
The article will be divided into different sections as follows:
- Introduction to Machine Learning
- Types of Solutions
- Classification using Naive Bayes
A brief about Machine Learning
According to the definition by Wikipedia, Machine learning is the subfield of computer science that, according to Arthur Samuel in 1959, gives "computers the ability to learn without being explicitly programmed." Machine Learning defines a set of problems that have to be evolved through the data by implying some algorithm. One factor that has to be kept in mind while defining a solution through ML is accuracy. Accuracy is very critical in case you are developing a solution in medical domain(cancer detection).There should be a threshold set for every solution which can be based on risk %age that is acceptable.A useful cheatsheet from Microsoft's site to sum up the use of different ML algorithms for the different type of problems.
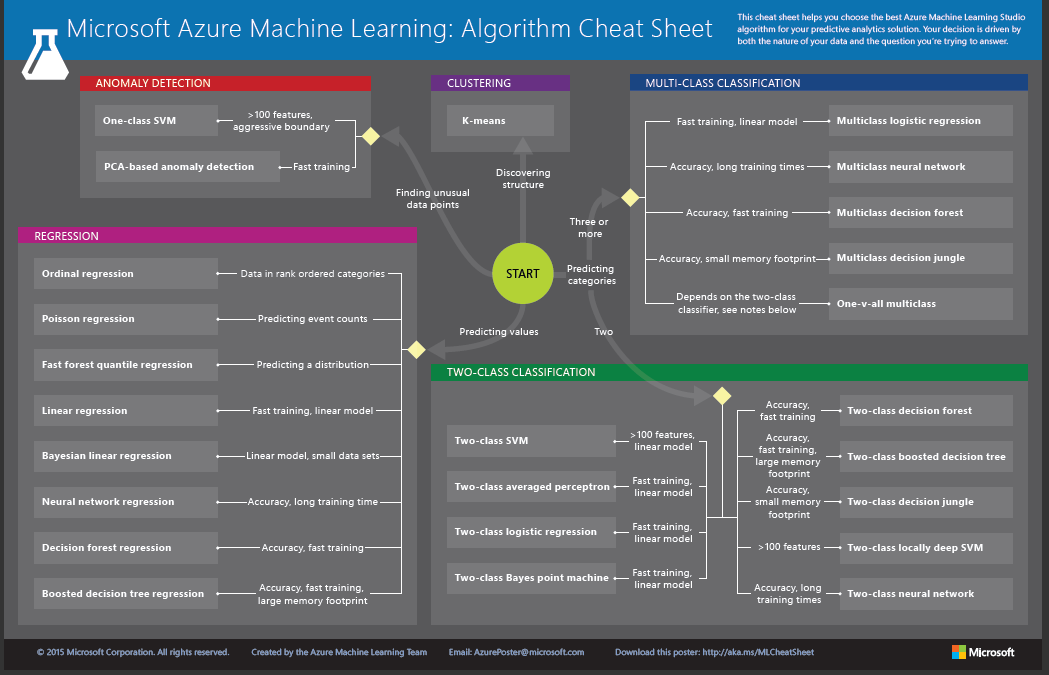
Types of solution
Machine Learning solutions can be broadly classified into three types
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning is a category in which a machine is given training on some labelled data and is informed about the problem that is to be solved.The learnt model then uses its knowledge to solve the future similar problems.In this type of learner, a major requirement is the availability of labelled data.An Example of this kind of problems can be an object identification problem.
First, a model is trained and told about the different types of objects, and then it is asked to identify the objects.
Unsupervised Learning, on the other hand, is a category in which a learner is not provided with any input i.e labelled data. They use their algorithm and start working with problem and make some sense out of the problem on their own. Initially they may not provide much accuracy but they will eventually learn to provide accurate results.We can think about this learner as a person who went to some foreign country without any prior knowledge of the language spoken there.He learns from his experience how people greet each other, how to say hi etc.
Reinforcement Learning is a category in which a machine learns by making some predictions and is penalised for making a wrong prediction, due to this penalty machine learns not to make this mistake again.Take an example of a driverless robot that crawls on a road with obstacles, every time it see's an object and bumps into the object, it is penalised for its prediction of not taking appropriate action. Next time robot see's the same kind of obstacle it knows from the past experience and avoids the same mistake again.
Machine Learning for Classification problem
Classification is set of machine learning problems in which an input is classified into different classes which can be either supervised or unsupervised.
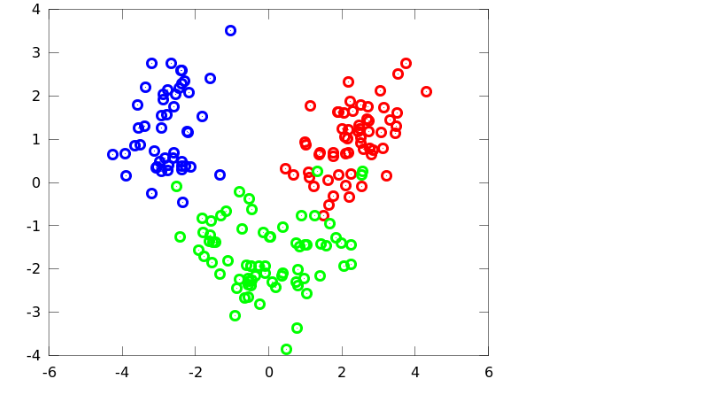
Examples of classification problems:
- Sentiment Analysis
- Product Categorization
- Binary Classification on reviews(pos, neg) and much more
Movie Review Classification using Naive Bayes Algorithm
I will be using nltk i.e is Natural Language Processing Toolkit available in python and movie review corpus that has labelled data for movie reviews classified as positive and negative.
importnltk.classify.utilfromnltk.classifyimportNaiveBayesClassifierfromnltk.corpusimportmovie_reviews#word_feats will convert the sentence into featuresdefword_feats(words):returndict([(word,True)forwordinwords])negids=movie_reviews.fileids('neg')posids=movie_reviews.fileids('pos')#training data is converted into featuresnegfeats=[(word_feats(movie_reviews.words(fileids=[f])),'neg')forfinnegids]posfeats=[(word_feats(movie_reviews.words(fileids=[f])),'pos')forfinposids]#data is divided into training and testing datanegcutoff=len(negfeats)*3/4poscutoff=len(posfeats)*3/4trainfeats=negfeats[:negcutoff]+posfeats[:poscutoff]testfeats=negfeats[negcutoff:]+posfeats[poscutoff:]'train on %d instances, test on %d instances'%(len(trainfeats),len(testfeats))#naivebayes classifier used for training on training dataclassifier=NaiveBayesClassifier.train(trainfeats)'accuracy:', nltk.classify.util.accuracy(classifier, testfeats)classifier.show_most_informative_features()'classified as:',classifier.classify("The plot was good,but the characters were not compelling")

Top comments (0)