So, my project for the ChiPy Mentorship program is: take the universe of NFL Running Backs and try to predict their contract value for their 2nd NFL contract. The reason for only predicting the 2nd NFL contract is that their first NFL contract is based on a mostly pre-determined system, where their 2nd contract is based off their performance in the NFL.
Unfortunately, this means that our number of samples to analyze in the post-2011 Collective Bargaining Agreement (CBA) era is approximately 100. (Side note - in 2011 a new 10 years CBA was negotiated which somewhat altered the system, so only contracts negotiated since then would be apples to apples).
As you will see below, when you only have 100 samples, using just about any method to analyze the data in order to predict a contract from a validation sample becomes almost a fool's errand. As of this post, and the methods will be more fully discussed below, we (my mentor and I) have tried: multiple linear regression, principle component analysis, decisions trees and K nearest neighbor. In addition, just on my end, I have also tried banging my head against the wall. More than once.
Ok, before I walk you through the methods we tried, you should know a little more about the data itself. For those 100 samples contracts, we have approximately 50 features of data for each one. Some are the 'normal' statistics people would associate with NFL running backs - total rushing yards for a given season, total receiving yards for a given season, total rushing touchdowns for a given season, etc. Some are 'advanced' statistics for running backs - yards per route run, yards after contact, tackles avoided and several others. Across each contract there about 50 statistical categories.
Multiple Linear Regression
So, before I would just willy nilly send all 50 features through linear regression, my mentor suggested just plotting a simple relationship plot with r^2 on the plot for each feature to see if that feature had any realistic chance of being relevant to the outcome. So, I did:
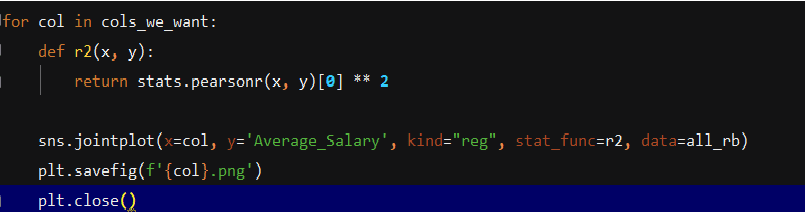
- cols_we_want is just a list of the column names that I wanted to check their relevance.
That code gave me 50 .png files that look like this:
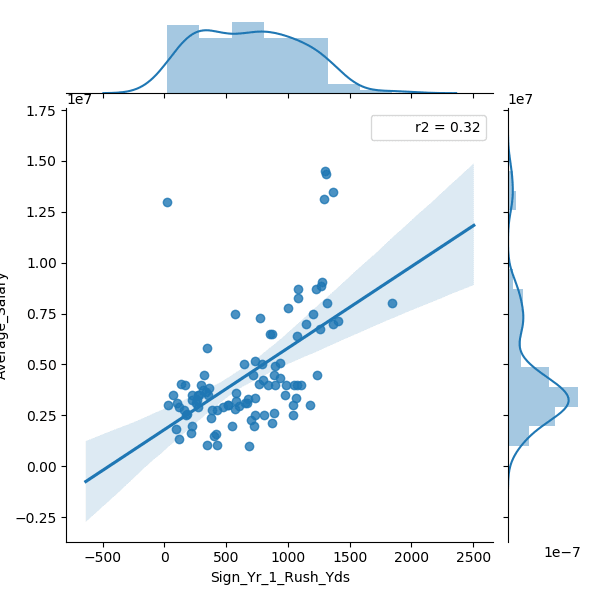
And with just a little bit of code, 50 features became about 8 - all of which I could have guessed before the computer did its math because they are the features which are used in the 'real world' in which these contracts are negotiated.
However, just to make sure that those features were indeed the most relevant, a little RFE (Recursive Feature Elimination - which basically ranks the features in terms of their relevance for predicting the outcome) was necessary:
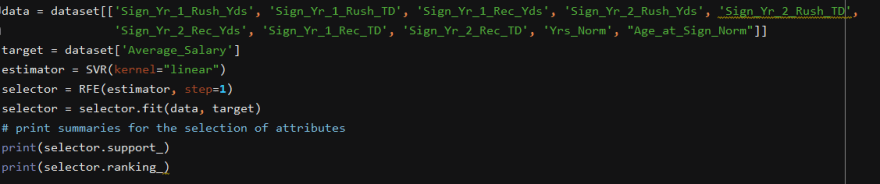
Which then gave me a listing of how relevant each feature was to the outcome - several columns rated as a '1', then '2' and so on - with a 1 being most relevant.
Brimming with confidence that our most relevant features would absolutely predict outcomes that were right on the money, I wrote the code to run linear regression with the level '1' features, then the level '1' and '2' features and so on:
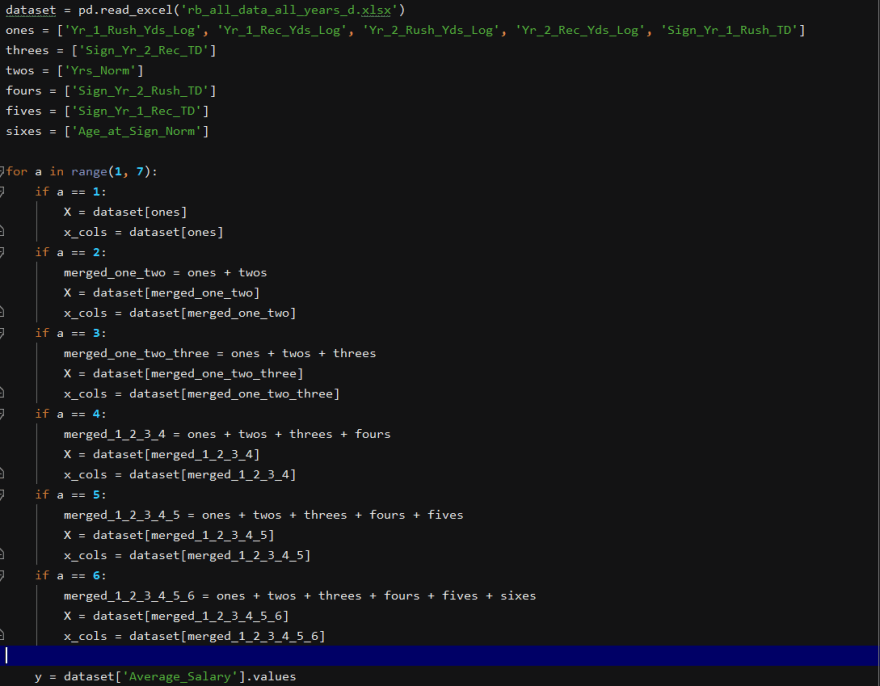
Unfortunately, this is when the fears of my mentor were first realized: Not having enough samples means not getting accurate predictions.
However, fear not dear reader, the world of data analysis has many other methods to try. And next on the list was PCA (Principal Component Analysis) - which to use a technical term - mushes the features together into as many or as little a number you want:
Unfortunately, once again not having enough samples means not getting accurate predictions.
But, where one door closes, another opens. Welcome to decision trees:
However, I'm sure by now you have guessed the theme of this post - not having enough samples means not getting accurate predictions.
Time to call in K nearest neighbor off the bench....which, funny enough should approximate what happens in the 'real world' anyway. When I negotiate a contract for a player I represent, I look at the other players at his position whom I believe to be the most statistically similar and use their contracts as a baseline for the contract I want for my player.
Tune in at the final presentations on December 12 to see how it all turns out. (If you miss it, don't worry - I'll make a final post as well).





Top comments (0)