
Sandboxing in Linux with zero lines of code
This is a repost of my post from the Cloudflare Blog
Modern Linux operating systems provide many tools to run code more securely. There are namespaces (the basic building blocks for containers), Linux Security Modules, Integrity Measurement Architecture etc.
In this post we will review Linux seccomp and learn how to sandbox any (even a proprietary) application without writing a single line of code.

Tux by Iwan Gabovitch, GPL
Sandbox, Simplified Pixabay License
Linux system calls
System calls (syscalls) is a well-defined interface between userspace applications and the operating system (OS) kernel. On modern operating systems most applications provide only application-specific logic as code. Applications do not, and most of the time cannot, directly access low-level hardware or networking, when they need to store data or send something over the wire. Instead they use system calls to ask the OS kernel to do specific hardware and networking tasks on their behalf:
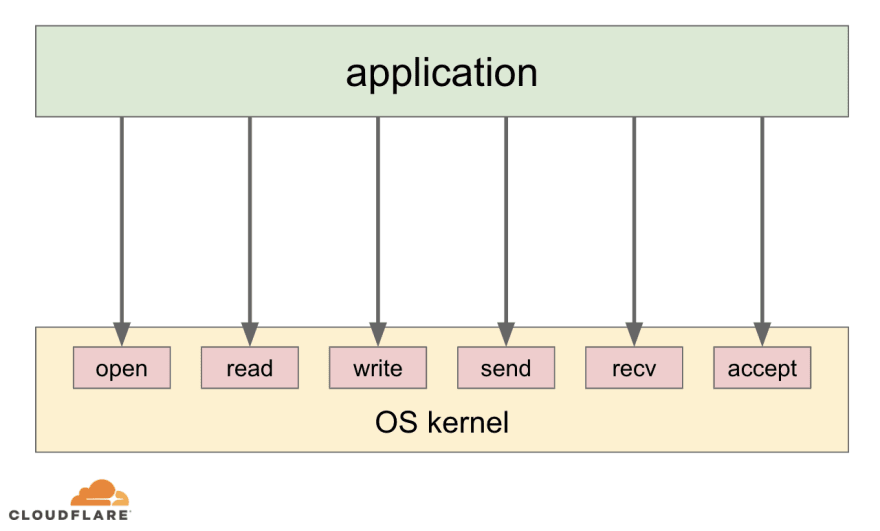
Apart from providing a generic high level way for applications to interact with the low level hardware, the system call architecture allows the OS kernel to manage available resources between applications as well as enforce policies, like application permissions, networking access control lists etc.
Linux seccomp
Linux seccomp is yet another syscall on Linux, but it is a bit special, because it influences how the OS kernel will behave when the application uses other system calls. By default, the OS kernel has almost no insight into userspace application logic, so it provides all the possible services it can. But not all applications require all services. Consider an application which converts image formats: it needs the ability to read and write data from disk, but in its simplest form probably does not need any network access. Using seccomp an application can declare its intentions in advance to the Linux kernel. For this particular case it can notify the kernel that it will be using the read and write system calls, but never the send and recv system calls (because its intent is to work with local files and never with the network). It’s like establishing a contract between the application and the OS kernel:

But what happens if the application later breaks the contract and tries to use one of the system calls it promised not to use? The kernel will “penalise” the application, usually by immediately terminating it. Linux seccomp also allows less restrictive actions for the kernel to take:
- instead of terminating the whole application, the kernel can be requested to terminate only the thread, which issued the prohibited system call
- the kernel may just send a
SIGSYSsignal to the calling thread - the seccomp policy can specify an error code, which the kernel will then return to the calling application instead of executing the prohibited system call
- if the violating process is under ptrace (for example executing under a debugger), the kernel can notify the tracer (the debugger) that a prohibited system call is about to happen and let the debugger decide what to do
- the kernel may be instructed to allow and execute the system call, but log the attempt: this is useful, when we want to verify that our seccomp policy is not too tight without the risk of terminating the application and potentially creating an outage
Although there is a lot of flexibility in defining the potential penalty for the application, from a security perspective it is usually best to stick with the complete application termination upon seccomp policy violation. The reason for that will be described later in the examples in the post.
So why would the application take the risk of being abruptly terminated and declare its intentions beforehand, if it can just be “silent” and the OS kernel will allow it to use any system call by default? Of course, for a normal behaving application it makes no sense, but it turns out this feature is quite effective to protect from rogue applications and arbitrary code execution exploits.
Imagine our image format converter is written in some unsafe language and an attacker was able to take control of the application by making it process some malformed image. What the attacker might do is to try to steal some sensitive information from the machine running our converter and send it to themselves via the network. By default, the OS kernel will most likely allow it and a data leak will happen. But if our image converter “confined” (or sandboxed) itself beforehand to only read and write local data the kernel will terminate the application when the latter tries to leak the data over the network thus preventing the leak and locking out the attacker from our system!
Integrating seccomp into the application
To see how seccomp can be used in practice, let’s consider a toy example program
myos.c:
#include <stdio.h>
#include <sys/utsname.h>
int main(void)
{
struct utsname name;
if (uname(&name)) {
perror("uname failed: ");
return 1;
}
printf("My OS is %s!\n", name.sysname);
return 0;
}
This is a simplified version of the uname command line tool, which just prints your operating system name. Like its full-featured counterpart, it uses the uname system call to actually get the name of the current operating system from the kernel. Let’s see it action:
$ gcc -o myos myos.c
$ ./myos
My OS is Linux!
Great! We’re on Linux, so can further experiment with seccomp (it is a Linux-only feature). Notice that we’re properly handling the error code after invoking the uname system call. However, according to the man page it can only fail, when the passed in buffer pointer is invalid. And in this case the set error number will be “EINVAL”, which translates to invalid parameter. In our case, the “struct utsname” structure is being allocated on the stack, so our pointer will always be valid. In other words, in normal circumstances the uname system call should never fail in this particular program.
To illustrate seccomp capabilities we will add a “sandbox” function to our program before the main logic
myos_raw_seccomp.c:
#include <linux/seccomp.h>
#include <linux/filter.h>
#include <linux/audit.h>
#include <sys/ptrace.h>
#include <sys/prctl.h>
#include <stdlib.h>
#include <stdio.h>
#include <stddef.h>
#include <sys/utsname.h>
#include <errno.h>
#include <unistd.h>
#include <sys/syscall.h>
static void sandbox(void)
{
struct sock_filter filter[] = {
/* seccomp(2) says we should always check the arch */
/* as syscalls may have different numbers on different architectures */
/* see https://fedora.juszkiewicz.com.pl/syscalls.html */
/* for simplicity we only allow x86_64 */
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, (offsetof(struct seccomp_data, arch))),
/* if not x86_64, tell the kernel to kill the process */
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, AUDIT_ARCH_X86_64, 0, 4),
/* get the actual syscall number */
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, (offsetof(struct seccomp_data, nr))),
/* if "uname", tell the kernel to return EPERM, otherwise just allow */
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K, SYS_uname, 0, 1),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ERRNO | (EPERM & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_ALLOW),
BPF_STMT(BPF_RET | BPF_K, SECCOMP_RET_KILL),
};
struct sock_fprog prog = {
.len = (unsigned short) (sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
/* see seccomp(2) on why this is needed */
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("PR_SET_NO_NEW_PRIVS failed");
exit(1);
};
/* glibc does not have a wrapper for seccomp(2) */
/* invoke it via the generic syscall wrapper */
if (syscall(SYS_seccomp, SECCOMP_SET_MODE_FILTER, 0, &prog)) {
perror("seccomp failed");
exit(1);
};
}
int main(void)
{
struct utsname name;
sandbox();
if (uname(&name)) {
perror("uname failed");
return 1;
}
printf("My OS is %s!\n", name.sysname);
return 0;
}
To sandbox itself the application defines a BPF program, which implements the desired sandboxing policy. Then the application passes this program to the kernel via the seccomp system call. The kernel does some validation checks to ensure the BPF program is OK and then runs this program on every system call the application makes. The results of the execution of the program is used by the kernel to determine if the current call complies with the desired policy. In other words the BPF program is the “contract” between the application and the kernel.
In our toy example above, the BPF program simply checks which system call is about to be invoked. If the application is trying to use the uname system call we tell the kernel to just return a EPERM (which stands for “operation not permitted”) error code. We also tell the kernel to allow any other system call. Let’s see if it works now:
$ gcc -o myos myos_raw_seccomp.c
$ ./myos
uname failed: Operation not permitted
uname failed now with the EPERM error code and EPERM is not even described as a potential failure code in the uname manpage! So we know now that this happened because we “told” the kernel to prohibit us using the uname syscall and to return EPERM instead. We can double check this by replacing EPERM with some other error code, which is totally inappropriate for this context, for example ENETDOWN (“network is down”). Why would we need the network to be up to just get the currently executing OS? Yet, recompiling and rerunning the program we get:
$ gcc -o myos myos_raw_seccomp.c
$ ./myos
uname failed: Network is down
We can also verify the other part of our “contract” works as expected. We told the kernel to allow any other system call, remember? In our program, when uname fails, we convert the error code to a human readable message and print it on the screen with the perror function. To print on the screen perror uses the write system call under the hood and since we can actually see the printed error message, we know that the kernel allowed our program to make the write system call in the first place.
seccomp with libseccomp
While it is possible to use seccomp directly, as in the examples above, BPF programs are cumbersome to write by hand and hard to debug, review and update later. That’s why it is usually a good idea to use a more high-level library, which abstracts away most of the low-level details. Luckily such a library exists: it is called libseccomp and is even recommended by the seccomp man page.
Let’s rewrite our program’s sandbox() function to use this library instead:
myos_libseccomp.c:
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <sys/utsname.h>
#include <seccomp.h>
#include <err.h>
static void sandbox(void)
{
/* allow all syscalls by default */
scmp_filter_ctx seccomp_ctx = seccomp_init(SCMP_ACT_ALLOW);
if (!seccomp_ctx)
err(1, "seccomp_init failed");
/* kill the process, if it tries to use "uname" syscall */
if (seccomp_rule_add_exact(seccomp_ctx, SCMP_ACT_KILL, seccomp_syscall_resolve_name("uname"), 0)) {
perror("seccomp_rule_add_exact failed");
exit(1);
}
/* apply the composed filter */
if (seccomp_load(seccomp_ctx)) {
perror("seccomp_load failed");
exit(1);
}
/* release allocated context */
seccomp_release(seccomp_ctx);
}
int main(void)
{
struct utsname name;
sandbox();
if (uname(&name)) {
perror("uname failed: ");
return 1;
}
printf("My OS is %s!\n", name.sysname);
return 0;
}
Our sandbox() function not only became shorter and much more readable, but also provided the ability to reference syscalls in our rules by names and not internal numbers as well as not having to deal with other quirks, like setting PR_SET_NO_NEW_PRIVS bit and dealing with system architectures.
It is worth noting we have modified our seccomp policy a bit. In the raw seccomp example above we instructed the kernel to return an error code when the application tries to execute a prohibited syscall. This is good for demonstration purposes, but in most cases a stricter action is required. Just returning an error code and allowing the application to continue gives the potentially malicious code a chance to bypass the policy. There are many syscalls in Linux and some of them do the same or similar things. For example, we might want to prohibit the application to read data from disk, so we deny the read syscall in our policy and tell the kernel to return an error code instead. However, if the application does get exploited, the exploit code/logic might look like below:
…
if (-1 == read(fd, buf, count)) {
/* hm… read failed, but what about pread? */
if (-1 == pread(fd, buf, count, offset) {
/* what about readv? */ ...
}
/* bypassed the prohibited read(2) syscall */
}
…
Wait what?! There is more than one read system call? Yes, there are read, pread, readv as well as more obscure ones, like io_submit and io_uring_enter. Of course, it is our fault for providing incomplete seccomp policy, which does not block all possible read syscalls. But if at least we had instructed the kernel to terminate the process immediately upon violation of the first plain read, the malicious code above would not have the chance to be clever and try other options.
Given the above in the libseccomp example we have a stricter policy now, which tells the kernel to terminate the process upon the policy violation. Let’s see if it works:
$ gcc -o myos myos_libseccomp.c -lseccomp
$ ./myos
Bad system call
Notice that we need to link against libseccomp when compiling the application. Also, when we run the application, we don’t see the uname failed: Operation not permitted error output anymore, because we don’t give the application the ability to even print a failure message. Instead, we see a Bad system call message from the shell, which tells us that the application was terminated with a SIGSYS signal. Great!
zero code seccomp
The previous examples worked fine, but both of them have one disadvantage: we actually needed to modify the source code to embed our desired seccomp policy into the application. This is because seccomp syscall affects the calling process and its children, but there is no interface to inject the policy from “outside”. It is expected that developers will sandbox their code themselves as part of the application logic, but in practice this rarely happens. When developers are starting a new project, most of the time the focus is on primary functionality and security features are usually either postponed or omitted altogether. Also, most real-world software is usually written using some high-level programming language and/or a framework, where the developers do not deal with the system calls directly and probably are even unaware which system calls are being used by their code.
On the other hand we have system operators, sysadmins, SRE and other folks, who run the above code in production. They are more incentivized to keep production systems secure, thus would probably want to sandbox the services as much as possible. But most of the time they don’t have access to the source code. So there are mismatched expectations: developers have the ability to sandbox their code, but are usually not incentivized to do so and operators have the incentive to sandbox the code, but don’t have the ability.
This is where “zero code seccomp” might help, where an external operator can inject the desired sandbox policy into any process without needing to modify any source code. Systemd is one of the popular implementations of a “zero code seccomp” approach. Systemd-managed services can have a SystemCallFilter= directive defined in their unit files listing all the system calls the managed service is allowed to make. As an example, let’s go back to our toy application without any sandboxing code embedded:
$ gcc -o myos myos.c
$ ./myos
My OS is Linux!
Now we can run the same code with systemd, but prohibit the application for using uname without changing or recompiling any code (we’re using systemd-run to create an ephemeral systemd service unit for us):
$ systemd-run --user --pty --same-dir --wait --collect --service-type=exec --property="SystemCallFilter=~uname" ./myos
Running as unit: run-u0.service
Press ^] three times within 1s to disconnect TTY.
Finished with result: signal
Main processes terminated with: code=killed/status=SYS
Service runtime: 6ms
We don’t see the normal My OS is Linux! output anymore and systemd conveniently tells us that the managed process was terminated with a SIGSYS signal. We can even go further and use another directive SystemCallErrorNumber= to configure our seccomp policy not to terminate the application, but return an error code instead as in our first seccomp raw example:
$ systemd-run --user --pty --same-dir --wait --collect --service-type=exec --property="SystemCallFilter=~uname" --property="SystemCallErrorNumber=ENETDOWN" ./myos
Running as unit: run-u2.service
Press ^] three times within 1s to disconnect TTY.
uname failed: Network is down
Finished with result: exit-code
Main processes terminated with: code=exited/status=1
Service runtime: 6ms
systemd small print
Great! We can now inject almost any seccomp policy into any process without the need to write any code or recompile the application. However, there is an interesting statement in the systemd documentation:
...Note that the
execve, exit, exit_group, getrlimit, rt_sigreturn, sigreturnsystem calls and the system calls for querying time and sleeping are implicitly whitelisted and do not need to be listed explicitly...
Some system calls are implicitly allowed and we don’t have to list them. This is mostly related to the way how systemd manages processes and injects the seccomp policy. We established earlier that seccomp policy applies to the current process and its children. So, to inject the policy, systemd forks itself, calls seccomp in the forked process and then execs the forked process into the target application. That’s why always allowing the execve system call is necessary in the first place, because otherwise systemd cannot do its job as a service manager.
But what if we want to explicitly prohibit some of these system calls? If we continue with the execve as an example, that can actually be a dangerous system call most applications would want to prohibit. Seccomp is an effective tool to protect the code from arbitrary code execution exploits, remember? If a malicious actor takes over our code, most likely the first thing they will try is to get a shell (or replace our code with any other application which is easier to control) by directing our code to call execve with the desired binary. So, if our code does not need execve for its main functionality, it would be a good idea to prohibit it. Unfortunately, it is not possible with the systemd SystemCallFilter= approach...
Introducing Cloudflare sandbox
We really liked the “zero code seccomp” approach with systemd SystemCallFilter= directive, but were not satisfied with its limitations. We decided to take it one step further and make it possible to prohibit any system call in any process externally without touching its source code, so came up with the Cloudflare sandbox. It’s a simple standalone toolkit consisting of a shared library and an executable. The shared library is supposed to be used with dynamically linked applications and the executable is for statically linked applications.
sandboxing dynamically linked executables
For dynamically linked executables it is possible to inject custom code into the process by utilizing the LD_PRELOAD environment variable. The libsandbox.so shared library from our toolkit also contains a so-called initialization routine, which should be executed before the main logic. This is how we make the target application sandbox itself:
-
LD_PRELOADtells the dynamic loader to load ourlibsandbox.soas part of the application, when it starts - the runtime executes the initialization routine from the
libsandbox.sobefore most of the main logic - our initialization routine configures the sandbox policy described in special environment variables
- by the time the main application logic begin executing, the target process has the configured seccomp policy enforced
Let’s see how it works with our myos toy tool. First, we need to make sure it is actually a dynamically linked application:
$ ldd ./myos
linux-vdso.so.1 (0x00007ffd8e1e3000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f339ddfb000)
/lib64/ld-linux-x86-64.so.2 (0x00007f339dfcf000)
Yes, it is . Now, let’s prohibit it from using the uname system call with our toolkit:
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libsandbox.so SECCOMP_SYSCALL_DENY=uname ./myos
adding uname to the process seccomp filter
Bad system call
Yet again, we’ve managed to inject our desired seccomp policy into the myos application without modifying or recompiling it. The advantage of this approach is that it doesn’t have the shortcomings of the systemd’s SystemCallFilter= and we can block any system call (luckily Bash is a dynamically linked application as well):
$ /bin/bash -c 'echo I will try to execve something...; exec /usr/bin/echo Doing arbitrary code execution!!!'
I will try to execve something...
Doing arbitrary code execution!!!
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libsandbox.so SECCOMP_SYSCALL_DENY=execve /bin/bash -c 'echo I will try to execve something...; exec /usr/bin/echo Doing arbitrary code execution!!!'
adding execve to the process seccomp filter
I will try to execve something...
Bad system call
The only problem here is that we may accidentally forget to LD_PRELOAD our libsandbox.so library and potentially run unprotected. Also, as described in the man page, LD_PRELOAD has some limitations. We can overcome all these problems by making libsandbox.so a permanent part of our target application:
$ patchelf --add-needed /usr/lib/x86_64-linux-gnu/libsandbox.so ./myos
$ ldd ./myos
linux-vdso.so.1 (0x00007fff835ae000)
/usr/lib/x86_64-linux-gnu/libsandbox.so (0x00007fc4f55f2000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fc4f5425000)
/lib64/ld-linux-x86-64.so.2 (0x00007fc4f5647000)
Again, we didn’t need access to the source code here, but patched the compiled binary instead. Now we can just configure our seccomp policy as before without the need of LD_PRELOAD:
$ ./myos
My OS is Linux!
$ SECCOMP_SYSCALL_DENY=uname ./myos
adding uname to the process seccomp filter
Bad system call
sandboxing statically linked executables
The above method is quite convenient and easy, but it doesn’t work for statically linked executables:
$ gcc -static -o myos myos.c
$ ldd ./myos
not a dynamic executable
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libsandbox.so SECCOMP_SYSCALL_DENY=uname ./myos
My OS is Linux!
This is because there is no dynamic loader involved in starting a statically linked executable, so LD_PRELOAD has no effect. For this case our toolkit contains a special application launcher, which will inject the seccomp rules similarly to the way systemd does it:
$ sandboxify ./myos
My OS is Linux!
$ SECCOMP_SYSCALL_DENY=uname sandboxify ./myos
adding uname to the process seccomp filter
Note that we don’t see the Bad system call shell message anymore, because our target executable is being started by the launcher instead of the shell directly. Unlike systemd however, we can use this launcher to block dangerous system calls, like execve, as well:
$ sandboxify /bin/bash -c 'echo I will try to execve something...; exec /usr/bin/echo Doing arbitrary code execution!!!'
I will try to execve something...
Doing arbitrary code execution!!!
SECCOMP_SYSCALL_DENY=execve sandboxify /bin/bash -c 'echo I will try to execve something...; exec /usr/bin/echo Doing arbitrary code execution!!!'
adding execve to the process seccomp filter
I will try to execve something...
sandboxify vs libsandbox.so
From the examples above you may notice that it is possible to use sandboxify with dynamically linked executables as well, so why even bother with libsandbox.so? The difference becomes visible, when we start using not the “denylist” policy as in most examples in this post, but rather the preferred “allowlist” policy, where we explicitly allow only the system calls we need, but prohibit everything else.
Let’s convert our toy application back into the dynamically-linked one and try to come up with the minimal list of allowed system calls it needs to function properly:
$ gcc -o myos myos.c
$ ldd ./myos
linux-vdso.so.1 (0x00007ffe027f6000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f4f1410a000)
/lib64/ld-linux-x86-64.so.2 (0x00007f4f142de000)
$ LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libsandbox.so SECCOMP_SYSCALL_ALLOW=exit_group:fstat:uname:write ./myos
adding exit_group to the process seccomp filter
adding fstat to the process seccomp filter
adding uname to the process seccomp filter
adding write to the process seccomp filter
My OS is Linux
So we need to allow 4 system calls: exit_group:fstat:uname:write. This is the tightest “sandbox”, which still doesn’t break the application. If we remove any system call from this list, the application will terminate with the Bad system call message (try it yourself!).
If we use the same allowlist, but with the sandboxify launcher, things do not work anymore:
$ SECCOMP_SYSCALL_ALLOW=exit_group:fstat:uname:write sandboxify ./myos
adding exit_group to the process seccomp filter
adding fstat to the process seccomp filter
adding uname to the process seccomp filter
adding write to the process seccomp filter
The reason is sandboxify and libsandbox.so inject seccomp rules at different stages of the process lifecycle. Consider the following very high level diagram of a process startup:
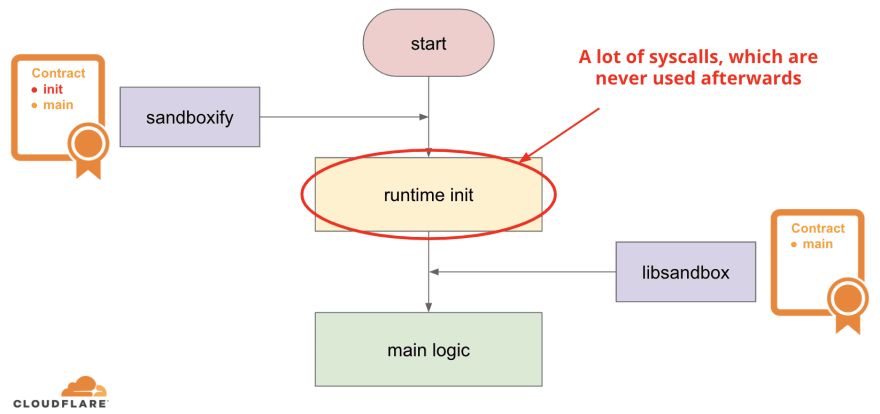
In a nutshell, every process has two runtime stages: “runtime init” and the “main logic”. The main logic is basically the code, which is located in the program main() function and other code put there by the application developers. But the process usually needs to do some work before the code from the main() function is able to execute - we call this work the “runtime init” on the diagram above. Developers do not write this code directly, but most of the time this code is automatically generated by the compiler toolchain, which is used to compile the source code.
To do its job, the “runtime init” stage uses a lot of different system calls, but most of them are not needed later at the “main logic” stage. If we’re using the “allowlist” approach for our sandboxing, it does not make sense to allow these system calls for the whole duration of the program, if they are only used once on program init. This is where the difference between libsandbox.so and sandboxify comes from: libsandbox.so enforces the seccomp rules usually after the “runtime init” stage has already executed, so we don’t have to allow most system calls from that stage. sandboxify on the other hand enforces the policy before the “runtime init” stage, so we have to allow all the system calls from both stages, which usually results in a bigger allowlist, thus wider attack surface.
Going back to our toy myos example, here is the minimal list of all the system calls we need to allow to make the application work under our sandbox:
$ SECCOMP_SYSCALL_ALLOW=access:arch_prctl:brk:close:exit_group:fstat:mmap:mprotect:munmap:openat:read:uname:write sandboxify ./myos
adding access to the process seccomp filter
adding arch_prctl to the process seccomp filter
adding brk to the process seccomp filter
adding close to the process seccomp filter
adding exit_group to the process seccomp filter
adding fstat to the process seccomp filter
adding mmap to the process seccomp filter
adding mprotect to the process seccomp filter
adding munmap to the process seccomp filter
adding openat to the process seccomp filter
adding read to the process seccomp filter
adding uname to the process seccomp filter
adding write to the process seccomp filter
My OS is Linux!
It is 13 syscalls vs 4 syscalls, if we’re using the libsandbox.so approach!
Conclusions
In this post we discussed how to easily sandbox applications on Linux without the need to write any additional code. We introduced the Cloudflare sandbox toolkit and discussed the different approaches we take at sandboxing dynamically linked applications vs statically linked applications.
Having safer code online helps to build a Better Internet and we would be happy if you find our sandbox toolkit useful. Looking forward to the feedback, improvements and other contributions!

Top comments (0)