when this started out, it was not but a journal entry. after re-reading it for studying purposes, i determined that there was enough information involved so as to be considered useful in the world. i did NOT, however, determine that i should go back and add in capitalization, or a professional tone. this here is a rundown of some Very Basic stuff that one should consider if one is interested in making one's system scalable. enjoy!
in terms of system design, when you are making a personal project, you are probably gonna start out with the whole thing on your one computer. that makes sense. you don’t have 50 computers. you don’t have 100 hands.
but, if the project that you are making gets crazy popular, and starts getting a ton of hits, what happens if your one single computer goes down, or the one web host that you are using has a pause in service, or something? your site goes down and all your users turn their backs on this project and every project you will ever make, never to trust again.
you’ll want to prevent this with a little proactive planning. maybe you decide to host with TWO web servers. eh? good for you. now, how do you decide which user will go to which web server? the client comes in, clicks something on your site, sends a packet of information and…unless you plan on hooking every client up to every server that you have, you will need a way of managing these requests, and sending them in a balanced way to your separate servers. you will need a load balancer. this is sometimes referred to as a black box. its relationships can be visually represented like this.

cool. you will need to determine some way that the load balancer makes its choices, based on how busy the servers are, just the next one in line (which is called round robin style), or what information each server is responsible for (for example, if one server only has information on images and the other server only has information on text files). how you divvy up the requests is totally up to you, that’s between you and God. and your company. and your servers. and well, also your load balancer.
the next problem is that if a client who is initially directed to server 1, somehow gets shunted off to server 2 (say, if they log in from a different device, or they use an incognito window, or something), that client will wind up with two different sessions, thereby defeating the power of sessions. the client might have a cart filled up with stuff on one session, log onto their phone, and be frustrated to see that none of their items are there anymore.
what we need are sticky sessions.
how do we get that? unless we want to do some trickery with "shared state", we need to store this information somewhere on the user. we could house the data for the specific server that the client belongs to inside of a cookie set by the load balancer. this way when the client comes back to log on, it presents its cookie, and the balancer can say oh! looks like that cookie says server one, off you go.
so that’s fantastic. but, if these servers are operating independently, and each one is trying to persist data, we will wind up with two separate databases. so instead of letting each one keep a DB, we will want to pull that out and have the DB live separately. so our chart will look like this:
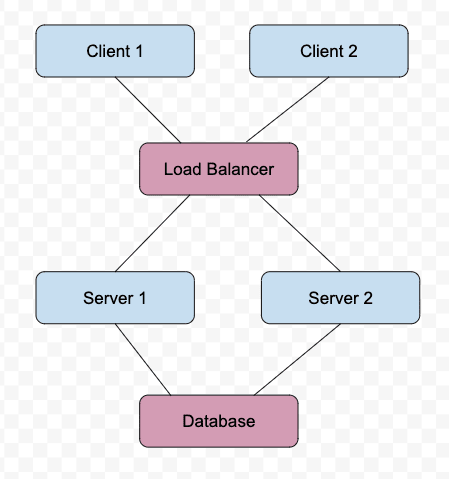
and this looks really good. i can filter clients, they can have sticky sessions with server-filled cookies dispensed by the load balancer, and i can ensure that all DB information is up to date. but there are a lot of vulnerabilities to the system, due to something called single point of failure — that is to say, there are two sections of this which depend fully upon one single machine to not fail or the whole thing goes down. It’s a replication of our original problem of only using one host. if the load balancer dies, or the DB blows up somehow, the whole operation is doomed.
counteracting that vulnerability can be surprisingly straightforward: buy two of the things that are single.
or, buy several. buying more of the thing is called horizontal scaling. You can also try a method of making your one single thing indestructible — installing the most RAM, the best software, more CPU, etc. that would be considered vertical scaling.
you get the picture. you can choose to house everything in one glimmering skyscraper, or you can choose to install fifty ground level buildings that don’t have the fanciest amenities but can handle the smaller workloads they are given. i think most opt for the ground levels, as spreading out your assets is just, inherently more secure.
with your typical load balancer that you can buy off the market for, anywhere between $3,500 and $70,00, it does usually get you two load balancers. these balancers “listen to each others’ heartbeats”, I read somewhere, which just means that they can each detect if the other is down. in an “active-active” system of load balancers, each of them always handle all the requests, and one is just temporarily given all responsibility if the other goes down. in an “active-passive” system, the active one is on the job for forever, and if the passive one ever hears of trouble, it automatically promotes itself to active, and takes over until its downed teammate is able to res.

with your typical DB…well…there are a lot of options there, but they come in a similar format to the active-active/active-passive setups. you might go with the master-master, where both databases have all information and can be read and written to, and share changes with each other. if one goes down, no biggie, the other one just manages all read and write requests. or, you might go with the master-slave approach, which just has the absolute worst name, and i think they should consider renaming it. for my own mental health, we will refer to this one as the master-understudy approach. the master stores all the information, and the understudy or understudies all store exact copies. any time something is written to the master, it is written to all others as well.
this setup is powerful for sites that have read-heavy requests, because any one of the understudies can take those requests — the master only really HAS to worry about the write requests.
if the master goes down in this case, it is only unavailable for long enough for one of the understudies to promote itself to master. then you can go to the store and grab another drive or replace the cable or fix whatever went wrong with the original db.
bear in mind that with multiple DB’s you’ve got another need for a load balancer — one to manage the which server request goes to which database at what particular time.
so now you have something that looks like this:
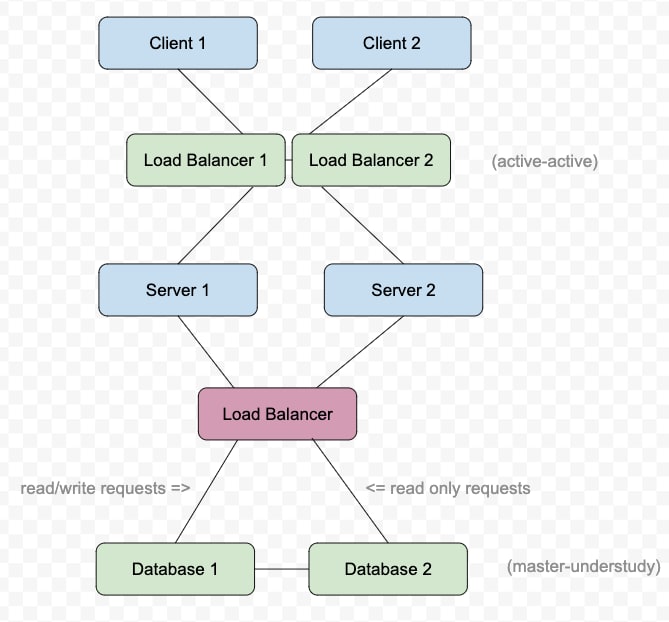
and they all live together in a happy family in their house, in the middle of their street. if the house burns down, well, that’s another single-point-of-failure-fish you would have to think about frying. perhaps, something something something The Cloud, and another house.

Top comments (0)