In this blog post I’ll introduce a GUI-driven approach to creating Apache Airflow workflows that implement machine learning pipelines using Jupyter notebooks and Python scripts.
Apache Airflow is an open source workflow management platform that allows for programmatic creation, scheduling, and monitoring of workflows. In Apache Airflow a workflow (or pipeline) is called a Directed Acyclic Graph (DAG) that comprises of one or more related tasks. A task represents a unit of work (such as the execution of a Python script) and is implemented by an operator. Airflow comes with built-in operators, such as the PythonOperator, and can be extended using provider packages.
Let's say you want to use an Apache Airflow deployment on Kubernetes to periodically execute a set of notebooks or scripts that load and process data in preparation for machine learning model training.

Without going into details how, you could implement this workflow using the generic PythonVirtualEnvOperator to run the Python script and the special purpose PapermillOperator to run the notebook. If the latter doesn't meet your needs, you'd have to implement its functionality yourself by developing code that performs custom pre-processing, uses the papermill Python package to run the notebook, and performs custom post-processing.
An easier way to create a pipeline from scripts and notebooks is to use Elyra's Visual Pipeline Editor. This editor lets you assemble pipelines by dragging and dropping supported files onto the canvas and defining their dependencies.

Once you've assembled the pipeline and are ready to run it, the editor takes care of generating the Apache Airflow DAG code on the fly, eliminating the need for any coding.
If you are new to the Elyra open source project, take a look at the overview documentation.
The pipeline editor can also generate code that runs the pipeline in JupyterLab or on Kubeflow Pipelines for greater flexibility.

Local execution is primarily intended for use during development or if no Kubeflow Pipelines or Apache Airflow deployment is available.
This article outlines how you would go about creating a pipeline from a set of files and running it on Apache Airflow. We have published a set of tutorials that provide step-by-step instructions for each one of the supported runtime environments.
Prerequisites
- JupyterLab 3.0 with the Elyra extensions v2.1 (or later) installed
- Apache Airflow v1.10.8 or later but not including v2
- Must be configured to use the Kubernetes Executor with git-sync enabled
- Must be enabled for Elyra
Creating a pipeline
Pipelines are created in Elyra with the Visual Pipeline Editor by
- adding Python scripts or notebooks
- configuring their execution properties
- connecting the files to define dependencies

Each pipeline node represents a task in the DAG and is executed in Apache Airflow with the help of a custom NotebookOp operator. The operator also performs pre- and post processing operations, that, for example, make it possible to share data between multiple tasks using shared cloud storage.
Node properties define the container image that the operator will run in, optional CPU, GPU, or RAM resource requests, file dependencies, environment variables, and output files. Output files are files that need to be preserved after the node was processed. For example, a notebook that trains a model might want to save model files for later consumption, such as deployment.
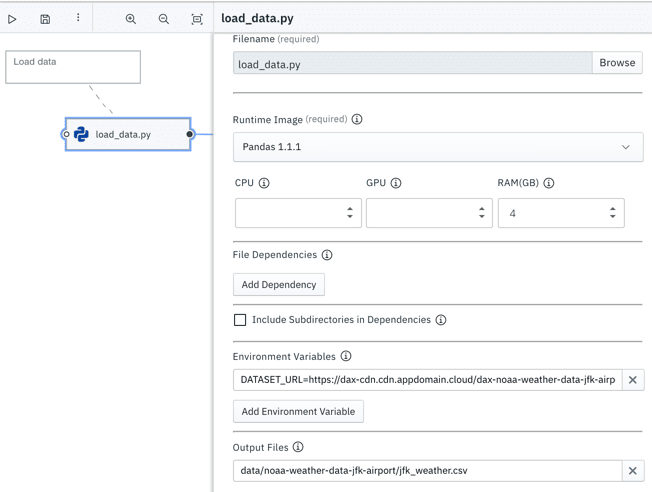
A pipeline that comprises only of file nodes (nodes that execute a Python script or Jupyter notebook) can be run as-is locally in JupyterLab, or remotely in Apache Airflow or Kubeflow Pipelines.
Future releases of Elyra might provide support for node types that are specific to a runtime platform. Pipelines that include such nodes can take advantage of platform specific features but won't be portable.
A pipeline definition does not include any target environment
information, such as the host name of the Apache Airflow webserver. This information is encapsulated in runtime [environment] configurations.
Creating a runtime configuration
In Elyra runtime configurations store metadata that describes the target environment where pipelines are executed. A runtime configuration for Apache Airflow includes
- connectivity information for the Airflow web server,
- details about the GitHub repository, where DAGs are stored,
- connectivity information for the cloud storage service, which Elyra uses to store pipeline-run specific artifacts

Elyra supports repositories on github.com and GitHub Enterprise. Note that some of the runtime configuration information is embedded in the generated DAGs to provide the
NotebookOpoperator access to the configured cloud storage. Therefore you should always use a private repository to store DAGs that were produced by Elyra.
Running pipelines on Apache Airflow
Once you created a pipeline and a runtime configuration for your Apache Airflow cluster, you are ready to run the pipeline.

When you submit a pipeline for execution from the Visual Pipeline Editor, Elyra performs the following pre-processing steps:
- package the input artifacts (files and dependencies) for each task in a compressed archive
- upload the archives to the cloud storage bucket referenced in the runtime configuration
- generate a DAG, comprising of one task for each notebook or Python script
- upload DAG to the GitHub repository that Apache Airflow is monitoring
The uploaded DAG is pre-configured to run only once.
Within limits you can customize the generated DAG by exporting the pipeline instead of running it. The main difference between running and exporting a pipeline for Apache Airflow is that the latter does not upload the generated DAG file to the GitHub repository.
Monitoring a pipeline run on Apache Airflow
How soon a DAG is executed after it was uploaded to the repository depends on the git-sync refresh time interval setting and the scheduler in your Apache Airflow configuration.


Each notebook or Python script in the pipeline is executed as a task using Elyra's NotebookOp operator, in the order defined by it's dependencies.
Once a task has been processed, its outputs can be downloaded from the associated cloud storage bucket. Outputs include the completed notebooks, an HTML version of each notebook, a log file for each Python script, and files that were declared as output files.

Getting started
If you have already have access to an v1.10 Apache Airflow cluster you can start running pipelines in minutes:
- Prepare your cluster for use by Elyra.
- Install Elyra from PyPI or pull the ready-to-use container image.
- Step through the tutorial to learn how to create a pipeline, configure a pipeline, and run/export it.
If you are interested in running pipelines on Apache Airflow on the Red Hat OpenShift Container Platform, take a look at Open Data Hub. Open Data Hub is an open source project (just like Elyra) that should include everything you need to start running machine learning workloads in a Kubernetes environment.
Using Watson Studio services in pipelines
We've introduced pipelines in Elyra to make it easy to run notebooks or scripts as batch jobs, and thus automate common repetitive tasks.
The recently launched beta of IBM Watson Studio Orchestration Flow takes this a step further. The flow orchestrator integrates with various data and AI services in Watson Studio, enabling users to ingest data, or train, test and deploy machine learning models at scale.
The orchestration flow editor, which is shown in the screen capture below, is based on the Elyra canvas open source project.

Questions and feedback
We'd love to hear from you! You can reach us in the community chatroom, the discussion forum, or by joining our weekly community call.

Top comments (0)