¿Qué es Azure Storage Table?
Azure Storage Tables es un servicio de persistencia que maneja información no-relacional estructurada en la nube. Ofreciendo un mecanismo de almacenamiento key/attributes (Tablas y Rows) sin un esquema forzado (como T-SQL).
Storage Tables es un servicio de bajo costo y eficiente, que permite guardar terabytes de información. Al no forzar el uso de un esquema como en SQL Server (o cualquier base de datos relacional) la adopción y la evolución es rápida y sencilla.
Table storage no es necesariamente para usarse como tu persistencia principal, yo lo veo como algo complementario a una base de datos principal. Suele guardarse información en grandes cantidades y de forma estructurada para que pueda consultarse de forma eficiente.
El uso que se le puede dar es el que desees, solo debes de considerar que no está pensado para que sea una base de datos relacional, sino para guardar información como:
- Terabytes de información estructurada que no requieren relaciones complejas o llaves foráneas y puede ser desnormalizada para facilitar el acceso y sea más rápido.
- Ejemplos:
- Logs de actividad
- Tengo sistemas en donde se guarda toda la actividad de los usuarios, y aunque sean millones de registros, se pueden consultar
- Telemetría
- Hace tiempo lo implementamos en un proyecto IoT donde procesábamos alrededor de 30 millones de mensajes al mes.
- Registros masivos
- En este artículo veremos el registro de solicitudes como ejemplo
Nota 💡: El código fuente lo encuentras en mi github aquí
Conceptos importantes
-
Accounts: Necesitamos un Storage Account para acceder a la API de Tables
- Junto con un Storage Accounts también contamos con:
-
Queues. Para mensajería simple, pero con millones de mensajes
- Ya he escrito de esto aquí
- Blobs. Almacenamiento archivos / binarios
- Table: Es una colección de Entities. Tables no te obliga a seguir un esquema en cada entity, lo que significa que en una misma tabla puedes contener distintas propiedades (AKA columnas).
- Entity: Un Entity es una colección de propiedades, exactamente como un row en una base de datos. Un Entity dentro de Azure Storage puede pesar hasta 1MB. En Azure Cosmos DB puede pesar hasta 2MB.
-
Propiedades: Una propiedad consiste en un nombre-valor. Cada entity puede tener hasta 252 propiedades.
- Cada entity también tiene 3 propiedades por default donde se especifica el Partition Key, Row Key y el timestamp
- Entities dentro del mismo PartitionKey se pueden consultar significativamente más rápido
- El RowKey es la llave primaria de cada Entity.
Guía para un buen diseño
Es importante considerar los requerimientos iniciales al usar Azure Tables, ya que es necesario decidir cómo vamos a guardar la información dependiendo de cómo queremos consultarla de forma eficiente.
Diseño para una lectura eficiente
-
Siempre especificar el PartitionKey y RowKey en los Queries. Siempre que hagamos queries, es mucho más eficiente si siempre especificamos la partición y la llave que buscamos.
- En el ejemplo que veremos más adelante, nos enfocaremos en este punto.
- Considera duplicar la información. Table Storage es muy baráto que el tamaño de la persistencia ya no importa, por lo que guardar el mismo entity varias veces para mejorar las consultas (según la necesidad de consulta) es algo recomendable.
-
Desnormalizar tu información. Al igual que lo anterior, el almacenamiento es de bajo costo, desnormalizar tu información es recomendable. Repetir información dentro de un entity para no tener que consultarla con alguna relación hace las consultas más rápidas
- Considera aquí que la información no cambie a cada momento, si sí, piénsalo dos veces.
Diseño para una escritura eficiente
-
Evita particiones que se tengan que acceder demasiado. La creación de particiones a partir de un Key hace muy dinámico como distribuimos la información.
- Ejem. En Logs yo suelo crear Partition Keys así: Events{DDMMYYYY} y así tendré una partición cada mes.
- Ejem. Hablando de IoT, guardaba históricos en particiones según el dispositivo: Device{ID_DEVICE}_{DDMMYYYY} y así genero particiones por dispositivo y por mes (todo depende también, como necesito consultar la información)
- No siempre es necesario una tabla por cada entity. Ya que no se nos obliga seguir un esquema, podemos guardar distintos tipos de entities en un mismo table, esto para asegurar operaciones atómicas cuando guardamos información. Si este no es el caso, separar en distintas tablas es mejor.
Si quieres saber más
Ejemplo práctico: Registro masivo de solicitud de Vacunas
Estamos casi a finales del 2022 y yo sé que ya pasó de moda hablar de las vacunas y pandemia, pero este ejemplo se me ocurrió, porque es algo que es ad hoc para esta tecnología.
En México, la mecánica para vacunarnos (y saber cuántos se pensaban vacunar) era registrarse en una página web utilizando tu número único de registro de población (llamado CURP). Millones de personas se registraron, y una vez registrado, podías consultar tu solicitud o si intentabas registrarte nuevamente, ya no podías.
Lo que vamos a considerar para diseñar esta solución:
- Solo te puedes registrar una vez, así que la CURP funciona como la llave primaría (Row Key)
- Para consultar "n" número de solicitudes, se necesita el estado y la ciudad (Partition Key)
- Para consultar tu solicitud, se necesita el Estado y la Ciudad y tu CURP (Partition Key y Row Key)
- Campos: Nombre completo, CURP, Estado y Ciudad
La intención de construir así el Partition Key es para poder consultar todas las solitudes de una ciudad de forma rápida. No es práctico querer consultar todo el país, pero por ciudad, se reduce más el volumen y podemos hacer queries más específicos (como filtrar por edad, género, etc).
Proyecto API: AzureTableStorage
Antes de comenzar, debemos de asegurarnos que tenemos el emulador (AKA Azurite) instalado. Este viene con las herramientas de Azure de Visual Studio, pero por si no lo tienes, visita esta página para conocer más.
Yo en lo personal me gusta usar Azurite con npm porque solo con un comando lo puedo iniciar.
Una vez con Azurite instalado, crearemos un proyecto web vacío en una carpeta para el proyecto (en mi caso se llamó AzureStorageTables):
dotnet new web
E instalamos los siguientes paquetes:
dotnet add package Azure.Data.Tables
dotnet add package System.Linq.Async
Nota 💡: Usaremos System.Linq.Async para procesar Streams asincronos con Linq.
Models > VaccineRequest
Definimos nuestro Entity, es necesario implementar la interfaz ITableEntity. Aquí vienen las tres propiedades obligatorias de un Entity en Tables:
using Azure;
using Azure.Data.Tables;
namespace AzureStorageTables.Models;
public class VaccineRequest : ITableEntity
{
public string Curp { get; set; }
public string FullName { get; set; }
public string City { get; set; }
public string State { get; set; }
public string PartitionKey { get; set; }
public string RowKey { get; set; }
public DateTimeOffset? Timestamp { get; set; }
public ETag ETag { get; set; }
}
Nota 😂:
ETagnunca lo he usado y hasta el día de hoy no sé para qué es...
Services > IVaccineRequestStoreService
Aquí definimos nuestro contrato para nuestro almacén de información, not a big deal. Por ahora solo tendremos tres métodos, uno para crear y dos para consultar:
using AzureStorageTables.Models;
namespace AzureStorageTables.Services;
public interface IVaccineRequestStoreService
{
Task CreateRequestAsync(VaccineRequest entity);
Task<VaccineRequest> GetRequestAsync(string curp, string state, string city);
IAsyncEnumerable<VaccineRequest> GetRequestsByCityAsync(string state, string city);
}
El Partition Key lo he pensado que esté compuesto por el Estado y la Ciudad. Por lo que las consultas se deben de hacer siempre especificando estos datos (para que sea super rápido).
Si no se especifican el Partition Key en una consulta, esta será muy lenta.
Por lo que, dependiendo de las necesidades, podemos pensar de forma diferente y armar por ejemplo el partition key por solamente el estado, año de nacimiento, sexo, o una combinación de todos estos. Siempre recuerda, que deberás (aunque no obligado) buscar siempre por partition key.
Services > VaccineRequestStoreService
Aquí la implementación del Store, aquí es donde utilizamos Tables Storage:
using Azure.Data.Tables;
using AzureStorageTables.Models;
namespace AzureStorageTables.Services;
public class VaccineRequestStoreService : IVaccineRequestStoreService
{
public const string TableName = "VaccineRequests";
private TableClient _tableClient;
public VaccineRequestStoreService(IConfiguration config)
{
_tableClient = new TableClient(config["TableStorage:ConnectionString"], TableName);
}
public async Task CreateRequestAsync(VaccineRequest entity)
{
await _tableClient.CreateIfNotExistsAsync();
entity.PartitionKey = $"{entity.State}_{entity.City}";
entity.RowKey = entity.Curp;
_ = await _tableClient.AddEntityAsync(entity);
}
public async Task<VaccineRequest> GetRequestAsync(string curp, string state, string city)
{
var results = _tableClient
.QueryAsync<VaccineRequest>(q => q.PartitionKey == $"{state}_{city}" && q.RowKey == curp);
await foreach (var entity in results)
{
return entity;
}
return null;
}
public IAsyncEnumerable<VaccineRequest> GetRequestsByCityAsync(string state, string city) =>
_tableClient
.QueryAsync<VaccineRequest>(q => q.PartitionKey == $"{state}_{city}");
}
Resumen de cada método:
-
CreateRequestAsync
-
CreateIfNotExistsAsynccrea la tabla si esta no existe - Ten en cuenta que esto es un request HTTP, se podría buscar la forma de solo hacerlo al inicio y no en cada Create
-
-
GetRequestAsync:
-
QueryAsyncRegresa una colección asíncrona (estilo IAsyncEnumerable) de resultados, los debemos de iterar para accesarlos - Iteramos con
await foreachpara acceder a los resultados. Lo hacemos de esta forma porque el SDK automáticamente maneja paginación - En este caso, solo queremos el primer resultado (porque, será un resultado por que usamos el Row Key)
- El Partition Key está compuesto por el estado y la ciudad (
$"{state}_{city}")
-
-
GetRequestsByCityAsync:
- De igual forma con
QueryAsyncrealizamos la consulta, pero aquí hacemos algo un poco diferente - Regresamos un stream de información con
IAsyncEnumerablepara ir procesando la información mientras la vamos consultando - Como pueden ser miles de registros, no queremos consultarlos todos en memoría y luego convertirlos en un DTO
- Regresamos el
AsyncPageque es una implementación deIAsyncEnumerabley la presentación se encargará de convertirlo a DTO con forme vaya llegando la información
- De igual forma con
Program.cs
Para terminar, usaremos Minimal APIs para crear los endpoints y exponero esta funcionalidad:
using Azure;
using AzureStorageTables.Models;
using AzureStorageTables.Services;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddScoped<IVaccineRequestStoreService, VaccineRequestStoreService>();
var app = builder.Build();
// Endpoints Aquí...
app.Run();
Para crear y leer solicitudes de vacunación, usaremos un DTO para no exponer propiedades que no queremos (como los Partition Key y Etags).
namespace AzureStorageTables.Models;
public record VaccineRequestDto(string Curp, string FullName, string City, string State);
Endpoint POST api/vaccine-requests
Al crear, llamamos directamente al Store:
app.MapPost("api/vaccine-requests", async (VaccineRequestDto request, IVaccineRequestStoreService store) =>
{
try
{
await store.CreateRequestAsync(new VaccineRequest
{
City = request.City,
State = request.State,
Curp = request.Curp,
FullName = request.FullName
});
}
catch (RequestFailedException ex)
// Ya existe una solicitud con esta CURP
when (ex.Status == StatusCodes.Status409Conflict)
{
return Results.BadRequest($"Ya existe una solicitud del CURP {request.Curp}");
}
return Results.Ok();
});
Hacemos uso de Exception Filters para regresar un Bad Request cuando queremos crear una solicitud con CURP repetida. Azure nos regresa un 409 si intentamos crear un registro con un Partition Key y Row Key ya existentes.
Endpoint GET api/vaccine-requests
Consulta de solicitudes por ciudad:
app.MapGet("api/vaccine-requests", (string state, string city, IVaccineRequestStoreService store) =>
{
return Results.Ok(store
.GetRequestsByCityAsync(state, city)
.Select(s => new VaccineRequestDto(s.Curp, s.FullName, s.City, s.State))
);
});
Aquí estamos aprovechando el IAsyncEnumerable para ir procesando y serializando la información al mismo tiempo que se va consultando. De esta forma estamos evitando cargar en memoría todos los datos, sino que los vamos procesando en un Stream de forma asíncrona.
La idea no es regresar miles o millones de registros, la idea es poder consultar unos cientos dentro de miles o millones de registros, pero procesar la información así, es útil de igual forma si esto es de alta concurrencia.
Endpoint POST api/vaccine-requests/{curp}
Consulta de solicitudes en lo individual:
app.MapGet("api/vaccine-requests/{curp}", async(string curp, string state, string city, IVaccineRequestStoreService store) =>
{
var request = await store.GetRequestAsync(curp, state, city);
return new VaccineRequestDto(request.Curp, request.FullName, request.State, request.City);
});
En teoría, este método debe de ser muy rápido, aunque tengamos millones de registros, esto es porque estamos especificando la partición y la llave primaría del Entity.
appsettings.json
Usamos UseDevelopmentStorage=true para que se use Azurite (el emulador local del Storage):
{
"TableStorage": {
"ConnectionString": "UseDevelopmentStorage=true"
},
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"AllowedHosts": "*"
}
Probando con REST Client
Para probar los endpoints, podemos configurar swagger, pero a veces a mí me gusta hacerlo con solicitudes HTTP manuales (que igual las commiteo) utilizando una extensión de VS Code llamada REST Client.
Request
### Create Vaccine Request
POST https://localhost:7066/api/vaccine-requests
Content-Type: application/json
{
"fullName": "Isaac Ojeda",
"curp": "test00001",
"city": "Chihuahua",
"state": "Chihuahua"
}
Response
HTTP/1.1 200 OK
Content-Length: 0
Connection: close
Date: Sun, 09 Oct 2022 04:59:38 GMT
Server: Kestrel
Request
### Get Vaccine Requests by State
GET https://localhost:7066/api/vaccine-requests?state=Chihuahua&city=Chihuahua
Content-Type: application/json
Response
[
{
"curp": "1234567890",
"fullName": "Isaac Ojeda",
"city": "Chihuahua",
"state": "Chihuahua"
},
{
"curp": "test00001",
"fullName": "Isaac Ojeda",
"city": "Chihuahua",
"state": "Chihuahua"
},
{
"curp": "test00002",
"fullName": "Isaac Ojeda",
"city": "Chihuahua",
"state": "Chihuahua"
}
]
Request
### Get Vaccine Request by CURP
GET https://localhost:7066/api/vaccine-requests/test00001?state=Chihuahua&city=Chihuahua
Content-Type: application/json
Response
{
"curp": "test00001",
"fullName": "Isaac Ojeda",
"city": "Chihuahua",
"state": "Chihuahua"
}
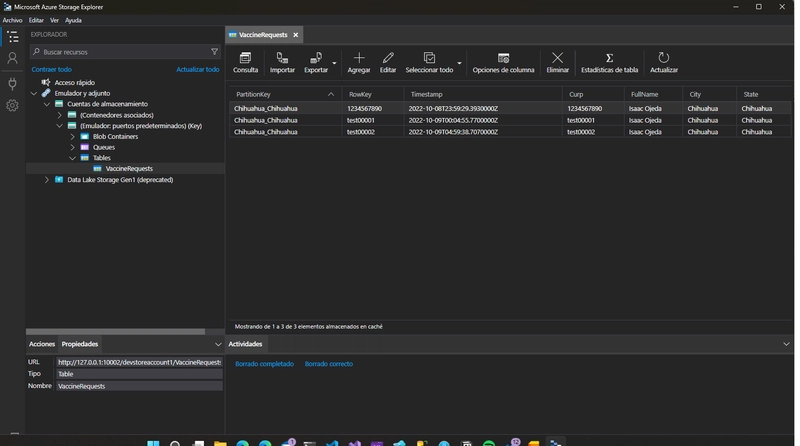
Podemos usar el Storage Explorer para visualizar la información que vamos creando en el Account.
Conclusión
Azure Tables Storage lo uso en todos los proyectos en los que participo, ya sea para guardar logs, información de la misma aplicación y lo que sea que aplique.
Table Storage puede estar geo-replicado, puede integrarse en una virtual-network de Azure, enlaces privados para nube hibrida y un sin fin de cosas que Azure ofrece.
En lo personal tiene muchos usos, y las cosas se ponen mejores si usamos Azure Cosmos DB. Por lo que te recomiendo que busques más, experimentes y evalúa si es una tecnología para tu proyecto.

Top comments (0)