

Hi Readers,
Recently I was going through some text analytics activities at work and learned some techniques for text analytics and mining.
In this series of posts, I will be sharing my experiences and learnings.
Introduction
Firstly the jargon Text Analysis and Text Mining are sub domains of the term Data Mining and are used interchangeably in most scenarios.
Broadly Text Analysis refers to,
Extracting information from textual data keeping the problem for which we want to get data in mind.
and Text Mining refers to,
the process of getting textual data.
Nowadays, a large quantity of data is produced by humans.Data is growing faster than ever before and by the year 2020, about 1.7 megabytes of new information will be created every second for every human being on the planet and one of the main components of this data will be textual data.
Some of the main sources of textual data are
- Blogs
- Articles
- Websites
- Comments
- Discussion Forums
- Reviews
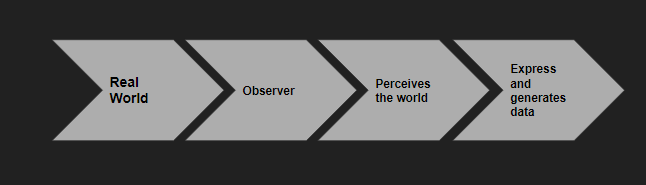
In the scenario described in the image above every observer may perceive the real world in a different manner and express accordingly e.g different persons may have a different opinion on some topic.
So, while analysing textual data this type of bias ness has to be kept in mind.
Type of information that can be extracted from the text and converted into actionable knowledge can be
- Mining content of data
- Mining knowledge about the language
- Mining knowledge about the observer
- Infer other real world variables
NLP
NLP stands for natural language processing, a subdomain of Machine Learning that deals with processing of natural language spoken by humans and make it understandable for a machine.
It is a fairly complex problem as understanding natural language involves common sense which machines lack. Many of the sentences spoken by humans involve common sense and are spoken in some context which derives the meaning of the sentence.E.g
- He is an apple of my eye.(Phrase)
- John is the star.(Movie star or celestial body)
Analyzing the Natural language can be broadly classified into 4 types of analysis
- Lexical Analysis-Identifying Parts of Speech, Word Associations, Topic Mining
- Syntactical Analysis-Connecting words and creating phrases and then connecting phrases
- Semantical Analysis-Extracting knowledge about the sentence
- Pragmatic Analysis-Getting the intent of the sentence
Lexical Analysis
By the definition lexical analysis means converting of a sequence of characters into the sequence of words with some defined meanings.
Definitions of words can be
- POS Tags(Nouns,Verbs,Adverbs etc)
- Word Associations(How two words are linked)
- Topic(Context of the Paragraph)
- Syntagmatic words
In this article, I will be writing about Word Associations which is the analysis of how different words are linked to each other. Look at the following sentences
- "Jack drives a car", "car" is associated to "drive"
- "I love cats"
- "I love dogs", In these sentences, the word cats is related to dogs as they can be used interchangeably to make a valid sentence
In the first sentence "Jack drives a car", the type of relationship between "car " and "drive" is called
Syntagmatic Relation.
Two words are called syntagmatically related if the probability of both the words occurring in the same sentence is high. E.g
- Bob eats food
- John drives a car
- He sits on a sofa
These types of relations are important to find the probability of a word occurring in a sentence based on another word which is present in the sentence.
This problem can be mathematically reduced to Predicting a random variable v, where v=1 if the word is present in the sentence or v-0 if the word is not present in the sentence.
The more random this variable is, the more difficult it is to predict the variable. For e.g probability of occurring the in a sentence when some other word has occurred in the sentence can be easily predicted as "the" is a pretty common word, on the other hand, probability of occurring of word "eat" in a sentence is low and it's difficult to predict the probability of its occurrence.
The randomness of a random variable can be measured by Entropy.
H(Xw)=∑-P(Xw=V)logP(Xw=V)
(vε{0,1})
X sub w is the probability that the word w is present in the sentence
H(Xw) is the entropy of the variable X sub w
P(Xw=V) is the probability that the variable exists(V=1) and vice-versa(V=0)
logP(Xw=V) is the natural log of the probability that a variable exists(V=1) and vice-versa (V=0)
"Higher the entropy more difficult it is to predict the syntagmatic relation"
Now that we know the concept of entropy and how it can be used to predict the existence of a word in a sentence, let's introduce one more concept called Conditional Entropy.
It is defined as the entropy of a word W when it is known that V has occurred in the sentence.
This helps to reduce the entropy which in turn reduces the randomness of the random variable.
Conditional Entropy can be defined as
H(Xmeat|Xeats =1)=-P(Xmeat=0 | Xeats =1)logP(Xmeat=0 | Xeats =1)
- P(Xmeat=1 | Xeats =1)logP(Xmeat=1 | Xeats =1)
This defines the probability of meat occurring when eats has already occurred.
Paradigmatic Relations
The other type of relationship that can be found between the words is the paradigmatic relation.Two words are said to be paradigmatically related if they can be replaced with each other and still make a valid sentence.E.g
- I love cats
- I love dogs
In the first sentence if "cats" is replaced with dogs it still makes a valid sentence, that means cats and dogs are paradigmatically related.
In order to find these type of relationships in the sentences we first need to find the Left Context, which means the words that appear left to the words and then we need to find the Right Context, which means the words that appear to the right of the sentences.
Once we have these context we can find the context similarities.Words with more context similarities are more paradigmatically related.This problem can be mathematically defined by representing each word in the context as a vector, where the value of vector is represented by the frequency of the occurrences of that word in the context
Now the two contexts can be represented as
d1=(x1,x2,x3,x4,........xn)
d1=c(wi,d1) / |d1|
c(wi,d1) is the count of word wi in d1 and,
|d1| is the number of words in d1
d2=(x1,x2,x3,x4,........xn)
d2=c(wi,d2) / |d2|
c(wi,d2) is the count of word wi in d2 and,
|d2| is the number of words in d2
And context similarity can be calculated as
Sim(d1,d2)=d1.d2
Sim(d1,d2)=x1y1+x2y2+x3y3+......................................+xnyn
Sim(d1,d2)=ðšºxiyi where i=0 to n
The similarity is the probability that a randomly picked word from d1 and d2 are identical.
Soon will be adding some links for the programmatical model for these relation mining and in the next series will be writing about the Topic Mining.
Stay Tuned......

Top comments (0)