What is software architecture?
A pattern or design that informs the developer where code should exist in a software development project. Basically, how you arrange your code for several purposes. Efficiency, organization, and less redundancy are some good reasons to create separate modules for your components. Modules are groups of similar collections of components. A component represent a group of use cases for a given entity. A entity is a specific data set, ie (widget, person, user, article, etc)
Wow that was a lot of jargon, if you don’t understand these terms that is ok, we are going to use some diagrams to help.
- Module — a collection of components
- Component — a group of functions or classes organized around a single idea
- Entity — a component that represents structured data
In this post, we will look at several architecture diagrams and discuss the pros and cons of each diagram. With functional thinking, we want to separate and minimize as many actions as possible and create and manage as many calculations as possible. We will talk about which architecture best suites this design.
The first and most common architecture pattern is called Model View Controller or MVC.
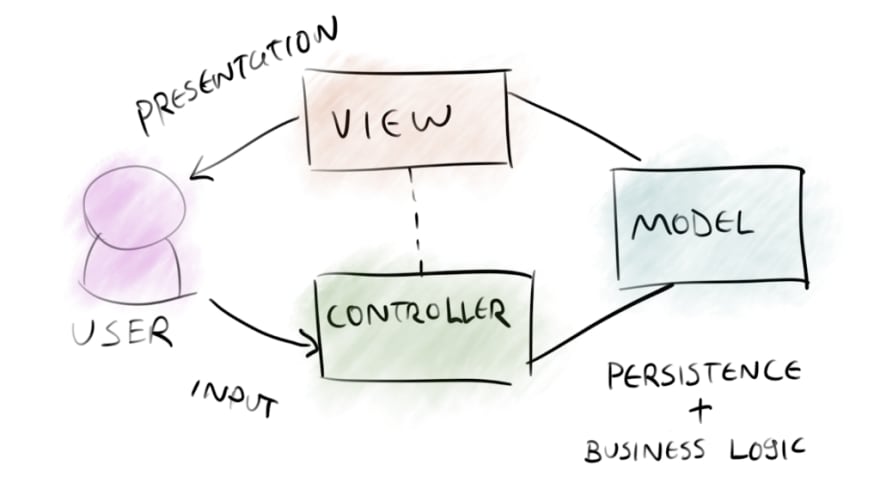
The MVC architecture with APIs primarily focuses on the Controllers and the Models, since the views are provided by the clients. This structure is stateless and very top down, a request comes in from the api server to a specific endpoint, that endpoint calls a controller, then the controller calls one to many models and performs the calculations for the request and returns a response. This approach appears to separate concerns in a clean way but if you apply functional thinking, you can see some challenges with this approach.
What is functional thinking?
Functional Thinking is the process of identifying code at the component level to be classified as actions, calculations or data. Data are facts, calculations are pure functions that given the same input, your function will always return the same output. Another way to think about calculations is that they contain no side effects. Finally, actions, these are components or functions that interact with external interfaces. Action output can vary based on when the action is executed and how many times. If your component calls an action, then it becomes an action. The fact that when a function calls an action, then it becomes an action can cause your code base to spread with side effects.
Examples
- Data — const user = () => ({ name: 'testuser', email: 'test@user.com' })
- Calculation — const add = (a,b) => a + b
- Action — const getUsers = async () => fetch('/users')
If we apply functional thinking to MVC?
How does MVC hold up to functional thinking? Well, models talk to interfaces for services, like databases and apis, controllers talk to api endpoints and handle requests and provide responses. So basically every component is an action, there are very few if any calculations in this design, at least the design does not create a separation mechanism to isolate calculations and data from actions. Without significant discipline and constant refactoring a MVC architecture can quickly become a huge trap for technical debt. You can quickly get into a pattern of linear growth or even negative growth.
Linear growth: As a software project’s complexity grows, additional human resources and time are required to provide additional features.
Negative growth: The inability to provide the additional features and enhancements after adding human resources and time.
Why does this matter? I like my MVC
The biggest reason this matters is called Technical Debt, over time this approach can become quite complex because it forces the team to constantly keep building and nesting actions, calculations, and data. As you try to refactor for reusability, the team creates more places the team has to touch to implement a feature. After a few years it can take weeks even months to implement features that once took hours or days. Often the teams only defense is to say no, or give us time to focus on bugs and technical debt, because the actions are everywhere the root cause of many bugs are very hard to find and symptoms appear all over the place.
MVC patterns are usually provided by application frameworks, these frameworks marry your code base, which means as the team you are often stuck with a given framework without significant effort to move to another technology.
Why is MVC so popular?
In my opinion MVC is popular because it is easy, and appears simple at first. But easy does not mean simple and simple does not mean easy. And over time the complexity starts to show and the tight coupling of side effects with business logic starts to stress the design and create a lot of extra work and effort for the development team to stay productive. Which leads to we need more developers and we need more project management etc. What do you think?
Flux Architecture or Reducer Architecture
In 2012,2013 the Facebook Development team introduced a pattern for state management. It is called the flux architecture. This architecture separates actions from calculations and data. Let take a look.

With flux you have the concept of a store, this store allows for interfaces to subscribe to notifications and dispatch, what it calls actions. Then each action is passed though a reduce function. The reduce function contains sets of pure calculations that results in an updated state object. Once the reduce process is complete the store notifies all of the subscribers of the change. The subscribers can then respond to that change and notify the outside through an interface. When applying this pattern to a stateless API, your api server does both the subscribe and dispatch process. Since the reducers can’t have any side effects, a middle layer is usually provided so the side effect can occur before the dispatch reaches the reduce function. These are called action creators and usually a thunk pattern is used to intercept the dispatch apply the action, then resume the dispatch to the reduce function.
Is the flux/reducer pattern a good fit for APIs?
The good is that is separates actions (side effects) from calculations (business logic). As far as data, the data is provided via a global state object, and with a stateless system like api’s it may not be the best fit. It certainly works, and does a great job at separating actions from calculations. The calculations are easy to test, but the features do get spread over several components, specifically actions and reducers, while they are loosely coupled, they need each other to complete the requested task. It can also be a bit weird on the implementation side, because you need to subscribe to the store, then dispatch the event.
function handleRequest(req, res) {
store.subscribe(() => res.json(store.state.foo))
store.dispatch({type: 'SHOW', payload: req.params.id})
}
Handling the response before you dispatch your action in a transaction mechanism.
What is my opinion about Flux/Reducer architecture and APIs?
All in all, I think the flux/reducer pattern is a better pattern than MVC for APIs, when you apply Functional Thinking, but I do think it can be confusing and hard to maintain over time, because there is so much indirection and there are so many components that have to modified to manage a single feature. Many developers refer to this as boilerplate and these issues have been somewhat resolved with React Toolkit and Redux Bundler. Your mileage may vary, one thing is for sure, by controlling the flow of application requests through a single interaction point, you do get traceability by default and the more calculations/pure functions/reducers you can leverage to apply your business logic, the more reliable the application becomes.
Onion Architecture
The onion architecture is a layered approach much like the layers of an onion, the inner layers represent business logic and calculations, while the outer layers represent side effects and services.

Like the reducer architecture your actions are separated from your calculations, but whats different with this approach, is the concept of separating general re-usable components from specific business components. In the diagram, the more specific components reside in the core modules and the more general components reside in the services modules. The onion architecture creates a matrix between specific and general and calculations and actions. Many actions are general and many calculations are specific. By stratifying your design you create a hierarchy to separate the components that should change more frequently and components that should change less frequency into two distinct areas. The effect is that over time you are changing business rules or calculations without having to touch implementation details like services and interfaces that naturally change less often. The result is flexibility, maintainability, extensibility, testability and reliability. You system become more reliable over time and the amount of effort to implement a feature from day one remains the same amount of effort to implement a feature on day 457 small.

While onion architecture drawings are busy and difficult to follow, maybe the above diagram will help. With functional thinking, you are focusing on separating your code from actions and calculations, but another core component of functional programming is to separate you application modules from general -> specific. When a module is specific to your problem domain, with the onion architecture, it should be pure, or a calculation or data. And a module with actions should be more general. The diagram above shows these modules as circles and the modules with side effects should be general, and the modules with pure functions should be specific.
How?
You may be thinking, if I have a user interface, an API, a database, how do possibly create pure functions/calculations without depending on side effects/actions coming from the user interface/api or from the database? There is no way, if my business logic is to create a blog post, it must depending on a database to store that record. There is a way and it is not as complex as it may sound. You may have to open your mind a bit and understand the concept of a function as value or first class functions.
Functions as Values or first class functions
The ability to pass a function as an argument and return a function as a result gives us the power of inversion of control. This means we can implement logic of future results that have not happened yet, they are loaded in a lazy fashion, because we pass the functions that contain the side effect code, but the side effect code does not run until we tell it to run. This allows us to inject a dependency into our business logic without a hard wired dependency. And that injection does not get executed thanks to algebraic data types (ADTs). These types, give us the ability to apply pure functions to the values in side the type using methods like map, chain, etc. As result we create a pipeline of pure calculation logic with not side effects or actions.
There are three ADTs that are worth knowing to achieve this flow:
- Task/Async — (see async video from evilsoft)
- Either — (see https://blog.hyper63.com/either-this-or-that/)
- Reader — (see video from evilsoft)
Still too abstract?
If still too abstract, but you want to learn more about how we approach the onion architecture, maybe check this video, where Tom Wilson implements an update feature from the outside in.
Yes, there is a lot to learn and it is not easy
The onion architecture is the hardest pattern to wrap your ahead around. If you are up to the challenge and willing to climb this mountain, I promise the joy is worth the trip, and the ability to get more stuff done with higher quality and greater flexibility is un paralleled. 🏔 Ain’t no mountain higher!
What is my opinion about the Onion Architecture?
In my opinion this comes close to simplicity in a complex environment. It is not the easiest design, but out of the three patterns, the onion architecture is the simplest. At hyper, not only do we build or core service framework with this pattern, all of our API kits (coming soon) use this pattern. The minor cost of front pays huge dividends for the maintainability, testability, reliability this architecture creates along with functional thinking. So yeah, I am a big fan of the Onion Architecture.
Summary
In this journey, we reviewed three common architecture patterns and looked at them through the eye glass of an API service. My result was that the Onion Architecture was the best fit for hyper the company. You mileage may vary, but hopefully, you were able to pick some new information about these architectures to make your own decision, I highly recommend you try all three and evaluate the right approach for your team.
Thank you 🙏
Thanks for reading this post, if you are interested in more posts like this one, please subscribe to our blog. https://blog.hyper63.com/#subscribe — if you enjoy watching live coding streams subscribe to our youtube channel.
TODO: Add attribution to images

Top comments (0)