structure in advance; ii) there is no redundant functions in the whole code; iii) the use of sum and count is simple and easy to understand, it is even difficult to perceive it is a nested anonymous function.
Let's look at another example:
There is a set in which a company's sales from January to December are stored. Based on this set, we can do the following calculations:
A
1 =[820,459,636,639,873,839,139,334,242,145,603,932]
2 =A1.select(#%2==0)
3 =A1.(if(#>1,~-~[-1],0))
A2: filter out the data of even-numbered months; A3: calculate the growth value of monthly sales.
Here we use # and [-1], the former represents the current sequence number, and the latter means referencing the previous member. Similarly, if we want to compare the current member with next member, we can use [1]. The symbol #, [x], together with ~ (current member) are what make SPL unique in enhancing Lambda syntax. With these symbols, any calculation can be implemented without adding other parameter definition, and the description ability becomes stronger, and writing and understanding are easier.
Function option, multi-layer parameters and advanced Lambda syntax are another aspect that sets SPL apart.
Structured data computing ability comparable to SQL
SPL's grid-style coding and code features (function syntax, multi-layer parameter, Lambda syntax) make SPL look interesting. However, the invention of SPL is not for attracting attention but processing data efficiently. For this purpose, SPL provides a specialized structured data object: table sequence (record) and provides rich computing library based on the table sequence. In addition, SPL supports dynamic data structure, which makes SPL have the same complete structured data processing ability as SQL.
In contrast, Java, as a compiled language, is very cumbersome in data calculation due to the lack of necessary structured data object. Moreover, since Java doesn’t support dynamic data structure, the data cannot be generated dynamically during computation and has to be defined in advance, this problem was not well solved even after the emergence of Stream. In short, these shortcomings are all due to the fact that the base of Java doesn't provide sufficient support.
SPL provides rich calculation functions, allowing us to calculate structured data conveniently. The functions include but not limited to:
=Orders.sort(Amount) // sort
=Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // filter
=Orders.groups(Client; sum(Amount)) // group
=Orders.id(Client) // distinct
=join(Orders:o,SellerId ; Employees:e,EId) // join
Now let’s see a double-field sorting example:
A
1 =file("Orders.txt").import@t()
2 =A1.sort(-Client, Amount)
In this code, @t means that the first row is read as field name, and subsequent rows are calculated directly with the field name rather than data object; -Client means reverse order.
The code can also be written in one line on the premise of not affecting reading, which will make code shorter.
=file("Orders.txt").import@t().sort(-Client, Amount)
Let's recall the example in the previous section. When Java performs a grouping and aggregating calculation on two fields, it needs to write a long two-layer nested code, this will increase the cost of learning and use. For the same calculation, coding in SPL is the same as coding in SQL, whether it is to group one field or multiple fields:
=Orders.groups(year(OrderDate),Client; sum(Amount))
Similarly, for inner join calculation (then aggregation), coding in SPL is much simpler than other high-level languages:
=join(Orders:o,SellerId ; Employees:e,EId).groups(e.Dept; sum(o.Amount))
Similar to SQL, SPL can change the association type with little modifications, and there is no need to modify other codes. For example, join@1 means left join, and join@f means full join.
Rich data objects and libraries make SPL not only have the data processing ability comparable to SQL, but inherit some good features of high-level languages (such as procedural computing), thus making it easy for SPL to process data.
Computing abilities that surpass SQL
From what we've discussed above (interesting grid-style programming, features like option syntax, and complete structured data objects and library), we know that SPL has the structured data processing ability comparable to SQL, allowing programmers to perform a lot of structured data processing and computation tasks in the absence of database.
Then, does SPL merely play the role of “SQL” without database?
Not really! SPL's ability is more than that. In fact, SPL has many advantages over SQL in terms of structured data computation.
In practice, we often meet some scenarios that are difficult to code in SQL, and multiply-level nested SQL code with over a thousand lines are very common. For such scenarios, not only is it difficult to code in SQL, but it is also not easy to modify and maintain. Such SQL code is long and troublesome.
Why does this happen?
This is due to the fact that SQL doesn’t support certain features well, or even doesn’t support at all. Let’s look at a few examples to compare SPL and SQL.
Ordered computing
Calculate the maximum number of trading days that a stock keeps rising based on stock transaction record table.
Coding in SQL:
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
This code nests 3 layers. Firstly, mark each record with a rising or falling flag through window function (mark 0 if the price rises, otherwise mark 1), and then accumulate by date to get the intervals with same rising flag (the accumulated value will change if the price doesn’t rise), and finally group by flag, count and find out the maximum value, which is the result we want.
How do you feel about this code? Do you think it is tortuous? Does it take a while to understand? In fact, this is not a very complicated task, but even so, it is so difficult to code/read. Why does this happen? The is due to the fact that SQL’s set is unordered, and the members of set cannot be accessed by sequence number (or relative position). In addition, SQL doesn’t provide ordered grouping operation. Although some databases support window function and support order-related operations to a certain extent, it is far from enough (such as this example).
Actually, this task can be implemented in a simpler way: sort by date; compare the price of the day with that of the previous day (order-related operation), and add 1 if the price rises, otherwise reset the current value as 0; find the maximum value.
SPL directly supports ordered data set, and naturally supports order-related operations, allowing us to code according to natural thinking:
A
1 =stock.sort(tradeDate)
2 =0
3 =A1.max(A2=if(closePrice>closePrice[-1],A2+1,0))
Backed by ordered operation, and procedural computing (the advantage of Java), it is very easy for SPL to express, and the code is easy to write and understand.
Even we follow the thinking of above SQL solution to code in SPL, it will be easier.
stock.sort(trade_date).group@i(close_price<close_price [-1]).max(~.len())
This code still makes use of the characteristic of orderliness. When a record meets the condition (stock price doesn't rise), a new group will be generated, and each rising interval will be put into a separate group. Finally, we only need to calculate the number of members of the group with maximum members. Although the thinking is the same as that of SQL, the code is much simpler.
Understanding of grouping
List the last login interval of each user based on a user login record table:
Coding in SQL:
WITH TT AS
(SELECT RANK() OVER(PARTITION BY uid ORDER BY logtime DESC) rk, T.* FROM t_loginT)
SELECT uid,(SELECT TT.logtime FROM TT where TT.uid=TTT.uid and TT.rk=1)
-(SELET TT.logtim FROM TT WHERE TT.uid=TTT.uid and TT.rk=2) interval
FROM t_login TTT GROUP BY uid
To calculate the interval, the last two login records of user are required, which is essentially an in-group TopN operation. However, SQL forces aggregation after grouping, so it needs to adopt a self-association approach to implement the calculation indirectly.
Coding in SPL:
A
1 =t_login.groups(uid;top(2,-logtime)) Last 2 login records
2 =A1.new(uid,#2(1).logtime-#2(2).logtime:interval) Calculate interval
SPL has a new understanding on aggregation operation. In addition to common single value like SUM, COUNT, MAX and MIN, the aggregation result can be a set. For example, SPL regards the common TOPN calculation as an aggregation calculation like SUM and COUNT, which can be performed either on a whole set or a grouped subset (such as this example).
In contrast, SQL does not regard TOPN operation as aggregation. For the TOPN operation on a whole set, SQL can only implement by taking the first N items after sorting the outputted result set, while for the TOPN operation on a grouped subset, it is hard for SOL to implement unless turning to a roundabout way to make up sequence numbers. Since SPL regards TOPN as aggregation, it is easy to implement some calculations (such as this example) after making use of the characteristic of ordered data, and this approach can also avoid sorting all data in practice, thereby achieving higher performance.
Furthermore, the grouping of SPL can not only be followed by aggregation, but retain the grouping result (grouped subset), i.e., the set of sets, so that the operation between grouped members can be performed.
Compared with SPL, SQL does not have explicit set data type, and cannot return the data types such as set of sets. Since SQL cannot implement independent grouping, grouping and aggregating have to be bound as a whole.
From the above two examples, we can see the advantages of SPL in ordered and grouping computations. In fact, many of SPL's features are built on the deep understanding of structured data processing. Specifically, the discreteness allows us to separate the records that from the data table and compute them independently and repeatedly; the universal set supports the set composed of any data, and participating in computation; the join operation distinguishes three different types of joins, allowing us to choose a join operation according to actual situation; the feature of supporting cursor enables SPL to have the ability to process big data... By means of these features, it will be easier and more efficient for us to process data.
For more information, refer to: SPL Operations for Beginners
Unexpectedly, SPL can also serve as a data warehouse
Supporting both in-memory computing and external storage computing means SPL can also be used to process big data, and SPL is higher in performance compared with traditional technologies. SPL provides dozens of high-performance algorithms with “lower complexity” to ensure computing performance, including:
In-memory computing: binary search, sequence number positioning, position index, hash index, multi-layer sequence number positioning...
External storage search: binary search, hash index, sorting index, index-with-values, full-text retrieval...
Traversal computing: delayed cursor, multipurpose traversal, parallel multi-cursor, ordered grouping and aggregating, sequence number grouping...
Foreign key association: foreign key addressization, foreign key sequence-numberization, index reuse, aligned sequence, one-side partitioning...
Merge and join: ordered merging, merge by segment, association positioning, attached table...
Multidimensional analysis: partial pre-aggregation, time period pre-aggregation, redundant sorting, boolean dimension sequence, tag bit dimension...
Cluster computing: cluster multi-zone composite table, duplicate dimension table, segmented dimension table, redundancy-pattern fault tolerance and spare-wheel-pattern fault tolerance, load balancing...
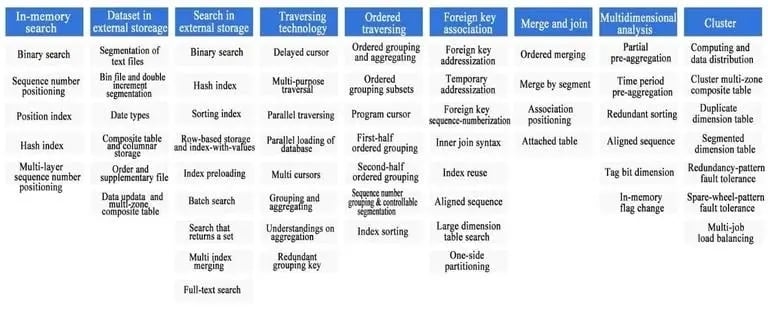
As we can see that SPL provides so many algorithms (some of which are pioneered in the industry), and also provide corresponding guarantee mechanism for different computing scenarios. As a programming language, SPL provides not only the abilities that are unique to database but other abilities, which can fully guarantee computing performance.
In addition to these algorithms (functions), storage needs to be mentioned. Some high-performance algorithms work only after the data is stored as a specified form. For example, the ordered merge and one-side partitioning algorithms mentioned above can be performed only after the data is stored in order. In order to ensure computing performance, SPL designs a specialized binary file storage. By means of this storage, and by adopting the storage mechanisms such as code compression, columnar storage and parallel segmentation, and utilizing the approaches like sorting and index, the effectiveness of high-performance algorithms is maximized, thus achieving higher computing performance.
High-performance algorithms and specialized storage make SPL have all key abilities of data warehouse, thereby making it easy to replace traditional relational data warehouses and big data platforms like Hadoop at lower cost and higher efficiency.
In practice, when used as a data warehouse, SPL does show different performance compared with traditional solutions. For example, in an e-commerce funnel analysis scenario, SPL is nearly 20 times faster than Snowflake even if running on a server with lower configuration; in a computing scenario of NAOC on clustering celestial bodies, the speed of SPL running on a single server is 2000 times faster than that of a cluster composed of a certain top distributed database. There are many similar scenarios, basically, SPL can speed up several times to dozens of times, showing very outstanding performance.
In summary, SPL, as a specialized data processing language, adopts very unconventional grid-style programming, which brings convenience in many aspects such as format and debugging (of course, those who are used to text-style programming need to adapt to this change). Moreover, in terms of syntax, SPL incorporates some new features such as option, multi-layer parameters and Lambda syntax, making SPL look interesting. However, these features actually serve data computing, which stem from SPL's deep understanding of structured data computing (deeper and more complete than SQL). Only with the deep understanding can these interesting features be developed, and only with these features can data be processed more simply, conveniently and quickly. Simpler in coding and faster in running is what SPL aims to achieve, and in the process, the application framework can also be improved (not detailed here).
In short, SPL is a programming language that is worth trying.
Origin: https://blog.scudata.com/a-programming-language-coding-in-a-grid/
SPL Source Code: https://blog.scudata.com/a-programming-language-coding-in-a-grid/

Top comments (0)