The feature that I am trying to build here is about providing a typeahead (or autocomplete) feature with a dynamic list of terms for a UI. Those terms could be words, phrases, or numbers. I am hoping to do the search operations without any HTTP requests. There are a few solutions available out there but most of them are too complex or too tightly coupled with the UI component.
The solution has to be:
- Decoupled from the UI
- Efficient at search operations
- Flexible enough that a developer can implement it either on the front-end or back-end
Planning
Instead of breaking the search queries (prefixes) into arrays and compare it against every single word, phrase, and number in the form of an array, our solution will include a tree data structure and some recursive algorithms.
So let us begin with Ternary Search Tree (TST). It is an extension of Tries Tree where each node contains a character and is connected by edges forming a tree structure; TST is more space-efficient as it only contains up to 3 child nodes whereas Tries will contain up to 26 child nodes in an alphabetical vocabulary dataset.
Tries Tree - built with ['search', 'sections', 'seek', 'sear', 'seed', 'set', 'seo']
Ternary Search Tree - built with ['search', 'sections', 'seek', 'sear', 'seed', 'set', 'seo']
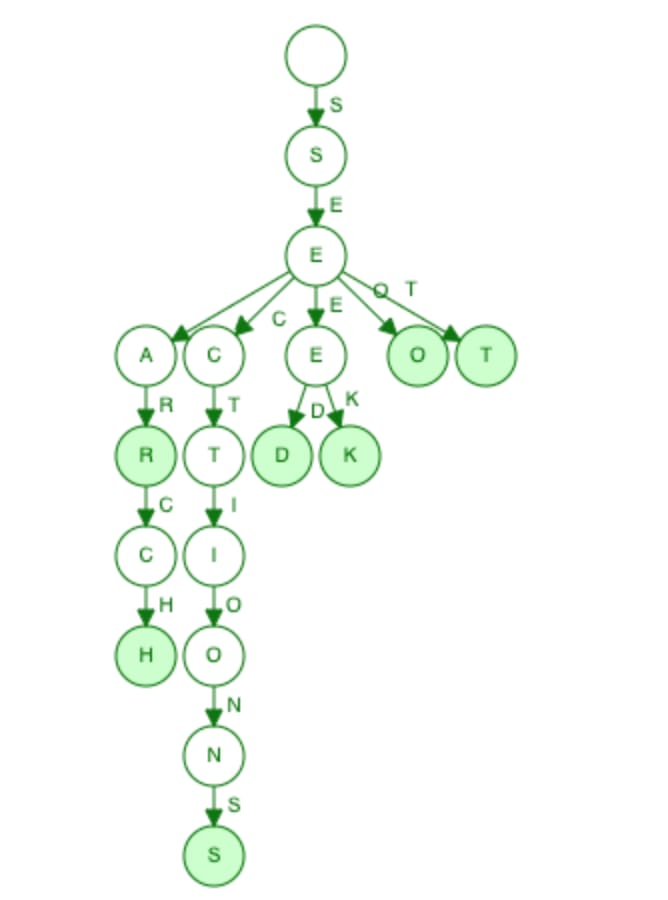
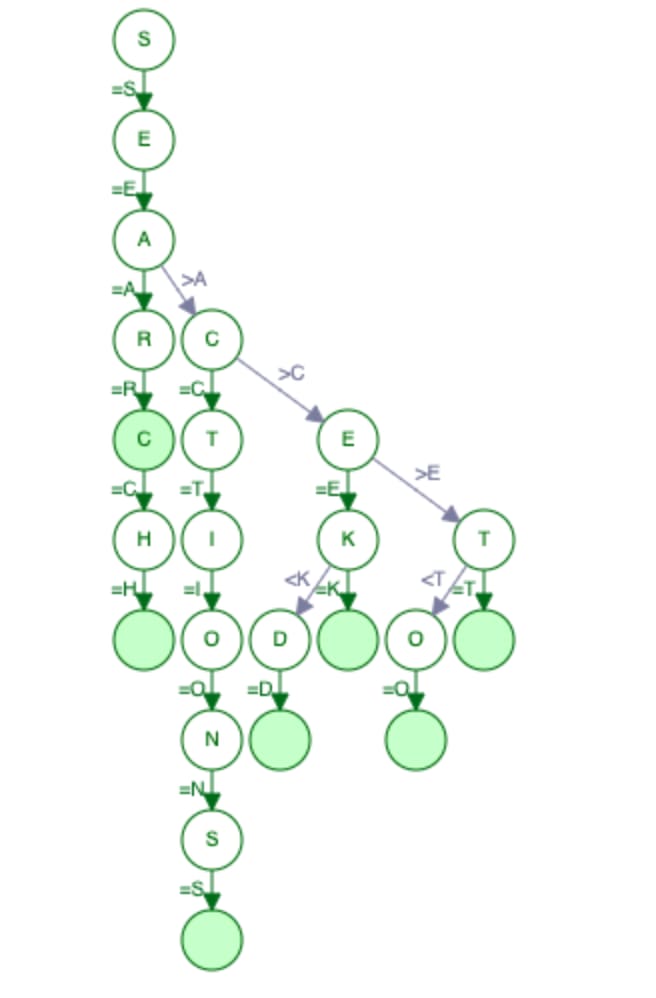
In a TST data structure, child nodes are stored as Binary Search Tree (BST) where greater alphabets are stored on the right and others are on the left. This structure allows us to reduce the size of the problem by half at every iteration in a search operation with the time complexity of O(log n) on average.
In a worse case scenario where the tree is not height-balanced meaning one side of the sub-tree has 2 or more edges than the other side, we have to hit every single node in a search operation until we reach the leaf node (the last node of the tree) or the matched suffix with the time complexity of O(n). We could prevent this by randomizing the data set and use the data item in the middle of the set as the root node. By doing this, we could guarantee that the tree will be height-balanced on average.
Average Case:
Search - O(log n)
Insert - O(log n)
Worst Case:
Search - O(n)
Insert - O(n)
Implementation
After some planning, I have put together a NPM package: typing-ahead implementing TST with the insert and search operations.
Those operations are written as recursive algorithms where each function call branches off to create a stack of calls and each call, in our case, reduces the size of the problem by half. We could trace back to each step of the recursion to debug our operations.
A set of tests (written with Jest) are also provided in the package to ensure that TST is height-balanced and the search operations return the expected results. One of the tests also validates the structure of the data model ensuring that it is a valid JSON schema.
Here is how the package works:
- Import the module
const typeahead = require('typing-ahead');
- Supply the dataset and record the model
const model = typeahead.generate([dataset]);
- Use the model when running search queries
const results = typeahead.find('queries', model);
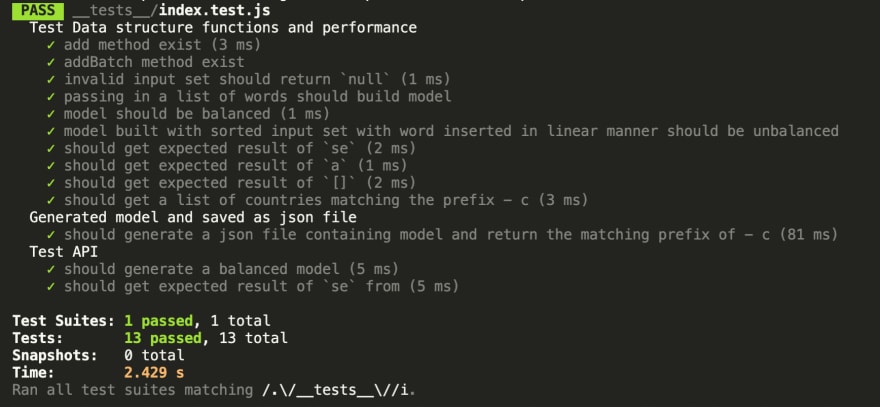
npm run testin typing-ahead package runs all available unit tests
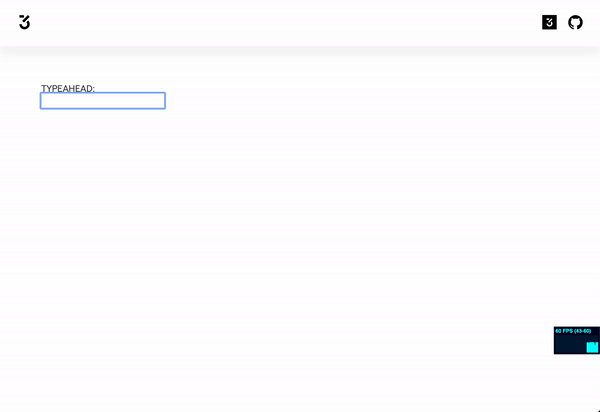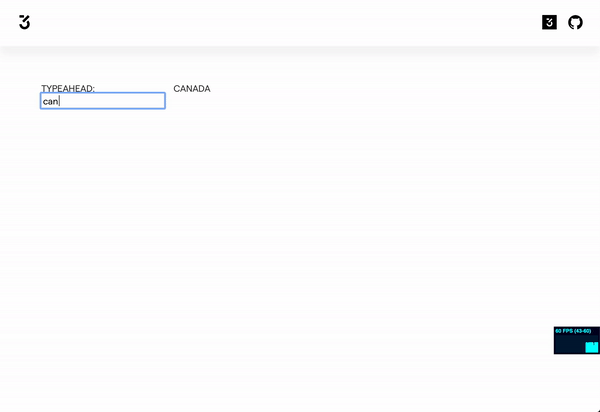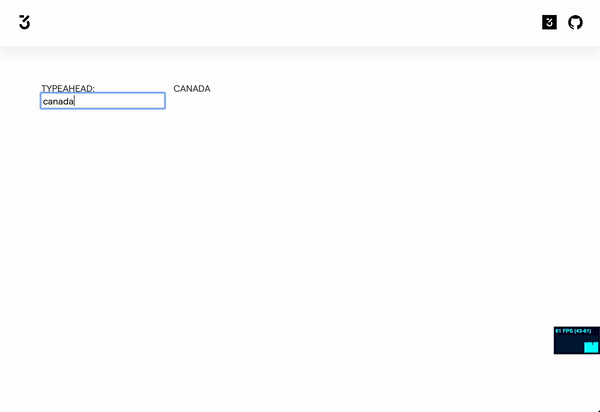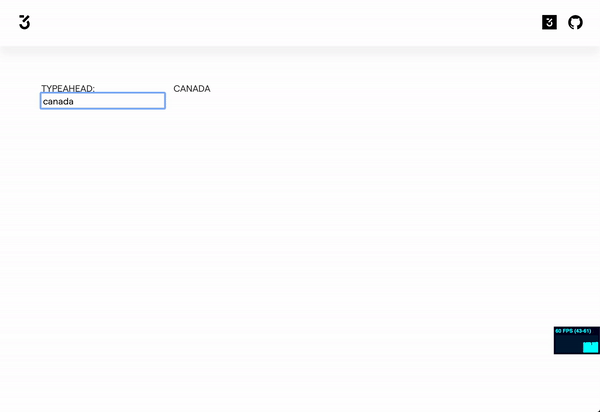
Here is a sandbox that shows how it works.
https://codesandbox.io/embed/typing-ahead-pq64e?fontsize=14&hidenavigation=1&theme=dark
Conclusion
At the end of the day, we have a modular and fairly efficient solution for developers to implement either on the front-end layer of the applications or provide the search feature through remote services with caching.
This prototype is built with Jam3 NexJS Generator

Top comments (0)