Introduction

API security breaches are on the rise. Gartner predicts that by 2025, insecure APIs will account for more than 50% of data theft incidents. As enterprises continue to embrace an API-driven approach to software development (for all the benefits it brings), arming their developers with the tools to build secure APIs with proper data access and authorization logic needs to be a priority.
Building an authorization layer involves many factors. In GraphQL, authorization belongs in the business logic layer and not typically inside resolvers. It is more complex to write an authorization layer for GraphQL APIs than REST APIs. In this blog, we will see what it takes to build authorization logic for a DIY GraphQL server to understand how it is more complex. We will also compare it with Hasura and how it solves this complexity by being declarative and leveraging predicate pushdown.
Here's a quick TL'DR and summary before diving deep into this post.
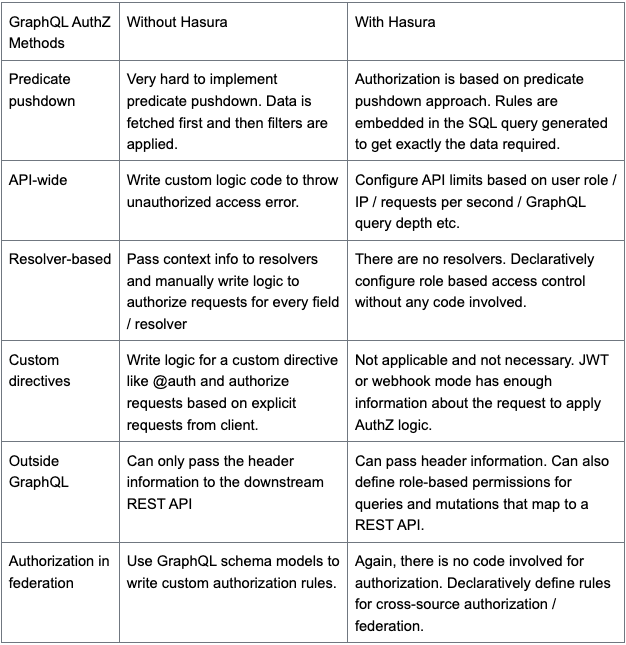
Key items to consider
Data modeling
Data models contain key information about the types of data, relationships between data. This is used to determine the kind of authorization system that needs to be built.
For example, you have users of the application that can view public data of all users and certain private data of them. The data model now contains certain table columns relevant to this and also relationships that are relevant to this private data.
Roles and attributes
The common ways to model your authorization system is through RBAC (role-based access control and ABAC (attribute-based access control).
You could start defining roles for the application and list out use cases and privileges for each. RBAC could be flat, hierarchical, constrained and symmetrical. Authorization can also be modeled based on attributes where the user who logs in to the application will have certain attributes (type of user, type of resources, and the environment in which they are accessing) that can be checked for allowing access.
Nested rules
The GraphQL schema may or may not be a direct map to the data models. In some cases, the data model extends to multiple data sources. Even within the same data source, the GraphQL query could be nested with multiple fields spanning relationships. Applying authorization logic contextually to the nested query is vital.
For example:
query {
users {
id
name
orders { // apply permission rule here too
id
order_total
}
}
}
Here the orders is part of the users relationship and is nested. But the authorization logic needs to apply for both users, for orders, and for any level of nesting of the query, contextually.
Performance
Ideally, authorization checks shouldn’t add a lot of overhead to the response latency. In reality, when you are writing a custom GraphQL server yourself, checks are done after the data fetching operation and there’s a lot of unnecessary data fetched, which slows down the database if you consider millions of requests which slows down API performance as a result.
Predicate pushdown
If the authorization logic is heavily dependent on the data being fetched, it is important to do a predicate pushdown of the Authorization rules.
For example: If you are fetching orders placed by a user on an e-commerce app, you need to be able to apply the rule in the query that goes to the database to fetch only the orders placed by the user requesting them. This is not only faster, but also the most secure way to apply authorization logic.
Building a DIY authorization layer for a GraphQL API
You can build an AuthZ layer using middleware libraries. The maturity of AuthZ libraries in GraphQL depends on the language or framework you are in.
Why is building an authorization layer complex?
When you are writing your own GraphQL server with custom authorization rules, there are a number of methods to write this logic, depending on the use case. You have:
- API-wide authorization
- Resolver-based authorization
- Schema / model-based authorization
The resolver-based authorization quickly balloons into a lot of boilerplate code if authorization rules are applied to every field. Even with repeated rules and patterns that can be applied, it can easily expand to thousands of lines of code to secure your application. And this code becomes difficult to maintain.
In the schema-based authorization, the authorization logic is dependent on the GraphQL schema and becomes independent of the underlying database or data fetching libraries and ORMs.
Authorization in GraphQL is typically built using _ Context _ object that is available on every request. The context is a value that is provided to every resolver and is created at the start of a GraphQL server request. This means you can add authentication and authorization details to the context, such as user data.
Here’s how a typical AuthZ context gets passed in a DIY GraphQL Server written in Node.js:
Parsing and validating JWT token
The first step is to parse and validate the incoming JWT token. Once the JWT token is verified, you can pass it to the context. We are using JWT tokens as an example here, because it is universal and works across platforms.
An example request:
Endpoint: myapp.com/v1/graphql
Headers: Authorization:
The Authorization header is parsed, validated, and verified. The underlying authentication service used could be any solution that issues JWT. Here’s some example code that verifies a JWT token:
try {
if (token) {
return jwt.verify(token, YOUR_SECRET_KEY);
}
return null;
} catch (err) {
return null;
}
Here’s an example taken from a DIY GraphQL Server (Apollo) to parse the context:
Create a new instance of Apollo Server by passing in the type definitions and resolvers.
const server = new ApolloServer < MyContext > ({
typeDefs,
resolvers,
});
Create a standalone server that retrieves the token from headers and returns the user information as context.
const {
url
} = await startStandaloneServer(server, {
// Note: This example uses the `req` argument to access headers,
// but the arguments received by `context` vary by integration.
context: async ({
req,
res
}) => {
// Get the user token from the headers.
const token = req.headers.authorization || '';
// Try to retrieve a user with the token
const user = await getUser(token);
// Add the user to the context
return {
user
};
},
});
Passing context
Once the token is extracted, you need to pass the context object to every resolver that will get executed. Now all of your resolver code gets access to the context.
In the above example, we can see that the user data is passed to the context.
API-wide authorization
There are a few rules that might need to be enforced at the request level, even before passing it on to the GraphQL resolvers.
For example, you could block a user from performing any queries and return a 401, unauthorized error. Again, this involves code logic and the logic could become a lot of boilerplate if there are many rules.
Resolver-level authorization
As the context gets attached to each resolver, it is now possible to authorize the request inside the resolver. This method is only suitable for basic authorization logic when there are only few resolvers and few rules to check and authorize users.
For example: You have a users field that returns a list of user names. You will end up writing code, which looks something like this:
users: (parent, args, contextValue) => {
// In this case, we'll pretend there is no data when
// we're not logged in. Another option would be to
// throw an error.
if (!contextValue.user) return null;
return ['bob', 'jake'];
};
The contextValue is now available for parsing and authorizing the user.
Note: This is resolver logic for one field. Imagine repeating logic code in every single resolver and field. It is very challenging to scale this. It is also very challenging to update any logic quickly.
GraphQL schema-based authorization
In a large schema with plenty of data based authorization, there are patterns of rules that are applicable for multiple queries. For example: Allow the user to fetch their own data and not any one else.
Here’s an example from GraphQL AuthZ library using schema as a data source.
// using schema as a data source inside pre-execution rule
const CanPublishPost = preExecRule()(async (context, fieldArgs) => {
const graphQLResult = await graphql({
schema: context.schema,
source: `query post($postId: ID!) { post(id: $postId) { author { id } } }`,
variableValues: {
postId: fieldArgs.postId
}
})
const post = graphQLResult.data?.post
return post && post.author.id === context.user?.id
})
If you look at the return statement at the end in the above code snippet, that’s where the logic of checking user ID is written.
How does Hasura’s authorization layer work?
Hasura has a powerful authorization engine that allows developers to declaratively define fine-grained permissions and policies to restrict access to only particular elements of the data based on the session information in an API call.
Implementing proper data access control rules into the handwritten APIs is painstaking work. By some estimates, access control and authorization code can make up to 80% of the business logic in an API layer. Securing GraphQL is even harder because of the flexible nature of the query language. Hasura radically simplifies the effort needed to build authorization logic into APIs.
Declarative
With Hasura, you can transparently and declaratively define roles, and what each role is allowed to access in the metadata configuration. This can be done either through the Hasura Console or programmatically through the Hasura CLI. This declarative approach to authorization is simpler to create, maintain, evolve, and audit for developers and security teams.
Fine-grained access control
Hasura supports a role-based access control system. Access control rules can be applied to all the CRUD operations. You define permissions granularly on the schema, sessions, and data (table, row, and column).
For every role you create, Hasura automatically publishes a different GraphQL schema that represents the right queries, fields, and mutations that are available to that role. Every operation will use the request context to further apply permissions rules on the data.
Authorization rules are conditions that can span any property of the JSON data graph and its methods:
- Any property of the data spanning relationships. Eg: Allow access if “document.collaborators.editors” contains “current_user.id3⁄4
- Any property of the user accessing the data. Eg: Allow access if accounts.organization.id is equal to current_user.organization_io
- Rules can mask, tokenize, or encrypt portions of the data model or the data returned by a method and are labeled. These labels are called "roles."
Easily integrate with your authentication system
Authentication is handled outside of Hasura, and you can bring in your own authentication server or integrate any authentication provider that supports JSON Web Token (JWT). If your authentication provider does not support JWT, or you want to handle authentication manually, you can use webhooks.
"By using Hasura, we cut the development time in half and built our product in three months. The built-in role-based authorization system made it easy to secure our data."
Mark Erdmann, Software Engineer, Pulley
Predicate pushdown
Hasura automatically pushes down the authorization check to the data query itself, which provides a significant performance boost and cost savings by avoiding additional lookups and unnecessary data egress, especially at larger scale.
Hasura automates predicate pushdown, since it is essentially a JIT compiler that can dynamically apply the filter in where the clause of a SQL query is based on the user running the query. Most GraphQL server frameworks require you to write plenty of boilerplate code to achieve the predicate pushdown authorization check.

Cross-source authorization
Hasura integrates authorization rules based on data and entitlements in different sources. Hasura forwards the resolved values as headers to your external services, which makes it easy to apply authorization rules in your external service. Again, this is made possible by Hasura’s declarative authorization system.
OWASP Top 10
OWASP is most famous for the “Top Ten” framework for structuring secure applications. As the industry expands into a microservice-driven approach, it’s important for organizations to validate all of their dependencies according to the OWASP framework.
Hasura’s security-first approach ensures that the Top 10 security features and criteria are fulfilled. Read more: How Hasura addresses the OWASP Top 10 concerns.
When you are building your own GraphQL server and writing authorization logic, you will need to ensure that the Top 10 concerns are handled to be secure and compliant.
Try out Hasura
Sign up to start your journey with Hasura Cloud today. If you are an enterprise looking to learn more about how Hasura fits in your app modernization strategy, reach out to us through the Contact Us form and our team will get back to you.

Top comments (0)