
Introdução
Este artigo descreve a primeira parte do desenvolvimento de um sistema web para obter e visualizar o tempo de disponibilidade e indisponibilidade de instâncias EC2 na AWS.
O sistema consiste em duas partes: um backend onde utilizaremos um script em python para obter e tratar os dados necessários para gerar os relatórios e um frontend composto por uma página simples que utilizará HTML, Javascript e CSS, para fornecer um dashboard com gráficos e insights sobre as instâncias EC2 de todas as regiões da conta.
Arquitetura proposta

Com esta arquitetura, teremos uma Função Lambda que fará a coleta de métricas de StatusCheckFailed vindas do CloudWatch para todas as instâncias da conta. Após coletá-las, o Lambda irá tratá-las e armazenar os resultados em um Bucket S3. O Bucket armazenará esses resultados em arquivos .csv juntamente com os arquivos HTML, Javascript e CSS que irão compor o sistema. Utilizaremos o CloudFront para distribuir o conteúdo e também proteger os acessos para somente usuários autorizados.
Com isso teremos um Dashboard com o total, em horas, de tempo disponível e indisponível de todas as instâncias EC2. Também será possível baixar esse relatório em formato CSV para melhor administração.
Métricas de Status Check
As métricas de status check na AWS são uma forma de monitorar a saúde e o desempenho das instâncias do Amazon EC2 (Elastic Compute Cloud) em uma região específica. Essas métricas fornecem informações sobre a integridade dos componentes da instância, como a camada de virtualização, a conectividade de rede e o sistema operacional.
Vamos passar rapidamente sobre o papel de cada uma:
StatusCheckFailed: Essa métrica relata se a instância passou tanto na verificação de status da instância quanto na verificação de status do sistema no último minuto. Ela tem um valor binário, onde 0 significa que passou e 1 significa que falhou. Por padrão, essa métrica está disponível gratuitamente a cada um minuto. As unidades dessa métrica são contagem.
StatusCheckFailed_Instance: Essa métrica informa se a instância passou na verificação de status da instância no último minuto. Similar à métrica anterior, ela possui um valor binário de 0 (passou) ou 1 (falhou). Também está disponível gratuitamente a cada um minuto e suas unidades são contagem.
StatusCheckFailed_System: Essa métrica indica se a instância passou na verificação de status do sistema no último minuto. Mais uma vez, ela possui um valor binário de 0 (passou) ou 1 (falhou). A disponibilidade gratuita e a frequência de um minuto também se aplicam a essa métrica, e suas unidades são contagem.
Ao acompanhar essas métricas, é possível identificar problemas e tomar medidas corretivas quando ocorrerem falhas nos status checks.
Com base nas métricas de status check registradas no CloudWatch, podemos calcular o tempo de disponibilidade das instâncias. Ao monitorar as falhas nos status checks e calcular o tempo em que as instâncias estão passando nesses checks, é possível ter uma estimativa do tempo em que as instâncias estiveram disponíveis.
No entanto, é importante destacar que essa abordagem é uma estimativa e depende de vários fatores, como a frequência de verificação das métricas, por exemplo. Além disso, existem outros fatores que podem afetar a disponibilidade das instâncias, como atualizações de sistema operacional, manutenção programada, eventos de força maior, entre outros.
Calculando o tempo de Downtime e Uptime
Para calcular o tempo de disponibilidade das instâncias, utilizaremos um código em Python para rodar em uma função Lambda, que tem como propósito principal gerar um relatório de disponibilidade das instâncias do Amazon EC2 em várias regiões da AWS. Ele utiliza a biblioteca boto3 para interagir com os serviços da AWS, como o CloudWatch e o S3.
O código itera sobre cada região configurada e, em seguida, obtém informações sobre as instâncias EC2 presentes em cada região. Para cada instância, são coletadas métricas de falha de status usando o CloudWatch. Com base nessas métricas, o código calcula o tempo de disponibilidade e indisponibilidade de cada instância.
Após processar todas as regiões e instâncias, os dados são armazenados em uma lista e, em seguida, enviados como um arquivo CSV para um bucket S3 especificado. O relatório contém informações como ID da instância, nome, tipo, plataforma, tempo de disponibilidade, tempo de indisponibilidade e porcentagem de disponibilidade.
Baixe o código neste repositório.
Hora de colocar a mão na massa. Vamos lá!
1 - Criar bucket S3
Acesse o console do Amazon S3 e clique em Create bucket. Dê um nome para seu bucket e escolha a região de sua preferência.

Deixe o restante das opções como padrão e clique em Create bucket.

2 - Criar uma função do IAM
No console do IAM, clique em Policies no menu lateral esquerdo e depois em Create policy. Clique na guia JSON e substitua o código JSON por este:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::your-bucket-name-123456/*"
}
]
}
Desta forma, a função Lambda que usará essa IAM role terá acesso restrito somente ao bucket em questão.
Substitua o nome do bucket na linha "Resource": "arn:aws:s3:::your-bucket-name-123456/*" pelo nome do bucket que você criou anteriormente. Avance para a parte de Review para dar um nome à sua Policy e depois clique em Create Policy.
Vamos então criar uma Role e atachar a Policy criada junto com outras necessárias para o funcionamento do script. Clique em Roles no menu lateral esquerdo e depois em Create Role.

Em Trusted entity type escolha AWS service, marque o serviço Lambda e avance para atachar as policies necessárias.

Em Add permissions pesquise pela policy que você criou anteriormente e marque a caixa ao lado do nome para selecioná-la. Faça o mesmo processo para as seguintes policies:
- CloudWatchLogsReadOnlyAccess
- AmazonEC2ReadOnlyAccess
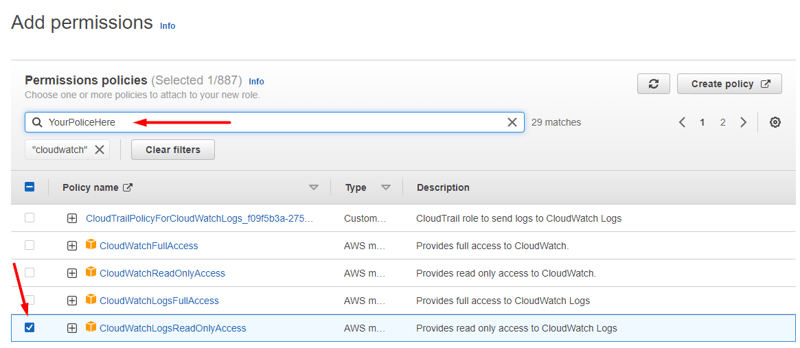
Avance para escolher um nome para sua Role e revise as Policies atachadas. Feito isso, clique em Create role.
3 - Criar função Lambda
Acesse o console do Lambda e clique em Create function. Escolha a opção Author from scratch para iniciar com um exemplo de código. Dê um nome para sua Função Lambda e escolha o Runtime Python 3.10.

Em Change default execution role escolha Use an existing role e selecione a Role que você criou no passo anterior. Feito isso clique em Create function.

Agora que você criou a Função, substitua o código de exemplo pelo código que está neste repositório. Após inserir o código, clique em Deploy para Salvar as alterações.
Feito isso, vá para a aba Configuration e mude o Timeout para 2 minutos (configure um tempo maior ou menor de acordo com a quantidade de instâncias do ambiente).

Lembre-se de alterar as regiões, o nome do bucket e o nome do arquivo no script.

Vá para a aba Test para configurar um novo teste. Dê um nome ao evento e clique em Save.

Após salvar, execute um teste. Se tudo correr bem você verá uma saída como a imagem abaixo.

3 - Configurar EventBridge
Na parte superior da página da função, em Function Overview, clique em Add trigger.

Em Trigger configuration selecione EventBridge (CloudWatch Events). Crie uma nova regra, dê um nome para a regra e em seguida selecione Schedule expression para inserir uma Cron.
Aqui você pode configurar uma expressão que melhor atende a sua necessidade. Neste exemplo usei uma expressão que chamará a função Lambda de 30 em 30 minutos.
cron(0/30 * * * ? *)
Após inserir o valor clique em Add.

4 - Baixe o relatório gerado
Volte ao bucket criado, navegue até a pasta “data/” e faça download do arquivo .csv gerado pelo script.
As primeiras colunas do arquivo dizem respeito às especificações das instâncias como ID, nome, tamanho e sistema operacional.
As informações sobre disponibilidade estão nas colunas uptime_hours, downtime_hours e hours_used.
- uptime_hours: tempo em que a instância ficou disponível e operante.
- downtime_hours: tempo em que a instância ficou indisponível e não operante (devido a alguma falha detectada pelas métricas de status check).
- hours_used: tempo total em que a instância permaneceu ligada, independente de estar operante ou não operante.
Por fim, temos as colunas start_date e end_date que representam o período em que o relatório se baseia. Por configuração do script, o relatório sempre começará no primeiro dia do mês às 00:00 horas e terminará no último horário de execução da função lambda, segmentando cada relatório por mês atual.

Conclusão
Concluímos a primeira parte de nosso sistema. Com isso, temos um backend que nos traz um relatório de tempo de disponibilidade e indisponibilidade das instâncias EC2 da conta.
Na parte 2 deste artigo, vamos criar um frontend utilizando HTML, Javascript e CSS para poder exibir esse relatório de forma mais apreciativa, e claro, vamos utilizar dos serviços da AWS que são próprios para isso, visando o mínimo custo possível. Até lá!





Top comments (1)
Parabéns pelo post! Já estou ansioso pela segunda parte.
Tenho uma dúvida: o downtime_hours deve considerar toda a indisponibilidade da instância? No seu post, você menciona como é calculado, mas também fala sobre paradas da instância para manutenção. Surgiu uma dúvida: as métricas usadas, como StatusCheckFailed, consideram o tempo em que a instância para ou reinicia como tempo de downtime? Caso uma instância pare fora de uma janela de manutenção, isso seria contabilizado como um falso uptime?