

When you’re launching an initial service, it’s often over-engineered to think about large amounts of traffic. However, when your service reaches a stage of explosive growth, or if your service is requesting and handling a lot of traffic, you’ll want to rethink your architecture to accommodate it. Poor system design that makes it difficult to scale or fails to account for the demands of handling large amounts of traffic can lead to a bad user experience or even service failure.
Cache plays a big role in services that handle large amounts of traffic, as it can quickly deliver data to users. However, the lack of scalability, which can be easily missed in early services, can lead to major service failures if the cache needs to be increased in capacity or physically moved.
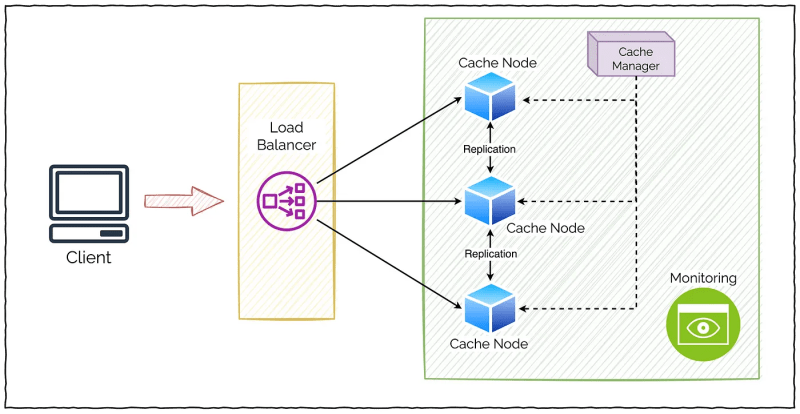
Cache in system architecture
I spent six years as a core team member at a global messenger company with massive traffic, and had many opportunities to think about scalability like this. In this article, I’ll share how I reliably migrated and improved cache without impacting service in a similar situation where I needed to physically move our cache and increase its capacity.
Caching in Large-Scale messaging service

Common flow in messaging service
Due to the global nature of the messenger, data is delivered from many countries in various forms, text, images, video, audio, and binary. If you want to break down the process, it goes like this.
- Upstream data
- Downstream data
- Delivery data

Cache request/response flow in large scale service
If the cache checks the storage where the source of the data is stored every time it is downstream of the data, the delivery speed of the data will be slow and the user experience will be poor. Therefore, the cache checks and delivers the user’s data downstream of the data because the data must be delivered quickly for the user experience.
The system architecture may vary depending on the special factors of each service, such as the nature of the data and the user’s service pattern. For this reason, even for the same service, the design can vary depending on the size of the traffic, so a flexible design is important. The platform I ran was a high-traffic service, so I applied the cache differently depending on the user’s service usage pattern.

Access to different data based on a user’s use of the service
From a data utilization perspective, there are three general patterns of how users use your service.
- Users access their data immediately after uploading it.
- Immediately after a user uploads data, they don’t access the data but do so frequently.
- Immediately after a user uploads data, they access it less frequently.
If a cache is applied equally to all of these situations, it will be inefficient and costly, which is not a good system design. Depending on the user’s pattern, the cache should be flexible enough to be applied to the same service.

Cache request/response flow in large scale service
Recognizing the above situations, caching can be applied as follows.
- For data that is immediately accessible, push it to the cache at upstream time and allow it to be hit immediately afterward.
- For data that is not immediately accessible, pull it from the cache at download time if it has not been hit.
Of course, in the second situation, you may find yourself accessing storage at the time of the first download, which is on-demand and not immediately hitting the cache. However, if the data is accessed frequently thereafter, it will be constantly hitting the cache, which will reduce storage I/O and therefore cost significantly.
Technologies are always applied with Trade-off, so from an architect’s perspective, they are designed for cost, reliability, and user experience.
Cache migration
In messaging services, where large amounts of traffic are generated in real time, the cache plays a very important role. In this situation, the cache server was aging and there was a need to increase its capacity. To do this, we first needed to organize the problems with the existing design and define the features that needed to be improved.
Problems with software designs
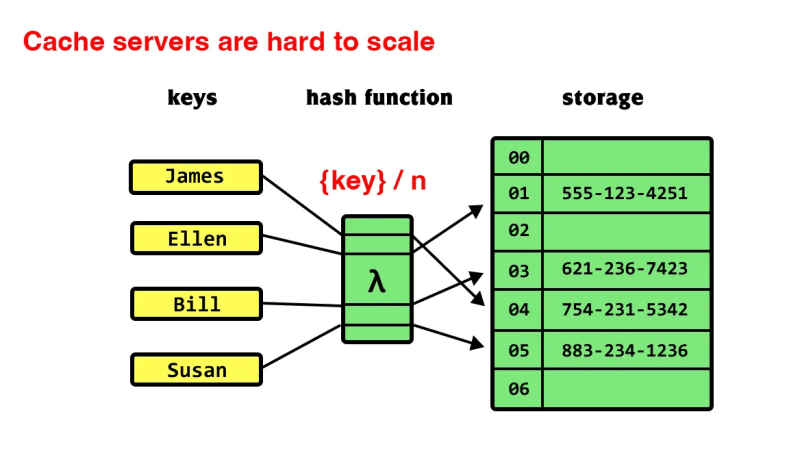
The problem with the old design was twofold.
Hashing algorithms with hard-to-scale structures
First, the hashing algorithm of the existing hash server is a structure that divides and hashes based on a specific identifier with the number of servers as the denominator, and if the number of hash servers changes, the way the existing cache is accessed changes, and the hit rate of all data drops significantly.
Therefore, it was necessary to redefine the hashing algorithm of the cache server to expand the capacity of the cache server.

Difficult to manage hash servers during in-service
The second problem was that the cache server could not be autonomously controlled in real-time, i.e., in the middle of the service, in case of a change or failure of the cache server, without restarting the backend application.
The key common issue with both of these problems was a lack of scalability, so we set out to improve them by focusing on scalability as our first priority, and operations to make it happen.
Consistent Hashing
Why Consistent Hashing
There are many algorithmic approaches to hashing algorithms, depending on the situation. However, in order to solve the above problems, we needed to prioritize scalability, so we decided to introduce a Consistent Hashing algorithm that can be accessed by the same node even as it scales.
So, what is Consistent Hashing and what are the benefits of it?
Concepts
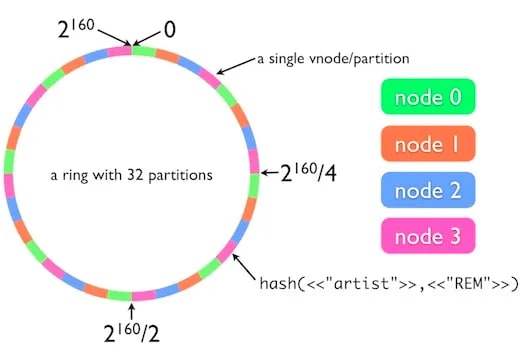
Consistent Hashing concept
In a distributed system, Consistent Hashing helps solve the following scenarios.
- Provide elastic scaling for cache servers.
- Scaling a set of server nodes, such as a NoSQL database or cache.
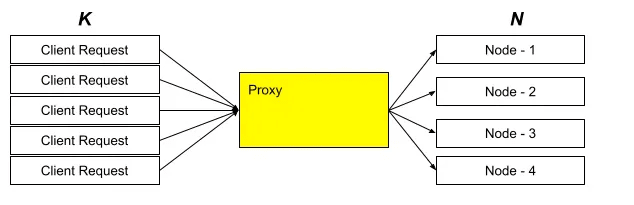
Consistent Hashing algorithms
Our goal is to design a cache system that.
- Be able to distribute requested hash keys uniformly across a set of “n” cache servers.
- We must be able to dynamically add or remove cache servers.
- Minimal data movement between servers is required when adding or removing cache servers.
Consistent Hashing can solve the horizontal scalability problem by eliminating the need to rearrange all keys or manipulate all cache servers every time you scale up or down.
How it works

How Consistent Hashing works
- Create a hash key space: Suppose you have a hash function that generates integer hash values in the range [0, ²³²-1].
- We’ll represent the hash space as a Hash Ring, and assume that the integers generated in step 1 are placed in a ring so that the last value is enclosed.
- We will place a batch of cache servers in the key space (Hash Ring) and use the hash function to map each cache server to a specific location in the ring. For example, if you have four servers, you can use a hash function to use a hash of their IP addresses to map them to different integers.
- This determines the key placement of the server.
- You don’t need to manipulate the cache servers as you add or remove servers from the hash ring.
How it works in production environment
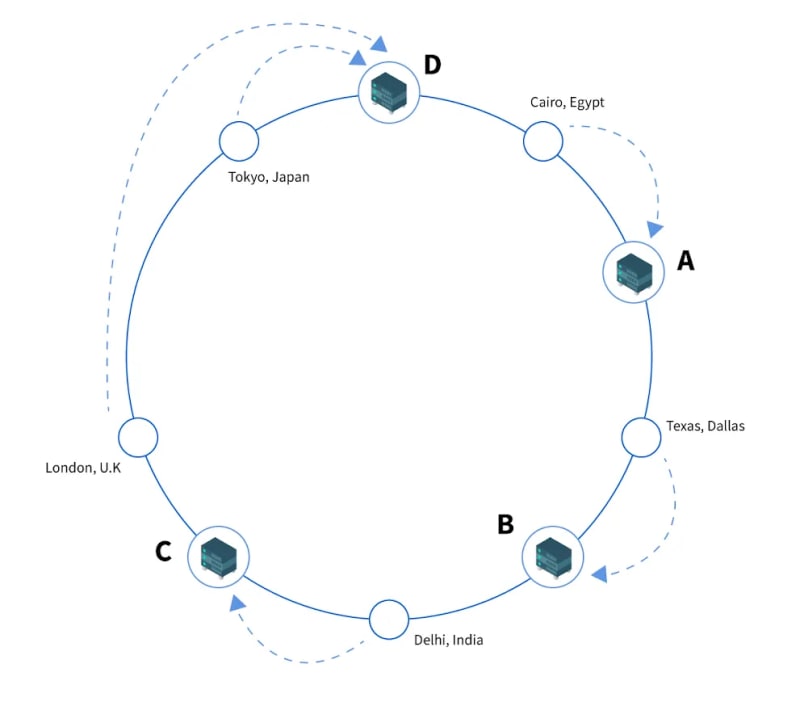
Consistent Hashing in production environment
Let’s say you’ve deployed hash keys and servers in a particular hash ring.
When a hash key is triggered by the system, it will attempt to find the data on the closest server it is assigned to. This rotation or placement can be adjusted based on the system design. Each of these cache servers is called a “Node” in the system design, denoted here as A, B, C, and D. They are placed clockwise, followed by the key.
Now, when the system receives a request for data about “Cairo, Eygpt”, it will first look for that information in the corresponding node, i.e., “A”. Similarly, for the keys “London, UK and Tokyo, Japan”, the closest corresponding location or node is “D” clockwise, so it will interact with that particular node to retrieve the data.
Unlike traditional hashing, when the system encounters a server failure, addition, or removal, the request or data key is automatically connected or assigned to the closest server or node.
Traditional hashing methods are not sufficient to use and handle requests over the network in case of server problems or issues. Assume that there is a fixed number of servers and the mapping of keys to servers happens at once.
Adding a server requires remapping and hashing of objects for the new server and a lot of computation. On the other hand, non-linear placement of nodes in Consistent Hashing allows nodes to interact with each other if the system changes.
However, there are times when the distribution or load is not equal or proportional for all nodes in the Hash Ring, resulting in an unbalanced distribution. Let’s take a closer look at how the Consistent Hashing system responds to situations where servers/nodes are added or removed, and how it ensures that the system doesn’t become unbalanced.
Hotspot
Nodes that bear the load of unevenly distributed data requests become hotspots. To solve this problem, system engineers can use virtual nodes to enable hash rings to distribute requests evenly among all active nodes.
Adding and removing servers in Consistent Hashing

Adding and removing servers in Consistent Hashing
When you add a new node to the ring, for example, between the “Srushtoka & Freddie” keys. Initially, was handling both the keys as shown in the figure above. Now, after the new server , the hash or assignment for the “Freddie” key will be assigned or mapped to instead of . However, the “Srushtika” key assignment will remain mapped to .
The same principle is followed in case of removing an existing server from the ring. Thus, a hash ring ensures that the entire process is not affected in case of adding or removing servers or in case of failure of a node. Also, if a situation arises where reassignment occurs, it does not take much time as compared to traditional hashing mechanisms.
Cautions and benefits
You have a cluster of cache servers and need to be able to elastically scale up or down based on traffic load. For example, a common case is adding more servers over the Christmas or New Year’s period to handle additional traffic. Therefore, you need to have a set of cache servers that can elastically scale up or down based on traffic load.
This is where Consistent Hashing shines in situations like this, where you’re running an elastic cache cluster. Let’s summarize the benefits of this.
- Elastic scaling of a cluster of database or cache servers
- Easier to replicate or partition data between servers
- Partitioning data allows for a uniform distribution that mitigates hot spots
- Enables system-wide high availability
Scalable software design
With the hashing algorithm change to Consistent Hashing, you have a ready form of cache servers that are easy to scale, but you will need to do some additional preparation to replace or add to your existing cache cluster with a ready set of cache servers.
To migrate cache servers and make changes to existing clusters without service disruption, you’ll need to ensure that your backend applications support hot-reload, which means that they can read and reflect settings without restarting the service. If your service is based on large amounts of traffic, you’ll need to be extra careful to make sure it’s ready and able to handle this task.
Preparing for migration
First, we did a lot of configuration subtraction in order to add or remove changed cache servers from the backend application without disrupting service. This process should only target information that should be controlled by configuration, and the reasons for this should be clear and unambiguous.
Migration scenarios

After the above setup was completed, we divided the scenarios into those that succeeded and those that failed along the way, and prepared to respond accordingly.
Successful cache migration scenarios for large scale service
Successful scenarios
- Migrate each family of cache servers in turn based on certain factors, such as region.
- Data migration to the newly configured cache cluster is complete, and the new cache cluster has a hit ratio close to 100%.
- Fewer requests are made to the existing cache cluster, and the hit ratio approaches 0%.
- Remove the old cache cluster with settings without restarting the service
- All data requests will now be delivered by the newly configured cache cluster.
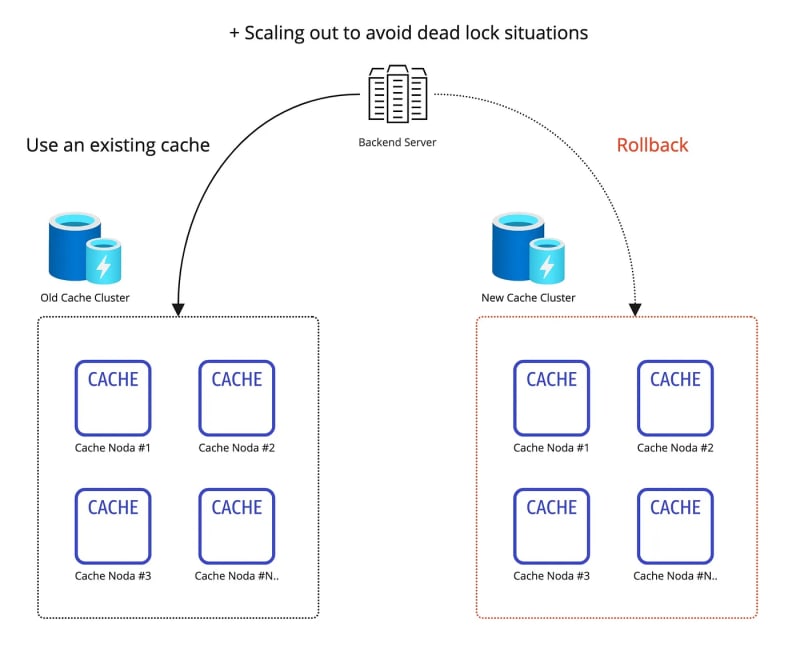
Scenarios when cache migration fails on large scale service
Failure scenarios
- Each cache server cluster is migrated in turn based on a specific factor, such as region.
- As data is migrated to the newly configured cache clusters, it is mixed in with the existing data hashing, causing data to break.
- Remove all new cache clusters and roll back requests to only the existing cache clusters.
- An existing backend application server or storage I/O is experiencing a dead lock due to high usage.
- Monitor system resources, watch the situation, and add 20–50% more backend application servers than you had before.
- Temporarily throttle some requests via Circuit Breaker to accommodate the storage I/O.
- Once the system is stabilized, perform analysis to determine the cause.
We first thought about the scenarios that could work and those that could fail, and reviewed them with ourselves and our team members to make sure we didn’t miss any tasks or cases along the way. If the scenarios worked, we listed the features we needed and implemented them one by one.
Iterative testing
If you jump straight into a cache migration without testing for a service that relies on large amounts of traffic, the chances of it going off without a hitch are extremely low. Even if you have prepared many scenarios and responses to them, engineers can’t anticipate every situation, and humans make mistakes all the time, so even small issues are likely to occur.

Iterative testing in large scale service
So, before I started migrating cache in production, I split my testing into two parts.
- Run a small simulation in a development environment for testing.
- Run multiple Canary tests on the least requested server cluster in production.
For both of the above tests, we set up the same monitoring and alarm system as in our production environment.
Simulation in a development environment
When we were running small-scale simulations in our development environment, we would generate traffic based on mock data so that we were subjected to a high level of traffic for a small scale, i.e., stress testing. However, this simulation had the disadvantage of not being able to test the same as the actual production environment.
Canary test in a production environment

Canary test
What the tests in the development environment didn’t cover was the fact that it was mock data traffic, not real user traffic, so it didn’t take into account the user’s time at the time of the cache migration in the production environment, events at that time, weather, and other contextual factors. We decided that these tests were difficult to cover in the development environment, so we wanted to compensate by running multiple canary tests in the production environment.
However, since the canary tests are in the production environment, they can affect the service, so we targeted a group of servers in the region with the lowest request volume and ran the tests at the time when the lowest request volume occurs.
Migration
We had written out all the scenarios for successful and unsuccessful cache migrations, developed features for them, and tested them on a small scale several times, so we thought that if nothing major happened, the migration would go off without a hitch. In fact, once we did this in production, it took about a month to migrate from the old cache cluster to the new one. The reason it took so long was because there was some traffic that could have been left over from various clients or legacy client code.
Since the new cache clusters were put in place, we were able to remove the old cache clusters at the right time because we were constantly monitoring and closely managing the alarms. In addition, to maintain a stable service through the cache migration, we focused on reducing the failure rate instead of aiming for success, so we had a flexible response plan in case of failure scenarios. In the end, this process allowed us to successfully complete the cache migration without a single issue during the month-long period.
Conclusion
In this article, we’ve talked about the implications of cache for services that rely on large amounts of traffic, what scalability gaps in the design of these services lead to, and the issues we encountered when trying to scale the cache and how we addressed them.
In general, these are changes that can be very burdensome for services that rely on large amounts of traffic, so you should always question whether there are any errors in thinking. Also, instead of just achieving the short-term goal of cache migration, we thought a lot about “can we respond with the current system?” or “can we scale?” when similar needs arise in the future. If we had a short-term goal of cache migration, we would have simply increased the number of servers based on the existing hashing algorithm.
When you’re thinking about the architecture of a large service, you’re likely to encounter many situations where you need to make trade-offs. In these situations, planning ahead and aiming to reduce the number of scenarios where you might fail in order to achieve your goals, rather than trying to achieve piecemeal goals, can be an effective approach to solving problems.
I hope this article has been helpful to you and I look forward to sharing my experience and knowledge with others who are looking to build a successful production in the future.

Top comments (0)