About My Learning Notes Series:
Learning in public and teaching others is a great way to solidify information, so I decided to write articles about discoveries I make while learning. I will add links so you can investigate my resources and to of course, give credit.
However I'm not an expert. Also, standards change fast in the coding world, so think of this as the starting ground for your own research. Best of luck with your learning!
Please feel welcome to add corrections or comments.
Learning More About SEO
Disclaimer: canonicalizing urls can lead to problems if you're not careful. Read more here at at https://moz.com/blog/complete-guide-to-rel-canonical-how-to-and-why-not
What is SEO?
"Search engine optimization (SEO) is the process of improving a website or web page so it increases organic traffic quality and quantity from search engines. Successful SEO means a web page will be more likely to appear higher on a search engine results page (SERP)."
https://www.webopedia.com/definitions/seo/

Introducing the Problem

To start off, lets say we have 8 links. Each of these links send us to pages that visually look exactly the same:
1. https://www.website.com/category/product-a/ 2. https://www.website.com/product-a/ 3. https://website.com/product-a/ 4. http://www.website.com/product-a/ 5. http://website.com/product-a/ 6. https://m.website.com/product-a/ 7. https://www.website.com/product-a 8. https://www.website.com/product-A/ (https://www.semrush.com/blog/canonical-url-guide/)
To a search engine these are EIGHT different pages instead of one, so the search engine gets confused about which one is most important. So you get a lower SEO ranking.
How to fix this with a canonical tag:

Choose one url which is the best representation of your page. Such as
https://www.example.com/mainpage.html
Place this url in the rel=”canonical” tag in the head of your page
https://moz.com/blog/complete-guide-to-rel-canonical-how-to-and-why-not
if you use CMS platforms like:
- shopify
- Wix
- wordpress (with Yoast or RankMath plugins)
- Magneto 1 or 2
this article gives you detailed steps about how to create a canonical tag: https://www.semrush.com/blog/canonical-url-guide/#how-to-correctly-implement-the-rel=canonical-tag
Four other ways to specify canonical URLs

Putting it in the head is the most common option to specify canonical URLs. But other options are described here: https://ahrefs.com/blog/canonical-tags/
- HTTP header
- Sitemap
- 301 redirect
- Internal links
Tips:
1 Use absolute links:
<link rel="canonical" href="https://www.website.com/page-a/" />
Not relative links:
<link rel="canonical" href="/page-a/" />

2 Use only one rel=”canonical” tag per page.

If there's multiple canonical tags then google will likely ignore it and make it useless.
Special note: " This happens frequently in conjunction with SEO plugins that often insert a default rel=canonical link, possibly unbeknownst to the webmaster who installed the plugin" - Allan Scott @ https://developers.google.com/search/blog/2013/04/5-common-mistakes-with-relcanonical
3 Only put it in the head of a page.
If you put it in the body, it will be ignored.

4 Use a good link

- Watch out for spelling mistakes (ex: http when you mean https)
- Don't Canonicalize a 301 redirect.
5 Don't try to be sneaky
By canonicalizing a specific article to try to increase its google ranking. It will backfire on you.

6 If your page has multiple pages (pagination)

You have two choices
- 1 canonicalize the "view all" page
Not the root page. So the view counts for page 1, page 2, page 3, ect is counting as the "view all" pages views.
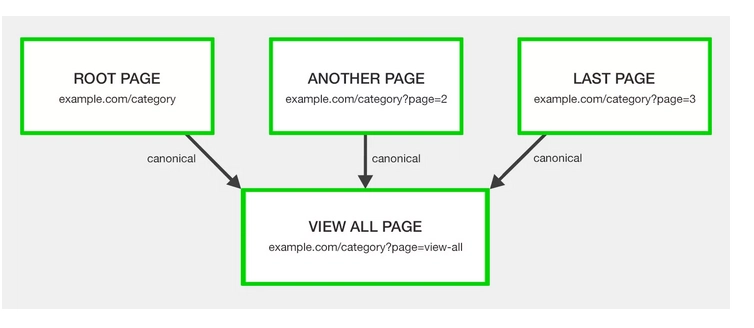 Source: https://www.searchenginejournal.com/technical-seo/pagination/
Source: https://www.searchenginejournal.com/technical-seo/pagination/
- 2 Give each page in its own canonical URL.
So a four page series would look like this:
Page 1
link rel="next" href="https://www.example.com/category?page=2″ ** link rel="canonical" href="https://www.example.com/category"'**
Page 2
link rel="prev" href="https://www.example.com/category" link rel="next" href="https://www.example.com/category?page=3″ **link rel="canonical" href="https://www.example.com/category?page=2"**
Page 3
link rel="prev" href="https://www.example.com/category?page=2″ link rel="next" href="https://www.example.com/category?page=4″ ** link rel="canonical" href="https://www.example.com/category?page=3"**
Page 4
<link rel="prev" href="https://www.example.com/category?page=3"> ** <link rel="canonical" href="https://www.example.com/category?page=4">**
code source : https://www.searchenginejournal.com/technical-seo/pagination/
Extra: Why do we not canonicalize the root page for paginated pages?

It makes search engines think you only have one page and it won't index the content on the 2nd, 3rd, 4th ect page.
"You don’t want your detailed content pages dropping out of the index because of poor pagination handling." - https://www.searchenginejournal.com/technical-seo/pagination/
7 If you have duplicated content such as
- HTTP and HTTPS
- Non-WWW and WWW
- Trailing-Slash and Non-Trailing Slash URLs
http://example.com/foo/ (with trailing slash, conventionally a directory)
http://example.com/foo (without trailing slash, conventionally a file)
code source: https://developers.google.com/search/blog/2010/04/to-slash-or-not-to-slash
Have the duplicate(s) redirect to the canonical url with a 301 redirect
Warning: "Let's be clear, however, that if you use 301 redirects, only the canonical URL will actually exist. The other duplicate versions will redirect to this." https://www.semrush.com/blog/canonical-url-guide/#using-301-redirects-to-specify-canonical-urls

8 Check your robots.txt file (if you have one)
robots.txt can be helpful, but if you accidentally told it to block your canonicalized URL, it will block the web crawlers from seeing your page. Which is exactly the situation you want to avoid.

Why is the search engine ignoring my canonical tag?
Although canonical tags can help try to convince a search engine to pay attention to that specific site link, it can be ignored. In other words, it is essentially just a suggestion.
Why Does this happen? Some possibilities are:
- conflicting url in a sitemap
https://www.semrush.com/blog/canonical-url-guide/#canonical-urls-in-sitemaps
- Pages aren’t a close enough match
So the search engine ignores the suggestion
(https://searchengineland.com/canonical-tags-easy-right-whats-worst-happen-274635)
https://moz.com/blog/catastrophic-canonicalization
Links to learn more:
https://ahrefs.com/blog/canonical-tags/
https://searchengineland.com/canonical-tags-easy-right-whats-worst-happen-274635
https://www.searchenginejournal.com/technical-seo/pagination/
https://searchengineland.com/canonical-tags-easy-right-whats-worst-happen-274635
https://www.semrush.com/blog/canonical-url-guide/
https://developers.google.com/search/blog/2013/04/5-common-mistakes-with-relcanonical
https://developers.google.com/search/docs/advanced/ecommerce/pagination-and-incremental-page-loading
https://moz.com/learn/seo/canonicalization
https://moz.com/blog/complete-guide-to-rel-canonical-how-to-and-why-not

Top comments (0)