In this blog we're going to explore some design patterns related to concurrency pipelines in Go
- We'll take a real world use case as an example to begin with and try to optimize it with goroutines first.
- Next we'll see the challenges that arise and how to debug them.
- Finally we'll introduce another redesign that will enable us to collect stats about all the processing that we do in the above steps.
The problem statement
Let's say we have a set of users, and we want to make a few calls to an external microservice to filter out the set of users based on a set of parameters.
Since this external call an be over plain HTTP or over modern alternatives like gRPC, we won't go into the implementation of those.
What we'll focus on instead is first a brute force way of optimizing this functionality.
Implementation with goroutines
To start with lets say we have a file named handler.go with the following code:
handler.go
package handler
func PerformOperationAfterFiltering(users []users) {
// make external call and filter out users
operationToBePerformed(users)
}
High level design
Let's say we are getting a list of 1000 users each time on an average. It would be a good idea to break down this into batches before making external calls.
What this would enable us to do is split out our network calls. Hence if any batch fails due to some network factors, other batches won't be affected. If we do
a single call and that fails, we would loose the response for the entire 1000 users. Also breaking down this process into smaller chunks would also enable us to optimize
it further in the subsequent steps – divide and conquer.
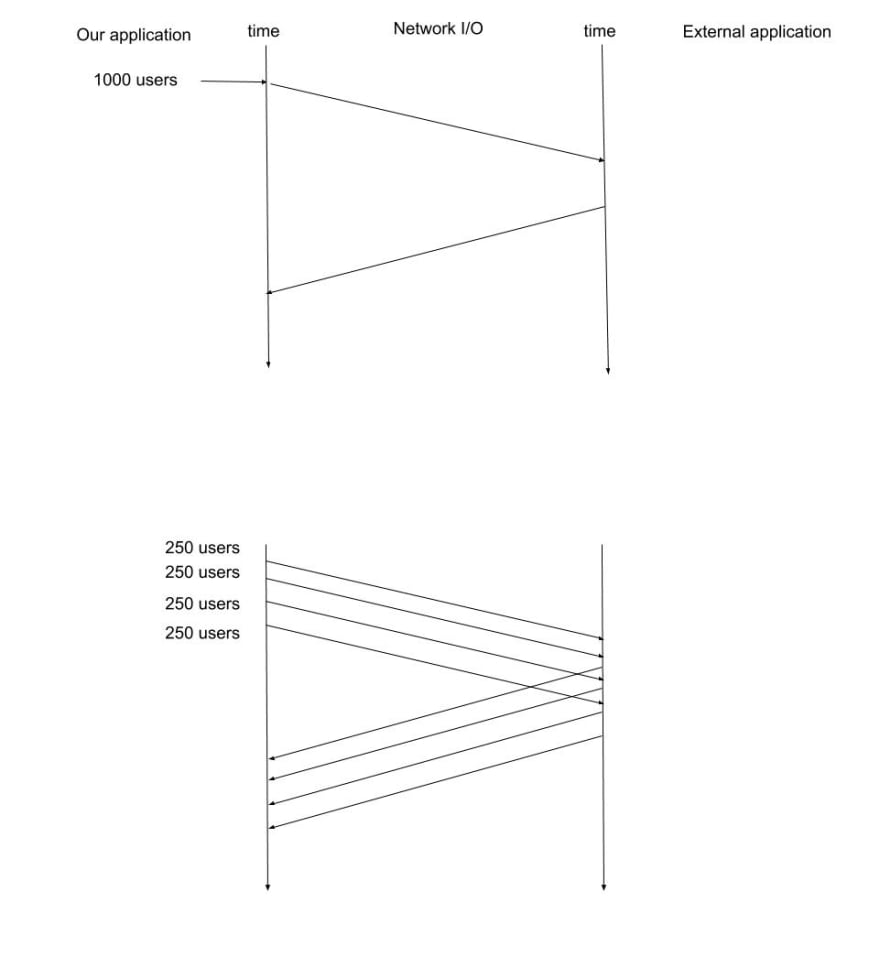
But before we do that, we need to understand how we plan to communicate the results back to the calling function, and how do we know all requests have finished?
We'll be using 2 golang constructs for this:
- Channels
- WaitGroup
the high-level architecture should look something like this:

Let's open a new file to write our request function
request.go
package request
import "sync"
func Request(users []Users) chan Users {
resp := make(chan Users)
batchSize := 250
var batches [][]Users
var wg sync.WaitGroup
for batchSize < len(users) {
users, batches := users[batchSize:], append(batches, users[0:batchSize])
}
batches = append(batches, batchSize)
}
Now that we have our batches created, we can start the requests for each batch in a goroutine of its own.
But everytime we start a new goroutine, we'll add (or register) it with a WaitGroup to keep track of the completion of each of the individual goroutines.
func Request(users []Users) chan Users {
resp := make(chan Users)
batchSize := 250
var batches [][]Users
for batchSize < len(users) {
users, batches := users[batchSize:], append(batches, users[0:batchSize])
}
batches = append(batches, batchSize)
var wg sync.WaitGroup
for batch, _ := range batches {
wg.Add(1)
go func(batch []Users) {
defer wg.Done()
response, err := MakeRequestToThirdParty(batch)
if err != nil {
// log error and probably
// also the batch of users that failed
}
for r, _ := range response {
if r.CurrentBalance > 500 {
// we've got our user
// push it back on our channel
resp <- r.u
}
}
}(batch)
}
return resp
}
Note that the function returns a
channelof typeUsers.
Also we added a defer call to wg.Done(). This will decrement our waitgroup so that our exit stages knows when all our goroutines are done.
Before we goto the exit stage, let's see how we plan to consume the users from the channel. Channels fit right in with the golang's for loop – i.e. we can consume
objects from channel just by the for-range loop of go.
In our handler.go:
package handler
import "request"
func PerformOperationAfterFiltering(users []users) {
// make external call and filter out users
var filteredUsers []Users
for user := range Request(users) {
filteredUsers = append(filteredUsers, user)
}
operationToBePerformed(users)
}
That's exactly what we're doing here. range-ing over the open channel. How or when will the loop exit you may ask?
– When we close() the channel. And that's where the EXIT stage comes in.
So we go on to the exit stage. Back in our request.go, we add another closure, which makes use of our WaitGroup:
func Request(users []Users) chan Users {
resp := make(chan Users)
batchSize := 250
var batches [][]Users
for batchSize < len(users) {
users, batches := users[batchSize:], append(batches, users[0:batchSize])
}
batches = append(batches, batchSize)
var wg sync.WaitGroup
for batch, _ := range batches {
wg.Add(1)
go func(batch []Users) {
defer wg.Done()
response, err := MakeRequestToThirdParty(batch)
if err != nil {
// log error and probably
// also the batch of users that failed
}
for r, _ := range response {
if r.CurrentBalance > 500 {
// we've got our user
// push it back on our channel
resp <- r.User
}
}
}(batch)
}
// EXIT stage
go func() {
// wait for the wait group counter to drop down to 0
// which will happen when all goroutines are done
wg.Wait()
// now we close the response channel
// this will make our loop also exit
close(resp)
}()
return resp
}
The code above is self-explanatory and mimics our initial arch design completely without any issues.
Where things get dim?
The current code works perfectly. But when we deploy such code to production we usually want to log and collect metrics related to what happened.
What went wrong, what worked, how many users passed, how many didn't etc.
The current design leaves little room for collecting such metrics as we'll see soon.
Collecting metrics
The simplest approach to collecting metrics is:
- Build 2 maps with userids to user objects – one for users passing the condition, another for users failing the condition.
- On response, add the user to the relevant map
So let's add this simple solution to our code
handler.go
func Request(users []Users) chan Users {
resp := make(chan Users)
batchSize := 250
var batches [][]Users
passedUsers := make(map[int64]Users)
skippedUsers := make(map[int64]Users)
for batchSize < len(users) {
users, batches := users[batchSize:], append(batches, users[0:batchSize])
}
batches = append(batches, batchSize)
var wg sync.WaitGroup
for batch, _ := range batches {
wg.Add(1)
go func(batch []Users) {
defer wg.Done()
response, err := MakeRequestToThirdParty(batch)
if err != nil {
// log error and probably
// also the batch of users that failed
}
for r, _ := range response {
if r.CurrentBalance > 500 {
// we've got our user
// push it back on our channel
resp <- r.User
passedUsers[r.User.UserId] = r.User
}
skippedUsers[r.User.UserId] = r.User
}
}(batch)
}
// EXIT stage
go func() {
// wait for the wait group counter to drop down to 0
// which will happen when all goroutines are done
wg.Wait()
defer LogMetrics(passedUsers, skippedUsers)
// now we close the response channel
// this will make our loop also exit
close(resp)
}()
return resp
}
The code looks fine – we have added two maps and are writing our users to it. In the exit stage we've added a defer statement which will basically make sure that metrics are definitely registered. This code would compile without any errors and also run without errors for sometime, but there is a serious bug which will crash our code in very weird ways.
The issue
Whenever we write a concurrent piece of code in go and it panics due to some reason which seems weird, go race detector the the tool to run for.
The issue comes do to a race condition where we are trying to write to our hashmaps inside our goroutines. You see these hashmaps are shared data among the goroutines, and it will so happen that at a time more that one goroutine might try to write to these maps – which would result in a data race. And data race in in go are undefined behavior and will basically crash the whole program with not so friendly error messages. This is show in the image in red.

On running the above code with race detector enabled, we'll get some output like this:
==================
WARNING: DATA RACE
Read by goroutine 5:
request.Request·001()
request.go:36 +0x169
Previous write by goroutine 1:
request.Request()
request.go:36 +0x174
Goroutine 5 (running) created at:
request.goFunc()
request.go:19 +0x56
==================
This simply tells us the line nos where the data race occurred, this is the first data race, another similar one is right below it where we access the skippedUsers map.
In order to fix this, we need to redesign our pipeline architecture slightly. Which we will see in the next iteration of this post.

Top comments (0)