Virtual machines (VMs) are the basic building block of cloud infrastructure - all cloud products like databases, orchestrators, message queues, functions and others are based on them. Many companies also use virtual machines as the foundation of their cloud landscape, running all sorts of services and applications on them.
In this article, I will explain ways and approaches for scaling VMs.
Virtual machines give the user more power and control over the environment and applications, but require greater skill and more atomic configuration. Therefore, scaling a system based on virtual machines is less flexible than the alternatives I will be discussing in other articles. So how do you configure virtual machine scaling to increase resource utilization on the one hand, but on the other hand be prepared for peaks in load?
There are several ways to solve this problem:
- manual scaling;
- automatic scaling.
Let's go into more detail.
Manual Scaling
When operating virtual machines, a situation may arise when the resources allocated to them (CPU, RAM) become insufficient. To solve the problem, manual scaling is performed - a set of actions that the administrator takes to change the amount of system resources, usually upwards.
But what exactly do you need to do? There are two main ways of scaling in this case:
- vertical scaling - changing the resources of a single machine;
- horizontal scaling - changing the number of machines without changing their configuration.
Vertical Scaling
When scaling vertically, you can change the main resources of the machine - CPU and RAM. This usually requires stopping and then restarting the virtual machine. You can also change the size of the virtual disk mounted to the machine, but in this case, you will need to make changes to the file system as well.
Vertical scaling is widely used for partition intolerant (CA) systems, which can only run in a single instance. Examples of such systems are classical databases like PostgreSQL and MySQL, as well as applications based on a monolithic architecture.
This is the easiest solution when scaling, since it does not require any changes to the applications. It is the first thing to go to when your system lacks resources.
However, server costs increase non-linearly as resources increase, so at a certain point, this type of scaling becomes too expensive. If you need to further scale your system, horizontal scaling is the way to go.
Horizontal Scaling
This type of scaling assumes that as the load changes, the number of servers handling that load changes proportionally, while the configuration of the machines remains the same. To do this, you can either simply create additional machines manually, or create them as part of an unmanaged instance group.
In the first case, the administrator is responsible for creating and configuring the new virtual machine and putting it into operation. Using instance group, on the other hand, makes the process somewhat easier, as the machine is created from a template with a fixed configuration. However, regardless of the way new machines are created, the development of a horizontally scalable system has a number of complexities:
- the application must support multiple replicas running in parallel;
- the infrastructure must be able to deliver data to all replicas;
- the infrastructure must strive to distribute the load evenly.
Consideration of these complexities deserves a separate article, but today's systems are evolving in this direction.

However, manual changes can lead to untimely responses to load changes. You may miss when the load has increased, and thus lose some requests or data, which can lead to serious business losses. On the other hand, a decrease in load can also go unnoticed, causing purchased servers to sit idle without load.
To make the system more self-sufficient and able to respond quickly to load changes, it is worth taking advantage of automatic scaling.
Automatic Scaling
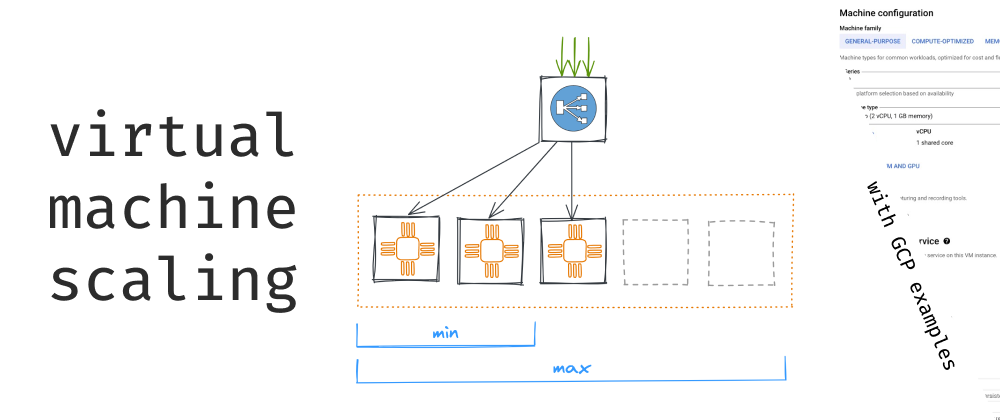
Automatic scaling involves running virtual machines within a managed instance group. Such a group independently monitors the state of the machines in the group and the distribution of load on them. When load changes, the group decides whether to add or remove machines to the group.
The criteria on the basis of which the group decides to scale are flexible. For example, it can be:
- CPU utilization threshold in percentage;
- number of http requests per machine;
- number of queued messages per machine;
- customizable metrics based on monitoring data.
Such options allow for flexible autoscaling depending on the processing scenarios of a particular system. In addition, many providers offer predictive scaling tools powered by analytics or machine learning. Such tools learn from real-world scenarios of machine usage and load changes, and optimize scaling in ways that increase resource utilization.
Managed Instance Group
To control a fleet of machines, a managed instance group is created with a specified setting. Often these settings include:
- location (region and zone or zones);
- scaling settings (type and parameters);
- network settings;
- virtual machine template.
The template must start the service at VM startup, so that it starts itself and gets configured if necessary (e.g., with service discovery). This is necessary so that when instances are automatically added to a group, they are started automatically. I usually use systemd for this but the cloud init will also work.
As for the scaling settings, you select the type and parameters, as well as the minimum and maximum number of machines in the group.

When the load is low, the number of instances will automatically decrease until it reaches a minimum number. This number will be kept until the load exceeds the threshold again.

On the other hand, when the load is high, the number of machines can reach a maximum, after which new machines will stop being added no matter how the system handles the load.

When creating an instance group, it is important to verify that your quotas and limits allow you to create the required number of machines and allocate the required number of network addresses to them.
Note that each machine in the group will have a different IP address. For the network communication with the instance group, load balancers are used, which I will talk about in the next article.
How To Set Up An Instance Group In Google Cloud
To set up a managed instance group in GCP, you must first create a virtual machine template with the application. To do this, just create a regular virtual machine in the Google Compute Engine based on the operating system of your choice. In my example I created a virtual machine based on Debian and installed the cpuburn application that I will use to emulate CPU load.

In order for the application to start automatically at the virtual machine startup, the service must be configured, in my example at /etc/systemd/system/cloud-scaling.service.
[Unit]
Description=Cloud Scaling Example
[Service]
ExecStart=+${PWD}/cpuburn-web -p 80
[Install]
WantedBy=multi-user.target
And started.
sudo systemctl daemon-reload
sudo systemctl enable --now cloud-scaling
The virtual machine must then be stopped in order to create an image based on its disk.

Next go to Instance templates and create a new one. You also need to enable HTTP traffic in firewall settings.

Change boot disk to the image you've just created.

Now we have everything we need to create an instance group based on this template.

Specify the minimum and maximum number of machines in the group, add one or more autoscaling criteria.

After the group is created, one virtual machine will be started, matching the minimum number.
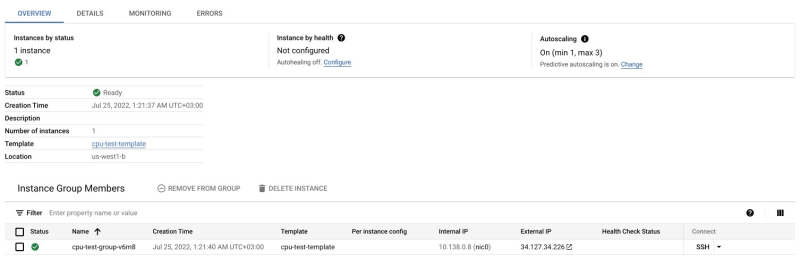
Let's burn some CPU! I'll trigger cpuburn application on the node and see what happens next.

The monitoring tab shows the dynamics of adding virtual machines, as well as changes in the total CPU utilization - when cpuburn started, it jumped up dramatically, but after adding new machines ( and therefore new resources) fell down again.

After disabling cpuburn, the instance group removes unused machines after a while...

...going back to the minimum number again.

Looking at the metrics again, we can see the history of changes in the virtual machine count in the group.

With these simple steps, you can configure a fault-tolerant system capable of withstanding large load spikes. The flexibility of the scaling criteria allows you to adjust for different usage scenarios and different types of input data.
However, the low speed of creating and deleting instances makes this tool inconvenient for systems with sudden jumps in load, demanding to process the maximum number of requests. For such tasks, other cloud products are better suited, which I will describe in the following articles.





Latest comments (0)