

Hi readers,
In the previous post, I wrote about gaining the knowledge from the Text which is available from many sources. In this post, I will be writing about Topic Mining.
Introduction
Topic Mining can be described as finding words from the group of words which can best describe the group.
Textual Data in raw form is not associated with any context. A human can easily identify the context or topic for an article by reading the article and categorise it in one or other category like politics, sports, economics, crime etc.
One of the factors any human will consider while classifying the text into one of the topics is the knowledge that how a word is associated with a topic e.g
- India won Over Sri Lanka in the test match.
- World Badminton Championships: When and where to watch Kidambi Srikanth’s first round, live TV coverage, time in IST, live streaming
Here we may not find word sports explicitly in the sentences but the words marked in bold are associated with sports.
Topic modelling can be broadly categorised into two type
- Rule-Based topic modelling
- Unsupervised topic modelling
Rule-Based Topic Modelling
As the name suggests rule-based topic modelling depends on the rules which can be used to associate a given text with some topic.
In the simplest rule-based approach, we can just search for some words in the text and associate it with a topic e.g finding the word sports for associating the topic with sports, finding travelling for associating with topic travel
This approach can be extended and a topic can be represented as a set of words with some given probabilities e.g For the category sports we can have a set of words with some weight assigned to each word.
Topic : Sports{"sports":0.4,"cricket":0.1,"badminton":0.1 ,"traveling":0.05 .....}
Topic : Travel{"travel":0.4, "hiking":0.1,"train":0.05,"traveling":0.20 .......}
Notice the word "travelling", it occurs in both the Topics but has different weight.
If we have a sentence "Badminton players are travelling to UK for the tournament", by the simple approach of finding the words for the topic then this sentence will go under the topic Travel. The second approach improves the prediction by checking the probabilities and weight for different words, in this case, "Badminton" and "travelling" and improves the result by predicting the more accurate result that is Sports.
The main disadvantage of the Rule-Based approach is that all the topics have to be known in the beginning and probabilities have to be determined and examined. This rules out the possibility of finding some new topic in the text corpus.
Unsupervised Topic Modelling

The topic of a text sentence largely depends on the words used in the sentence and this property is exploited in unsupervised topic modelling technique to extract topics from the sentences.
It largely relies on the Bayesian Inference Model.
Bayesian Inference Model
It is a method by which we can calculate the probability of occurrence of some event-based on some common sense assumptions and the outcomes of previous related events.
It also allows us to use new observations to improve the model, by going through many iterations where a prior probability is updated with the observational evidence in order to produce a new and improved posterior probability
Some of the techniques for Unsupervised Topic Modelling are:
- TF-IDF
- Latent Semantic Indexing
- Latent Dirichlet Allocation
I will not discuss the techniques in detail rather will focus on the implementation of these in python.
All the approaches use the vector space representation of the documents. In vector space model a document is represented by a document-term matrix.
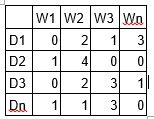
Here D1,D2,D3...Dn are different documents and W1,W2,W3....Wn are the words that belong to our dictionary(all unique words in the corpus). DxWy gives the number of time the word has occurred in the document.
#importing corpora from gensim for creating dictionary from gensim import corpora #some raw documents .These documents can be stored in a file and read from the file documents = ["Two analysts have provided estimates for Tower Semiconductor's earnings. The stock of Tower Semiconductor Ltd. (USA) (NASDAQ:TSEM) has \"Buy\" rating given on Friday, June 9 by Needham. The company's stock had a trading volume of 573,163 shares.", "More news for Tower Semiconductor Ltd. (USA) (NASDAQ:TSEM) were recently published by: Benzinga.com, which released: “15 Biggest Mid-Day Gainers For Monday” on August 14, 2017.", "Tower Semiconductor Ltd now has $2.33 billion valuation. The stock decreased 1.61% or $0.41 during the last trading session, reaching $25.06.", "The investment company owned 74,300 stocks of the industrial products firms shares after disposing 5,700 shares through out the quarter.", "Tower Semiconductor Ltd now has $2.37B valuation. The stock rose 0.16% or $0.04 reaching $25.1 per share. About 115,031 shares traded.", "Needle moving action has been spotted in Steven Madden Ltd (SHOO) as shares are moving today on volatility -2.00% or -0.85 from the open.", "Shares of Steven Madden Ltd (SHOO) have seen the needle move -1.20% or -0.50 in the most recent session. The NASDAQ listed company saw a recent bid of 41.10 on 82437 volume.", "Shares of Steven Madden Ltd (SHOO) is moving on volatility today -1.37% or -0.57 from the open. The NASDAQ listed company saw a recent bid of 41.03 on 279437 volume.", "Shares of Steven Madden, Ltd. (NASDAQ:SHOO) are on a recovery track as they have regained 28.79% since bottoming out at $32.3 on Oct. 26, 2016."] ''' Text Preprocessiing before calculation vectors ''' # remove common words(stop words) and tokenize stoplist = set('for a of the and to in its by his has have on were was which or as they since'.split()) texts = [[word for word in document.lower().split() if word not in stoplist] for document in documents] # remove words that appear only once in the corpus. from collections import defaultdict frequency = defaultdict(int) for text in texts: for token in text: frequency[token] += 1 texts = [[token for token in text if frequency[token] > 1] for text in texts] from pprint import pprint # pretty-printer pprint(texts) ''' dictionary is collection of all the words that apprear in our corpus ''' #creating dictionary from the corpus which represents each word in the text corpus as a unique integer dictionary = corpora.Dictionary(texts) dictionary.save('/tmp/deerwester.dict') # store the dictionary, for future reference #saved dictionary can be loaded from the memory for future references.Saves time for recreation of dictionary #to print the token id of the words print(dictionary.token2id) ''' We can convert any document to vector format by just calling the doc2bow() method of dictionary object. document="hello this is a good morning" Input=['hello','this','is','a','good','morning'] preprocessing can be done on the document before passing to doc2bow() ''' corpus = [dictionary.doc2bow(text) for text in texts] print corpus ''' creating vector space representation for a single document str="human interaction interface interface" dictionary.doc2bow(text for text in str.split(' ')) ''' from gensim import corpora, models, similarities #convertig the vector space representation to tf-idf transformation tfidf = models.TfidfModel(corpus) list(tfidf[corpus]) #using LDA model for getting the topics lda= models.LdaModel(corpus, id2word=dictionary, num_topics=2) # initialize an LDA transformation corpus_lda= lda[corpus] # create a double wrapper over the original corpus: bow->tfidf->fold-in-lda print lda.print_topics(2) #print the topics #for classifying the text documents into topics #here I have used the old corpus on which it was trained ,one can also use new documents for doc in corpus_lda: print doc Output:[(0, u'0.069*"shares" + 0.062*"ltd" + 0.059*"steven" + 0.044*"madden" + 0.044*"tower" + 0.043*"moving" + 0.043*"recent" + 0.041*"stock" + 0.040*"(shoo)" + 0.036*"semiconductor"'),(1, u'0.077*"shares" + 0.066*"tower" + 0.056*"semiconductor" + 0.050*"stock" + 0.048*"company" + 0.046*"ltd" + 0.045*"ltd." + 0.043*"(usa)" + 0.038*"(nasdaq:tsem)" + 0.035*"trading"')]#the output gives the topics along with there probability distribution for different words
Parameters of LdaModel can be tweaked for result improvements.Also by just replacing LdaModel by LsiModel one can use LSI technique

Top comments (0)