At Monosi, we recently set up our internal data stack to fully enable data collection and metrics tracking. I figured a post like this may be useful for earlier stage companies that are in the process of setting up their own pipelines as they start tracking metrics and becoming more data driven.
This post is a high level overview of the technologies we are using and why we chose them. If you’re interested in a more technical overview or tutorial with actual Terraform files to spin up a replica stack, comment below and I can write up a more detailed post.
Technologies Used
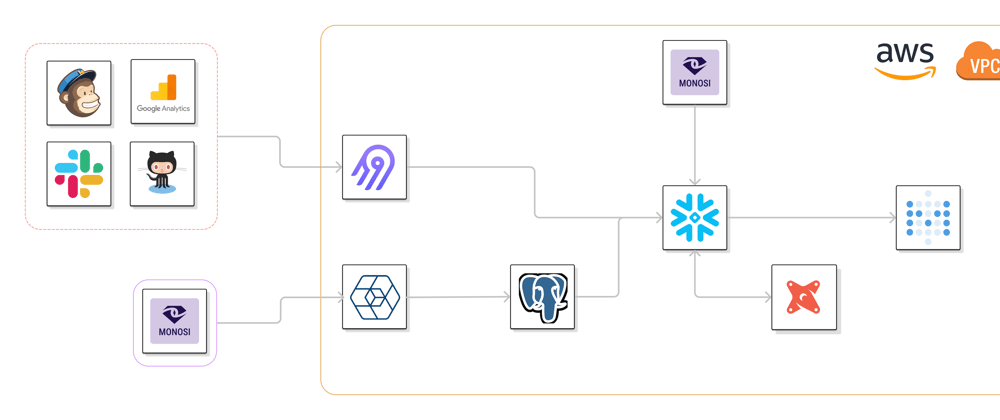
Monosi is an open source data observability platform, therefore our stack is composed mostly of open source technologies. Our current stack looks like:

Technologies include Snowplow, Airbyte, PostgreSQL, dbt, Snowflake, Metabase, and Monosi itself. All of it is hosted on AWS running in a VPC.
Data Collection / Extraction / Ingestion
There are two ways we collect data and ingest it into our pipeline.
First, we have data coming in from various third party tools such as Google Analytics, MailChimp, Github, Slack, etc. For extraction we use Airbyte.

We chose Airbyte because of their open source self-hosted offering and their connector flexibility. There are other open source tools in the market like StitchData or Meltano but have limitations as discussed in this post by the Airbyte team. If you don’t want to self host extraction, consider Fivetran.

We also have telemetry set up on our Monosi product which is collected through Snowplow,. As with Airbyte, we chose Snowplow because of its open source offering and because of their scalable event ingestion framework. There are other open source options to consider including Jitsu and RudderStack or closed source options like Segment. Since we started building our product with just a CLI offering, we didn’t need a full CDP solution so we chose Snowplow.
Data Storage
To store our collected data, we use a Snowflake data warehouse for all final data collection and a PostgreSQL database as an event destination.

All data from third party tools extracted with Airbyte is piped into Snowflake. We chose Snowflake because it’s easy to get started with, has a simple UX, and we use it internally for testing. Snowflake offers a free trial to quickly get started with and provides an intuitive UI. Since Monosi supports a Snowflake integration, it also makes development and testing easier.

All events collected with Snowplow are piped into a PostgreSQL database. This is separate because we wanted an individual database to act as storage for product event collection and it was quick to setup with Snowplow.

The setup also enables us to sync all of our event data to the data warehouse with Airbyte and perform necessary transformations on the data with dbt cloud.
Data Visualization / Analysis

To analyze the data stored in Snowflake and Postgres, we use Metabase. We chose Metabase because of it’s open source offering and easy to use interface. Other open source tools like Lightdash and Superset exist which we may add to the stack as our data team grows.
Data Reliability

As a data driven company, we need to make sure that our data is flowing reliably from extraction to visualization. It is important to have our metrics up to date and accurately defined at all times. Hence, when a certain part of the data stack stops working or changes (e.g. event ingestion, data extraction, schema updates) we need to be aware of what happened and why.
This is where our own tool, Monosi, comes in. To ensure data reliability within our stack, we’ve deployed our own internal instance of Monosi. With Monosi, we get alerted if anomalies occur in our data and can perform root cause analysis.
Other Tooling
There are other tools that we will have to adopt in the future but haven’t yet due to lack of necessity. Specifically, one category that is popular in modern data stacks is Reverse ETL (Hightouch, Census, or Grouparoo). We currently don’t have a usecase for piping data back into 3rd party tools but it will definitely come up in the future.
Wrapping up
Thanks for reading the overview of what our startup data stack looks like! If you have any questions about the setup or would like to see a more in depth post with actual Terraform files that handle both service creation and networking, leave a comment below!





Top comments (0)