What is Kafka?
The Apache Kafka website defines Kafka as
an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
so in a nutshell, apache kafka is a platform designed for streaming data as events.
Kafka uses pub/sub messaging model. In that model, messages are published to topics and consumers can subscribe to these topics. All the consumers will receive the message unlike queues where the message is received by only one of the consumers.
Architecture of Kafka:
Kafka has 4 main components:
1- Producer:
The producer is the publisher of the event. It can be on any platform and can be written in any language. The producer appends the event to the topic. Multiple producers can publish events to the same topic.
2- Consumer:
The consumer subscribes to the topic and multiple consumers can subscribe to the same topic and all subscribed consumers will receive the message.
3- Broker:
Host for the topic. The broker maintains the replication and partitioning of the topics (more on that later)
4- Topic:
The topic can be considered as a folder that stores the events. It's basically the place where the events are stored. Events are stored in topics as logs meaning that they are append only and are immutable. This allows for replaying the events on a specific topic.
Topics can also be divided to partitions where events are partitioned according to their keys. each consumer subscribes to a specific partition which allows for scaling the topics and distributing work among multiple instances of the same consumer. Each topic has a leader partition and 0 or more follower partitions. That structure is maintained by the broker.
Kafka also allows for replicating topics which makes it fault tolerant. The broker is responsible for managing the replication accross the cluster.
Now that we have an idea about Kafka, let's dive into Ksql and how it leverages kafka for live data processing.
What is Ksql?
Ksql is defined as
The event streaming database purpose-built for stream processing applications
Ksql is basically a database that's built on kafka streams. It allows developers to run queries that are very similar to sql queries but the queries can run realtime using the stream. In other words, ksql runs queries on the event log and the queries are run on every new instance of the data.
Ksql has two important concepts:
1- Streams: A stream is a sequence of data where events are appended to the stream in order. Once an event is in the stream it cannot be deleted nor updated.
2- Tables: A table is a representation of the current state based on the data in the stream. It can be changed realtime according to the data in the stream but it is mutable and the data can be updated or deleted.
let's take as an example a financial transaction where Alice has $500 in her bank account and Bob has $200 in his bank account
The initial table and streams would look like this:
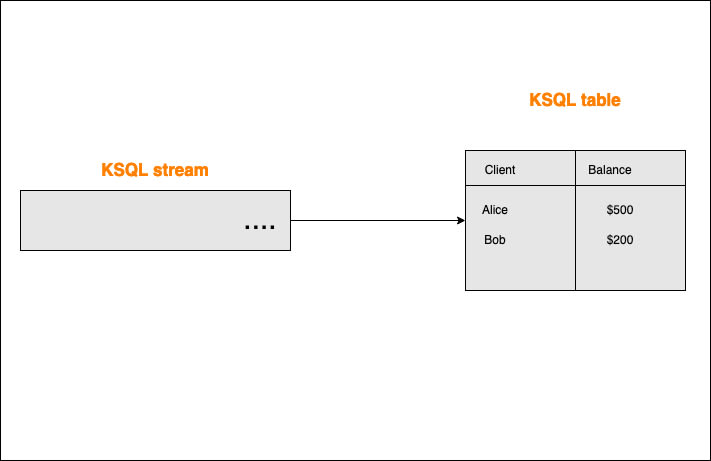
The arrow connecting the stream to the table represents that the table reads from that stream.
The stream currently has no new events and the table shows the current balance for both Alice and Bob.
Alice make a transfer to Bob's account and the event is published as "Alice sends $100 to Bob" the stream and table would then look like this:
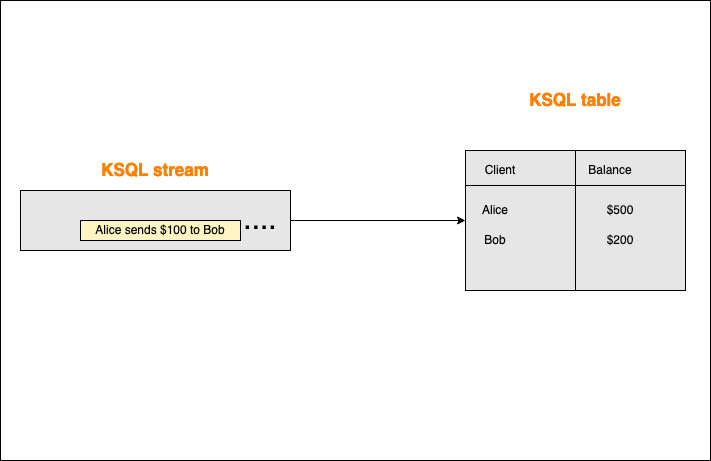
As soon as the stream receives the event, the table will update its values accordingly

Now in the table, Alice has $400 and Bob has $300. The event of Alice transferring that money is still on the stream and cannot be deleted from the stream. However, if for any reason we want to change the balance of Bob for example, we can do that directly to the table without changing the stream.
Using Ksql:
Ksql is very similar to SQL in syntax. For example creating a stream from a topic can be done using
CREATE STREAM transactions (
from_id BIGINT,
to_id BIGINT,
value DOUBLE
) WITH (
KAFKA_TOPIC = 'transactions-topic',
VALUE_FORMAT = 'JSON'
);
We can also create tables from streams:
CREATE TABLE users (
id BIGINT PRIMARY KEY
) WITH (
KAFKA_TOPIC = 'users-topic',
VALUE_FORMAT = 'JSON'
);
Furthermore, we can create streams from streams to filter the streams:
CREATE STREAM filtered AS
SELECT
a,
few,
columns
FROM source_stream;
We can also join 2 streams or join a stream with a table to add more information to the streams:
CREATE STREAM enriched AS
SELECT
cs.*,
u.name,
u.classification,
u.level
FROM clickstream cs
JOIN users u ON u.id = cs.userId;
We can keep creating streams and tables from each others to further refine the results and aggregate the data by using the above syntax CREATE TABLE AS and CREATE STREAM AS.
However, dealing with a stream is different than dealing with a table since streams can be infinite and we can't possibly run aggregations on infinite data; that's why we have Windowing
Windowing:
Since we're dealing with streams in KSQL we need to have a time window to run some queries on streams. Every record on the stream has a timestamp which can be used for windowing the queries.
A stream would look like this:

A window over the stream would look like this:
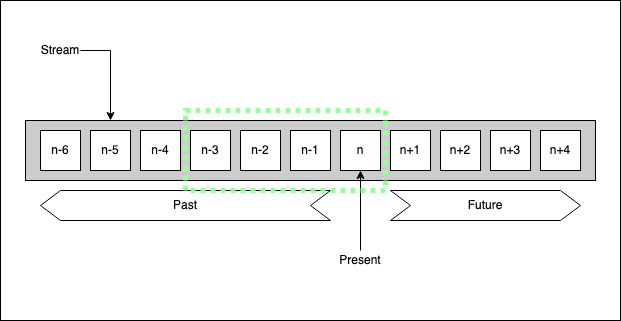
Windowed queries run on the records inside the window and the result will change as the window shifts where the table will have a new row for each window.
There are different types of windows in Ksql which are:
1- Tumbling: The window has a fixed size and the windows don't overlap. It takes size as a paremeter.

2- Hopping: The window is fixed in size but windows can overlap. It takes size and advance as parameters where advance is the value the window moves with. for example, you can have a window of size 40 seconds that advances by 20 seconds.

3- Session: The window has a fixed size. It starts from the first entry of a particular key it doesn't shift until a new message with the same key happens within a specified period of time or inactivity gap. the inactivity gap is a parameter.
Conclusion:
Kafka is a powerful event-streaming tool and using KSQL leverages kafka by allowing for running queries directly on the stream and getting live statistics and analytics about the system with simple SQL-like queries.
Resources:
2- KSQL: Streaming SQL Engine for Apache Kafka
3- Developer to Architect: How Kafka Differs From Standard Messaging
4- https://aws.amazon.com/msk/what-is-kafka/
5- Kafka Architecture & Internal by Narayan Kumar
7- KSQL: Streaming SQL for Apache Kafka

Top comments (0)