We create a humongous amount of data every day. The following are just some of the mind-boggling facts about data created every day.
- 2.5 quintillion bytes of data are created every day. That’s 18 zeros after 2.5!
- 5 billion Snapchat videos and photos are shared per day.
- Users send 333.2 billion emails per day.
Are you a businessperson looking to leverage the power of big data analytics? If yes, then you will need to solve some database challenges first. This is because a robust database is a prerequisite for successful data analytics. AWS provides a plethora of solutions to help you.
In this blog, we will be comparing Amazon Athena - a big data tool, vs Amazon EMR - amazon’s big data as a service. These two services cater to the need of data analysts, data scientists, and enterprise organizations to make sense of their big data. Let’s dive deep and understand each of the services in detail.
Amazon Athena
An interactive query service translates use inputs into SQL queries. Amazon Athena is one such interactive query service. It uses SQL to analyze the data stored in Amazon S3. Typically, Athena is used with large-scale data sets. The steps involved in the process are - configuring the AWS management console, directing Amazon Athena toward Amazon S3 data, and launching standard SQL queries.
As Athena is completely serverless in nature, analysts don’t need to manage any underlying infrastructure to use it. Being serverless means, you can scale indefinitely. By leveraging auto-scaling, you can count on Amazon Athena to execute parallel queries to deal with complex and large data sets.
When to use?
- To query encrypted data managed by AWS Key Management Service
- Features cross-account accessibility to S3 buckets owned by someone else
- Leverages managed data catalogs to store information and Amazon S3 search-based schemas.
Features
Maintenance-free solution - As mentioned above, Amazon Athena is serverless in nature. As there is no infrastructure, you don’t need to deal with software updates or manual configuration.
Easy to get started - Getting started with Athena is fairly simple. You need to log into the Athena console, define your schema and start querying.
Security - Athena grants access control to your data using various tools and policies. For example, you can grant specifically confined controls to your S3 buckets using Amazon Identity and Access Management. It supports both server and client-side encryption for better security.
Advantages
Cost-effective - For using Amazon Athena, you are charged based on the amount of data scanned per query. In simple terms, it's a pay-per-query scheme. You can save a lot by compressing your data and converting them into the columnar format. Doing so will reduce your data consumption while running a query.
Widely accessible - As Amazon Athena uses the most popular SQL to run its queries, it is widely accessible to developers, data professionals, and business analysts.
Flexibility - Athena’s architecture is versatile and doesn’t stick to a particular ecosystem of technology, tool, or vendor. You can openly work with a wide variety of open-source tools, query engines, and file formats.
Disadvantages
Lack of data optimization - Athena lacks data optimization capabilities. The best it can do is optimize the query but not the underlying data.
Lacks Indices - Amazon Athena lacks the provision of data indices - a standard feature in traditional databases. Due to this, you will face problems while consolidating large tables.
Shared resources - Amazon’s service agreement clearly states that all AWS Athena users share the same resource while running their queries. There is a high tendency for fluctuating query performance due to resource straining.
Getting started with Amazon Athena
Before writing your first query using Amazon Athena, you just need to follow 3 simple steps.
Step 1: Sign up and configure
To get started with Athena, you would need to
- Sign up for an Amazon AWS account
- Create an IAM administrative user
- Attach two policies for Athena:
AmazonAthenaFullAccessandAWSQuicksightAthenaAccess. These policies are essential for granting permission to query Amazon S3 - Sign in as an IAM user
Step 2: Create a Database
To create an Athena database
- Go to Athena console - https://console.aws.amazon.com/athena/
- Open query editor
- Select View setting to set up query result location in
Amazon S3

- On the settings, tab select Manage
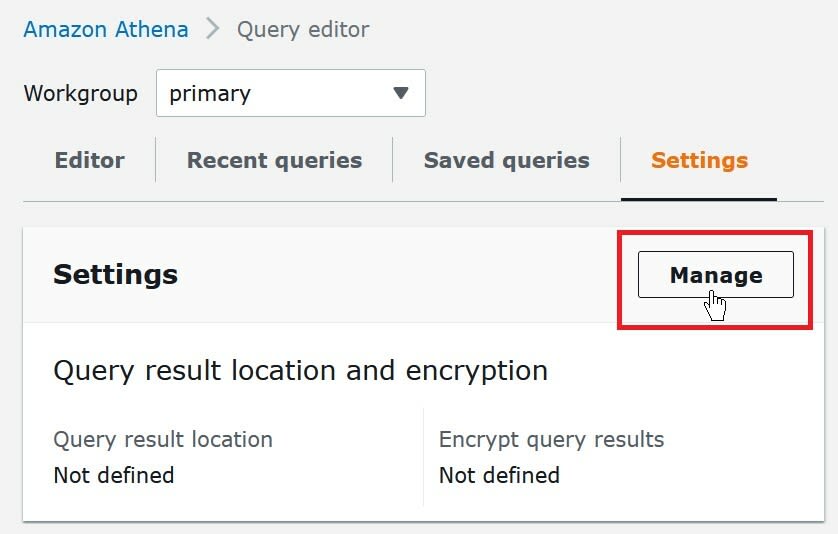
- In the location of query result box, enter the Amazon S3 bucket path prefixing with s3://
- Select Browse S3 and then pick the S3 bucket you created

- Go to editor and select query editor
- On the right side panel, you can use the editor to run queries and statements
- You can write command “mydatabase” on query editor to create your database
- On the left, click the database dropdown and select “mydatabase” to select the current database

Step 3: Using query data
Now that you are aware of how to use Athena queries. Let’s look at a few basic functionalities you should be aware of.
- After writing your query from your database, click run. The result should look something like the one below.
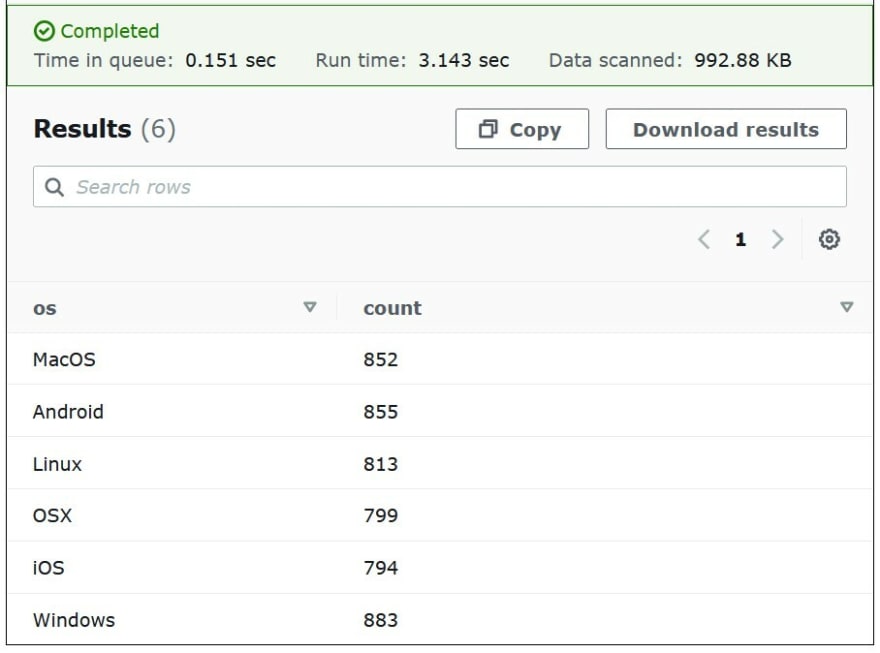
- To save query results in a .csv file, choose download results

Amazon EMR
Amazon EMR stands for Amazon Elastic Map Reduce. It is an aws service that organizations leverage to manage large-scale data. One can leverage Amazon EMR to provide a cluster platform for open-source frameworks such as Apache Hadoop, Apache Spark, Presto, etc. Compared to Amazon Athena, EMR is a very expensive service. Even if you are not processing any data, you are liable to pay for the computing time and its supporting services.
Features
Elastic in nature - EMR has the provision for providing as much capacity as you need. If the space is found unused, it will automatically scale down any unused space.
Flexible data storage - Amazon EMR is compatible with multiple data stores like Amazon S3, Hadoop Distributed File Systems or HDFS, Amazon DynamoDB, etc.
Big data tools - Amazon EMR supports all the well-known tools in the market. For example, big data support tools like Apache Spark, Apache Hive, etc. Machine learning and deep learning support tools like TensorFlow, Apache MXnet, etc.
Advantages
Easy to use - EMR clusters can be launched in a matter of minutes. The good news is you don’t even need to worry about Hadoop configuration, infrastructure setup, or cluster tuning. Amazon EMR performs all these tasks and does the heavy lifting for you so that you can focus on your analysis.
Reliability - EMR can automatically monitor and tune your cluster. It is programmed to retry failed tasks and automatically replaces instances having performance issues. Amazon EMR can be configured to prevent cluster termination due to an underlying issue. This makes it feasible to recover the data from the instance, which otherwise would have been lost forever.
Security - Worried about configuring the firewall setting of your EC2 instance? Don’t worry, Amazon EMR has got you covered! To secure clusters, EMR leverages features like Amazon EC2 key pairs. Authorization and permissions are managed using the AWS service known as Amazon IAM.
Disadvantages
- Amazon EMR studio is only available at a few global locations.
- Amazon EMR or EKS cluster doesn’t support SparkMagic commands on EMR studio
- When debugging Amazon EMR running on an EC2 instance, the links to the on-cluster Spark UI may not work or fails to appear.
Getting started with Amazon EMR
Amazon EMR cluster can be launched in many different ways. Let’s find out how to configure and set up your EMR cluster using simple steps.
Step 1: Setting up Amazon EMR
- Sign up for Amazon AWS
- Create an Amazon EC2 key pair for SSH
Step 2: Quick EMR configuration
- In the create cluster window under software configuration, you can select the release version of your EMR flavor. The majority of people pick up Spark, as its the most popular option
- In the hardware configuration, make sure to check auto-termination. This will ensure that excess charges are not incurred.

Step 3: Launch an EMR cluster
- After setting up the quick configuration, enter the cluster name. For example,
My first EMR cluster - Enable logging and replace the S3 folder value with the
/logsof the Amazon S3 bucket you created - Select the EC2 key pair under security and access
- Finally, create a cluster to launch the cluster.
Conclusion
Both Amazon Athena and Amazon EMR serve the purpose of big data analysis. However, their approach to solving the purpose is quite different. If you are wondering which one you should opt for, you need to first understand your firm’s requirements and budget. Based on that, you can make a crystal clear decision. Still, stuck somewhere? Let me know what’s bothering you in the comments below.

Latest comments (0)