Pre-Requisites
Both Java and Python are installed in your system.
Getting started with Spark on Windows
Download Apache Spark by choosing a Spark release (e.g. 2.2.0) and package type (e.g. Pre-built for Apache Hadoop 2.7 and later).
Extract the Spark tar file to a directory e.g. C:\Spark\spark-2.2.0-bin-hadoop2.7
GIT clone winutils to your system e.g. cloned to directory C:\winutils
Add below system environment variables where HADOOP_HOME is set to the winutils hadoop binary location (depending on the version of pre-built chosen earlier) and SPARK_HOME is set to the Spark location which we had extracted in step 2.
HADOOP_HOME=C:\winutils\hadoop-2.7.1
SPARK_HOME=C:\Spark\spark-2.2.0-bin-hadoop2.7
Create a new folder tmp/hive in your C: drive.
Provide permissions for the folder tmp/hive using winutils.exe by running below command in your command prompt
C:\winutils\hadoop-2.7.1\bin\winutils.exe chmod 777 C:\tmp\hive
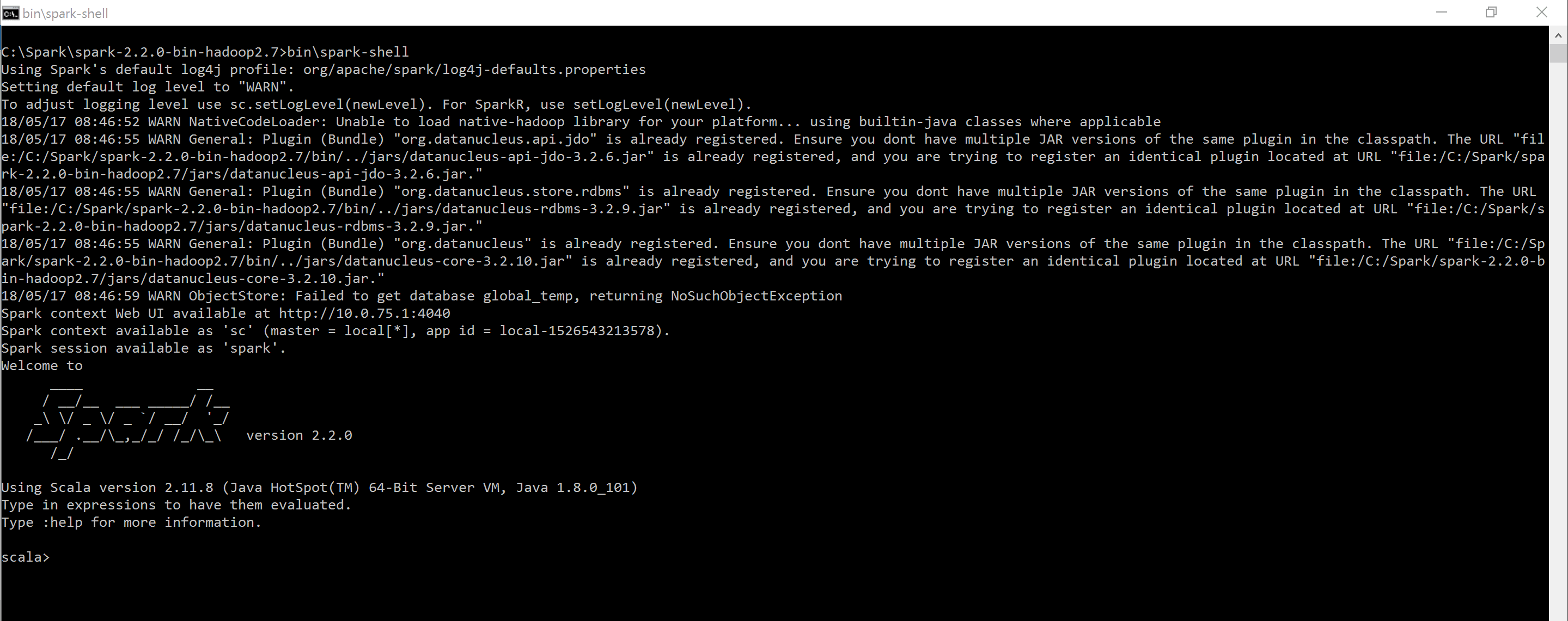
Now validate the setup by running spark-shell from your SPARK_HOME directory in your command prompt
C:\Spark\spark-2.2.0-bin-hadoop2.7>bin\spark-shell
PyCharm Configuration
Configure the python interpreter to support pyspark by following the below steps
- Create a new virtual environment (File -> Settings -> Project Interpreter -> select
Create Virtual Environmentin the settings option) - In the
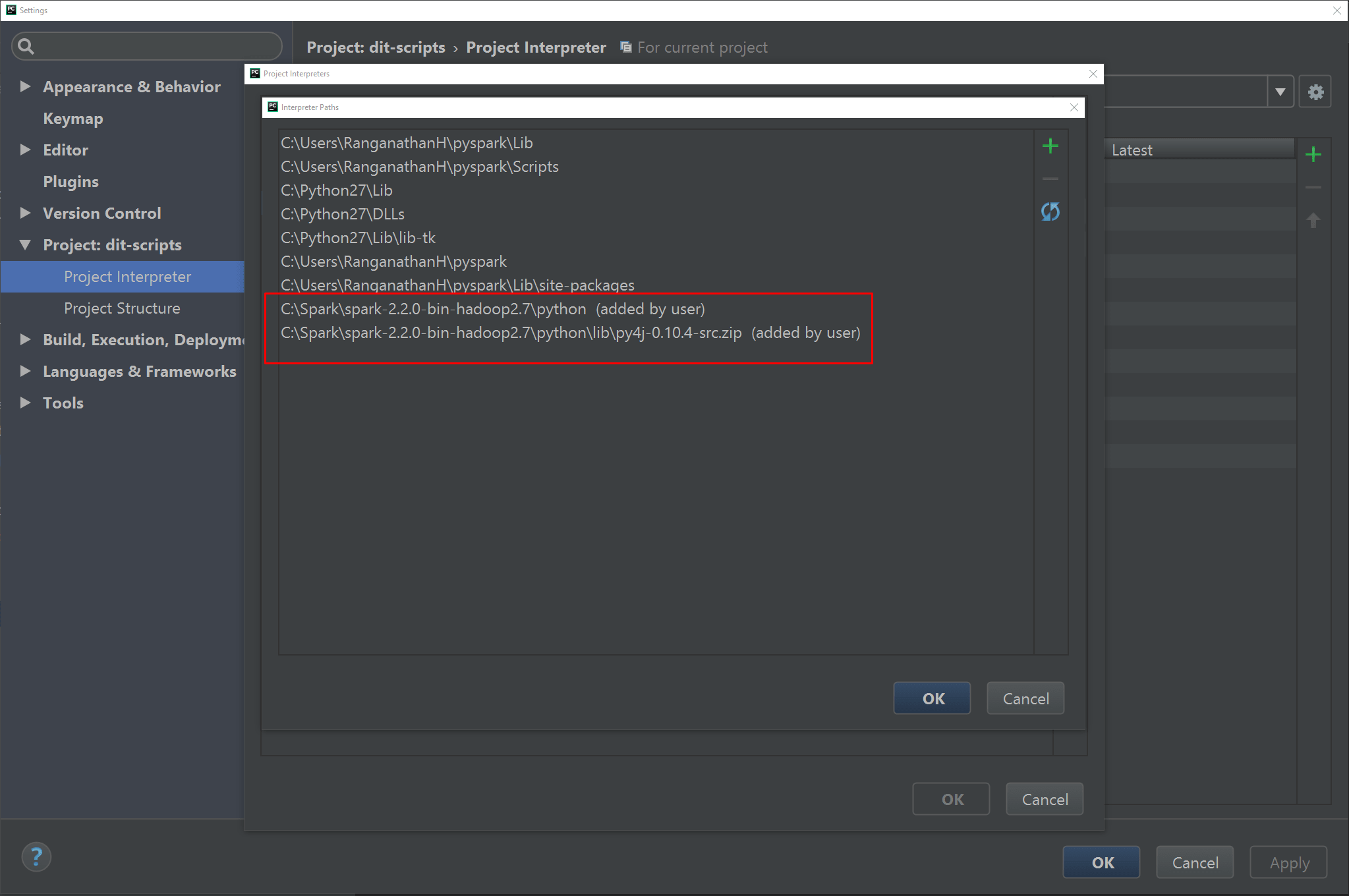
Project Interpreterdialog, selectMorein the settings option and then select the new virtual environment. Now selectShow paths for the selected interpreteroption. - Add the paths for
Spark PythonandSpark Py4jto this virtual environment as shown in the screenshot below.
Create a new run configuration for Python in the dialog Run\Debug Configurations.
In the Python interpreter option select the interpreter which we had created in the first step. Also in the Environment variables option make sure Include parent environment variables is checked.
You can now add your pyspark script to the project and use this run configuration to execute it in a Spark context.

Top comments (0)