
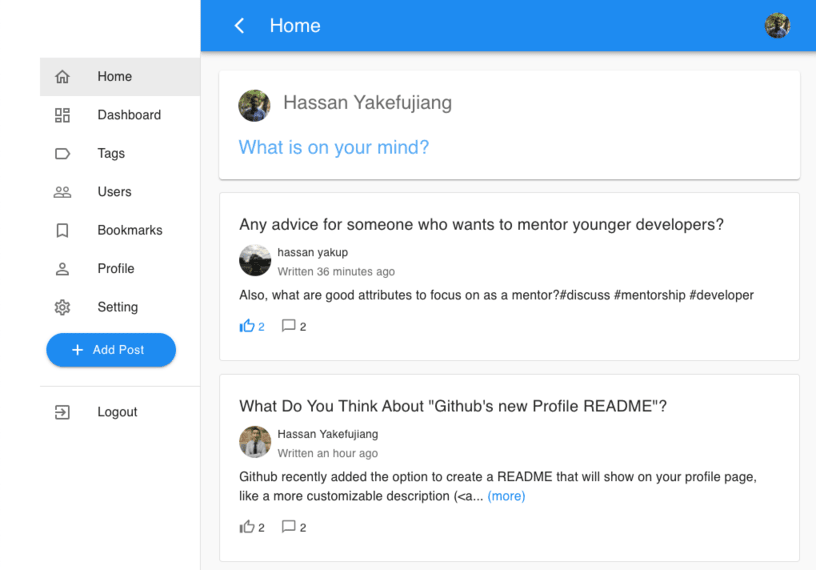
Desktop view of https://eureka-v2.web.app.
I recently deployed a web app that I’ve been working on for the past few months. In this post, I will talk about the challenges I faced while building this app as well as the lessons I learned from it.
What is Eureka?
Eureka is a web-based, social networking platform (similar to Reddit and Facebook) where users can create and share text-based posts. It allows users to search for posts by hashtags, bookmark a post, see threaded comments, like, and comment on other user's posts.
🚀 Live on web and Github repos.
Here is the tech stack I used for this project:
- Material-UI
- React.js
- Redux
- Firebase
- Redux form
- Other tools (moment, react-html-parser, react-infinite-scroller, react-redux-toaster, ck-editor)
Why did I decide to build this project?
I originally wanted to build an application with a completely different purpose — an app-proposal sharing platform where both the software developers and the general public can propose app ideas. The non-technical user can state a problem they are experiencing and propose an app idea with an explanation of how that app can help address their problem. The developer can then pick up an idea (that they like) and make it into an open-source app (you can read more about it here).
I started building this app in the winter of 2019 and completed it in March of this year. However, I realized (just then) that my app concept was underdeveloped and there were many loops holes in terms of user interaction design. I could have done more research and develop a better understanding of how this app should ideally work, possibly by building storyboards and user personas.
In the end, I decided to do a second iteration with a different concept and tech stack. Because I was recently exposed to firebase Cloud Firestore, I wanted to gain some hands-on experience with it. Thus, I decided to turn my existing app into a social-networking/blogging application (which sounds super boring, I know, lol).
My process in building this application
1. Research

Initial research on tech stack.
I started by researching how I should model my data (e.g. user, posts, tags, comments, etc.) using Cloud Firestore by reading firebase documentation and stack overflow discussions. I also took an online course on Data Modeling with Firestore, which taught me how to model one-to-one, one-to-many and many-to-many relationships with Firestore while optimizing queries for performance, cost, and complexity.
2. Coming up with Product Requirements
After the research phase, I created a google document with a list of features and requirements for this app. I also created a technical roadmap document, which included all the queries I will be making, a data model, and a “food for thought” section which has questions and problems I was anticipating to face.
3. Creating pages/UIs with dummy data

Since this is my second iteration of building this CRUD app with different tech stack and app concept, I used the UI from my first iteration to save time. I took a lot of inspiration from Twitter design.
4. Adding functionality to each page
After having all of my pages set up, I was ready to plug in the functionalities. I started by setting up redux, firebase, and other binding libraries. Then, I worked on one feature at a time by creating redux actions and functions to make a request to my Firestore database
5. Setting up security rules, testing, CD

.github/workflows/deploy.yml
Lastly, I added firebase security rules to restrict access to my database. Then, I tested the app to make sure that everything still works alright. I also set up a ** continuous deployment** workflow with GitHub Actions, so my code gets deployed automatically to firebase without me doing it manually.
Some challenges I faced
Challenge 1: What to do when a user tries to delete their post/comment?
I wasn’t sure how I wanted to handle the delete operation for user-generated content (e.g. post, comment). In the end, instead of actually deleting the post (or comment) document inside the firestore collection, I set a property of the document called "deleted" from false to true. So, when I make a query to display the posts, I filter the posts by "delete" property.

Deleted comment example.
I used this approach because I was storing comments as sub-collection under the post document. When I perform a delete operation to a firestore document, the sub-collection under that document remains. But since I am modeling my comment thread with alternating collection-document approach (that goes multiple levels deep), I couldn’t delete all of the child collections under a post (or comment) easily since the comments sub-collections are dynamically generated. Also, I wanted to keep the replies under a deleted comment.
Challenge 2: Structuring likes data model
I wasn’t sure how to implement like/unlike feature that is scalable and meets all my querying needs. One approach I tried out was embedding. Basically, I store the likes as an array of userId inside each post. When a user likes a post, I can add their userId to the likes array (and remove it when they unlike it).
The first drawback from using this method was that a document is limited to 20k properties (or 1 megabyte), so at most, I’d be able to fit in 20k likes to a single document (or less since my post document also has other data).
The second drawback was that if I want to show all posts liked by a single user, I couldn't do so efficiently. I’d have to check all the post documents and for each post, check all the userId inside likes array that returns a match. In addition, I would be pulling more data than I actually need (if I have a lot of data in my post document).
Solution:
After doing some research, I found the middle-man-collection method to be the best option.
The idea is that I'll have 3 root level collections: users, posts, and likes. On each post document, I keep track of the total number of likes that post has received. In likes collection, each document will take care of the relationship between the two other collections. I included a postId and a userId so that I can query all the likes for a given post or all the likes for a given user (If I wish to).
I also used a cloud function to aggregate that data when a new like document is created:
exports.incrementPostLikeCount =
functions.firestore.document('likes/{likeId}').onCreate(like => {
const newLike = like.data();
const postId = newLike.postId;
return admin
.firestore()
.collection('posts')
.doc(postId)
.update({ likeCount: FieldValue.increment(1) });
})
This approach allowed my middle collection (i.e. likes) to scale up to millions of documents but I only needed to execute a single document read to show the total like count for a post.
Here is the code snippet for liking or unliking a post.
export const likeOrUnlike = ({ firebase, firestore }, postId) => {
return async (dispatch, getState) => {
const { uid } = getState().firebase.auth;
const likeId = `${uid}_${postId}`;
try {
const likeRef = await firestore.collection('likes').doc(likeId);
likeRef.get()
.then((docSnapshot) => {
if (docSnapshot.exists) {
likeRef.delete();
} else {
likeRef.set({
userId: uid,
postId
});
}
});
} catch (error) {
console.log('error', error);
toastr.error('Oops', 'Something went wrong');
}
};
};
Code snippet for determining whether the current user has liked "this" post:
export const toggleLike = (firestore, postId, setLike) => {
return async (dispatch, getState) => {
const { uid } = getState().firebase.auth;
const likeId = `${uid}_${postId}`;
try {
firestore.collection('likes').doc(likeId).onSnapshot((likeSnapShot) => {
const alreadyLiked = likeSnapShot.exists;
setLike(alreadyLiked);
});
} catch (error) {
console.log('err', error);
toastr.error('Oops', 'Something went wrong');
}
};
};
Lessons learned
By building this project, I've gotten better with tools such as react, redux, firebase, and material-UI. I also learned about things unique to Cloud Firestore, specifically:
- The importance of structuring my Firestore database with front-end UI in mind.
- Normalization vs denormalization (i.e. No duplicate data to increase maintainability vs duplicate data to increase performance).
- Taking advantage of cloud function to take away some heavy lifting from the client-side (e.g. user's browser).
Next ups
- Support for email/password-based authentication
- Follower feeds (no solution ATM)
- Optimize rendering on user profile page by skipping data fetching when that data already exists inside a redux store



Top comments (0)