If you had read my previous blog post, you’ll have found out that I’m somehow unable to escape Drupal. Not that Drupal is some terrible monster, it’s actually not bad. At this point, I’ll probably end up finishing my career with some Drupal project, who knows? Drupal 42, let’s go.
I had not done Drupal since 2020, and if it wasn’t for those blog posts I wrote back then, things would have been much harder. But as I slowly poked around a freshly installed copy of Drupal 10, in spite of the many changes (for the better), I found there were also many things that remained familiar.

Anywayz, one of the things that needed to be done was to pull data from Sessionize, which is a SAAS (software-as-a-service) platform for managing conference talks. Sessionize exposes speaker and talk data to developers via a JSON API so you can pull that information into your own website.
Feeds
One way to do this is via the Feeds module, which is used “for importing or aggregating data into nodes, users, taxonomy terms and other content entities using a web interface without coding a migration.”
Feeds lets you create new content nodes containing the data that you’re pulling through. If you’re unfamiliar with Drupal altogether, Drupal has the concept of content types, where you can create specific content types containing specific fields to hold specific data. Each piece of content is referred to as a node.
You do need to tell Feeds which fields from the JSON data map to which fields on your content type, so the setup did kill a good number of my brain cells. But just in case I have to do it again, this blog post exists.
Install the module
I have not hardcore Drupal-ed since 2017, so I need to rewire my neurons to the Composer is king mindest.
composer require 'drupal/feeds:^3.0@beta'
By the time someone reads this, the version would have changed, please copy the correct installation command from the module page itself. After the module files are added, enable the required modules.
drush pm:enable feeds, feeds_ex
You can also do it from the GUI at admin/modules. Feeds extensible parsers is required if your data is JSON.
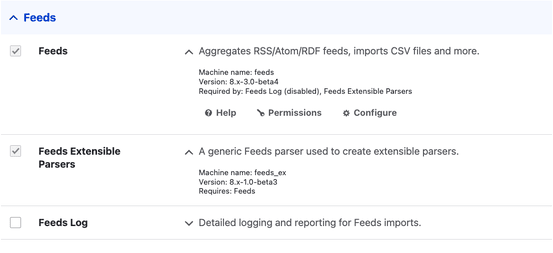
Configure the module
This is the tricky part. And will also depend quite heavily on the shape of your data. The Sessionize speaker data looks something like this:
[
{
"id": "XXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"firstName": "Adrian",
"lastName": "Hope-Bailie",
"fullName": "Adrian Hope-Bailie",
"bio": "Adrian is a co-inventor of the Interledger protocol stack and the Open Payments standards and payment pointers. He is a co-founder of Fynbos where he is building the first account that will issue payment pointers and support Open Payments.",
"tagLine": "Founder at Fynbos",
"profilePicture": "https://sessionize.com/image/e5b2-400o400o1-UNKX2DhHQEuyQwrn2Xx1vb.png",
"sessions": [
{
"id": 000000,
"name": "Digital Wallets - Our financial \"user agents\""
}
]
}
]
Most of the fields are straightforward 1-1 mapping to individual fields, like the firstName field to a text field, or the bio field to a formatted text field and so on. But the sessions field data is an array. And that was not intuitive to deal with at first.
But first, the content type. Think of the content type as the container in which the data that you pull in via JSON has to live. Which means the data should be mapped to their respective fields in the Drupal content type.
I created a new content type called Summit speaker. The only tricky field is sessions. This is because sessions have their own content type, and the 2 content types reference each other. So the sessions field is an entity reference field.
Back in the day, I remember that entity reference was a contrib module, but now it’s built into Drupal. When you create a new field for your content type, you can select Reference.

I set mine up to allow an unlimited number of values, and to reference the Summit talk content type.
The field mapping takes place on the Feeds configuration interface at /admin/structure/feeds. Start by adding a feed type. Fill the basic information as you see fit. The key part is to set the Fetcher to Download from url and the parser to JsonPath.
Because the target for the JSON data is my newly created content type, the processor is set to Node and my content type is Summit speaker. The rest of the settings are really up to your individual use-case. Because my event was already over, I only needed a one-time download, but you might want to set a regular import period or whatever.
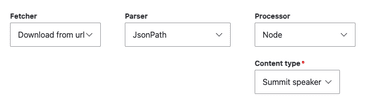
The Mapping tab is where you determine how the data gets pulled into your fields. The Context field (based on my extensive Googling to figure out the right thing to do) is what trips most people up. I think it’s just how the JsonPath syntax works but there’s a tool for that!
You can plug your JSON file into the JSONPath Online Evaluator and try to work out what you want to put in there. For me it was simply $.* because I wanted to parse the whole thing.
After you select a target field (on your content type), you will need to specify the source (i.e. where from the JSON the value should come from). Pick New Json source…, which will give you a free form text field. Enter the key value on the JSON you want the data to come from.
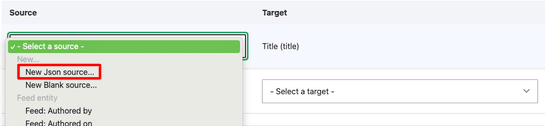
In my case, I would put in fullName for the value I wanted mapped to my Summit speaker content type’s title field. And so on, and so forth.
For fields that were in an array, like the sessions field, the mapping value is a bit more complicated. It’s more JsonPath syntax is what I think. But for my sessionName source, the value I used to make things work was sessions[*].name, I validated it using the JsonPath tool thingy.
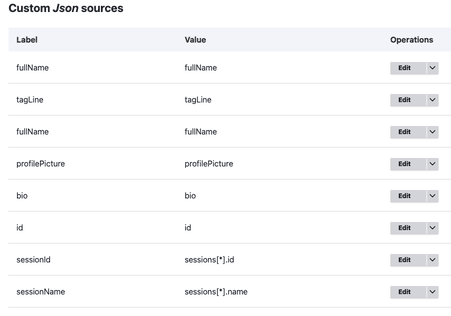
The long and short of it is that this seems to be the syntax that works for importing values into a Drupal field that takes in multiple values.
The place to define the source of your JSON is configured at /admin/content/feed. You need to add a new feed. The options will depend on what feed types you have created so far. Select the feed type you want, and you will need to label it with a title and the key here is the Feed URL, which is the URL where your JSON can be accessed.
If everything goes well, smash that Save and import button and you should see a status message informing you of your success or failure. The complication for my use-case is my use of the entity reference field to a Summit talk content type.
Luckily, the import won’t fail entirely even if the entity reference field cannot find the entity it wants to reference. The sessions field for now will just be empty. After all the talks have been imported, re-run the feed import and (hopefully), your content nodes will update accordingly.
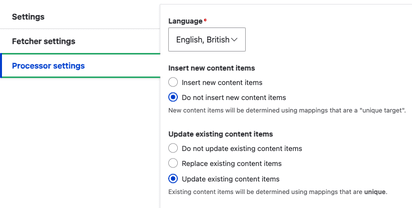
Check your settings on the Feed type under Processor settings to make sure you have set behaviour to Update existing content items.
Wrapping up
I think that’s it? I mean, it took me quite a bit of time and effort to get the steps distilled to what you’ve just read. I even ran into Drupal 101: What I learnt from hours of troubleshooting Feeds which I had written in back in 2015.
And no, sadly it did not help me one bit because that import was in CSV. JSON was a whole new bunch of hours spent troubleshooting. But what can I say? It pays the bills. It pays the bills. It pays the bills. 💵





Top comments (1)
Thank you for an interesting article and the guidance you shared on wrestling with JSON feeds, Chen.
I had a look at Drupal several years ago when I started out with my research on secure, reliable PHP workhorses. Look, from what I could gather, Drupal was/is quite "solid" in most areas, but it was too clunky for a single dev to maintain larger CMS systems as I had in mind. WordPress, although well established, was a no-go for me due to the many security issues with packages and unreliable third-party add-ons as I discovered during my searches back in 2019. Laravel seemed a good fit, and by the looks of it, is becoming quite the "Composer" in the PHP framework arena.
The principle of working with large JSON data sets as per your requirement is what caught my attention though, and is a valuable guideline for similar frameworks like Laravel, IMO.