Introdução Big Data
Big Data é o termo para uma coleção de dados tão grande e complexa que torna difícil de se processar utilizando ferramentas de banco de dados convencional ou aplicações de processamento de dados tradicionais. Ela consiste em uma nova geração de tecnologias e arquiteturas, desenhada de maneira econômica para extrair valor de grandes volumes de dados, provenientes de uma variedade de fontes, permitindo alta velocidade na captura, exploração e análise dos dados. Os cinco Vs que regem o Big Data são:
· Velocidade: os dados são gerados com muita velocidade, a análise desses dados deve ser realizado com rapidez, para que esses dados sejam trabalhados, atualizados e expandidos com eficácia;
· Volume: os dados são gerados em grande volume diariamente, permitindo a análise das mais diversas informações. Esse fator também influencia na questão do armazenamento de dados;
· Variedade: os dados podem aparecer de diferentes formas, é necessário compreender essa variedade e identificar como devem ser analisados e armazenados;
· Veracidade: é necessário obter dados bem alinhados ao conceito de veracidade, pela necessidade constante de análise em tempo real, com os dados que condizem com a realidade;
· Valor: quanto maior a riqueza de dados, mais importante é saber realizar as perguntas certas no início de todo o processo de análise.
Os dados são divididos em Dados Estruturados (algumas características desse sistema é que possui esquema fixa, um formato bem definido, conhecimento prévio da estrutura de dados, simplicidade de dados e dificuldade para alterar o modelo) e Dados não estruturados (possui como características ser sem tipo predefinido, não possui estrutura regular, possui pouco ou nenhum controle sobre a forma, manipulação mais simplificada e facilidade de alteração do modelo).
Hadoop
O Hadoop é um framework open-source que faz uso do HDFS e do MapReduce para obter um ambiente de processamento com as seguintes características: tolerância a falhas, balanceamento de cargas, comunicação entre máquinas, distribuição de tarefas, alocação de máquinas, ordenação de dados, transferência de dados e escalonamento de Jobs;
O Hadoop não é um banco de dados, ele é um ecossistema de soluções que contém diversas ferramentas dentro dele (como o Hive, Impala, Spark, Hue, Tableau, Qlink, etc). No universo do Big Data, cada ferramenta é utilizado para resolver um problema específico. O HDFS é uma camada de armazenamento e o Yarn é gerenciador de recursos.
Cluster Hadoop é um grupo de computadores que trabalham em conjunto para armazenar e processar uma grande quantidade de dados. Com relação à arquitetura, esse cluster possui dois tipos de nodes: o master node, que gerencia toda a aplicação e o worker (slave) node, que é responsável por realizar as operações, recebendo as requisições do master node. Esses nodes são capazes de executar duas funções distintas: um função que gerencia o armazenamento distribuído e outra função que gerencia o processamento distribuído.
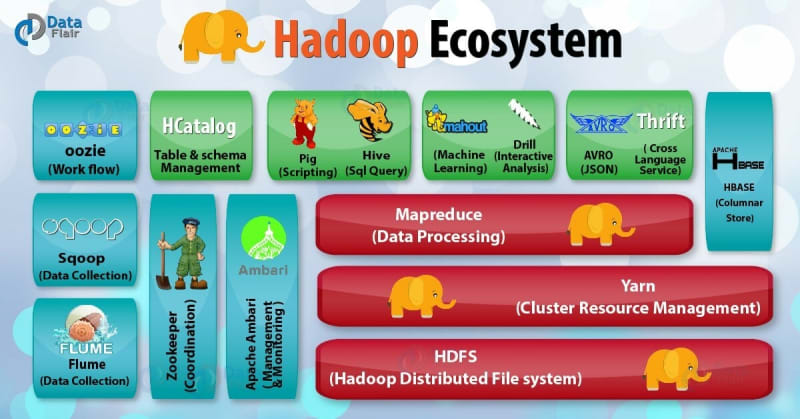
Existem serviços específicos para cada uma dessas tarefas no Hadoop. No caso do HDFS, há o NameNode (que é o Master) e os DataNode (que é o Slave). No caso do Map-Reduce, há o JobTracker (que é o Master) e os TaskTracer (que é o Slave). O NameNode é considerado o serviço principal, pois é o responsável por gerenciar o armazenamento distribuído e, por conta disso, pode ser criado o Secondary NameNode, que vai trabalhar em conjunto com o NameNode. O DataNode é quem vai armazenar os dados, de maneira distribuída. O JobTracker é responsável por disparar o seu job de processamento Map-Reduce, ele vai disparar e ser executado sobre os dados armazenados no HDFS. O JobTracker é, na verdade, o gestor, pois é ele quem vai enviar as tarefas pelo TaskTracer, que é um node slave (nó escravo) e o executor de fato.
O Apache Hadoop pode ser configurado de três formas diferentes:
· Modo Standalone = neste modo, todos os serviços Hadoop são executados em uma única JVM, em um mesmo servidor. Temos os master e os slaves rodando em uma única máquina, sendo muito utilizado para testar uma aplicação;
· Pseudo Distribuído = serviços individuais do Hadoop são atribuídos a JVM's individuais, no mesmo servidor. Ou seja, neste modo nós temos ainda uma única máquina, como o modo standalone, a diferença é que há uma JVM para cada um dos serviços. A vantagem deste modo é que, se uma das JVM's apresentar algum problema, os demais serviços não serão afetados. Esta também é uma forma muito utilizada para ambientes de testes, mas requer mais uso de memória do computador;
· Totalmente Distribuído = serviços individuais do Hadoop são executados em JVM's individuais, mas através de cluster. Ou seja, há uma JVM em cada máquina, aonde teremos cada um dos sistemas Hadoop sendo executados. Este modo é utilizado para o ambiente de produção (ambiente real).
O Cache Distribuído (Distributed Cache) é uma funcionalidade do Hadoop que permite cache dos arquivos usados pelas aplicações, o que permite ganhos consideráveis de performance quando tarefas de map e reduce precisam acessar dados em comum. Além disso, permite que um node do cluster acesse os arquivos do filesystem local, ao invés de solicitar o arquivo em outro node. É possível fazer o cache de arquivos zip e tar.gz. Uma vez que você armazena um arquivo em cache para o seu trabalho, a estrutura Hadoop irá torná-lo disponível em cada node (em sistema de arquivos, não em memória), onde as tarefas de mapeamento/redução estão em execução.
Com relação a segurança, o Hadoop utiliza o Kerberos, que é um mecanismo de autenticação usado no sistema de diretórios dos servidores Windows e no sistema operacional Linux. Por padrão, o Hadoop é executado no modo não seguro, em que não é necessária a autenticação real. Após ser configurado, o Hadoop é executado em modo de segurança e cada usuário e serviço precisa ser autenticado pelo Kerberos, a fim de utilizar os serviços do Hadoop. Depois que o Kerberos estiver configurado, a autenticação é utilizada para validar as credenciais do lado do cliente. Isso significa que o cliente deve solicitar uma permissão de serviço válido para o ambiente Hadoop.
HDFS
O HDFS (Hadoop Distribution File System) cria uma camada de abstração desses cluster de máquinas e permite que você salve e recupere informações dentro deste cluster. Ou seja, o HDFS é responsável por disponibilizar apenas um diretório e você irá salvar e recuperar as informações dentro dele, sem ter que se preocupar com a quantidade de máquinas que há neste cluster. Além disso, o HDFS pega um arquivo, divide-o em vários "pedaços" e os distribui para várias máquinas (além de copiar ele e gravar as cópias em lugares distintos), permitindo que o sistema seja escalável e tolerante a falhas (redundância).
O Cluster Hadoop possui uma funcionalidade chamada de hot swop, que permite tirar um computador da rede (com o cluster funcionando), fazer a manutenção neste computador e colocá-lo novamente no cluster, sem precisar ter que desativá-lo da rede.
A escalabilidade garante que, se você tentar acessar um arquivo em um determinado node e toda a capacidade de processamento deste node já está sendo utilizada em outros Jobs, o cluster irá então te redirecionar para buscar o arquivo em outro node que o possua e que ainda não está com toda sua capacidade de processamento ocupada, evitando que você precise ficar esperando até que o node termine os processamentos e libere espaço para novos Jobs.
Map-Reduce
O Map-Reduce é um paradigma de programação que facilita a execução de aplicações que processam um grande volume de dados que estão sendo distribuídos em um cluster de milhares de nós de hardware convencional de maneira tolerantes a falhas.
Por exemplo, vamos contar quantas vezes a palavra "Harry Potter" é citado no primeiro volume da saga. Para isso, vamos salvar o conteúdo do livro no HDFS que, por sua vez, irá salvar cada um dos capítulos em uma máquina do Cluster, com replicabilidade de 3 (redundância de 3x para cada um dos capítulos). Utilizando a tecnologia de Map-Redude, podemos fazer esta contagem rapidamente. Na etapa de Map, cada máquina vai pegar um capítulo inteiro e contar quantas vezes a palavra "Harry Potter" aparece em cada um dos capítulo, de forma simultânea. Após terminar a contagem, entra a etapa de Reduce, onde iremos consolidar essas informações. É nesta etapa que será somado o total da contagem da palavra de cada um dos capítulos, encontrando o total de vezes que a palavra "Harry Potter" apareceu no primeiro livro da saga. Como cada máquina realizou a contagem dos capítulos em paralelo, este tipo de tecnologia é capaz de processar um grande volume de dados de forma muito mais rápida e eficiente do que a abordagem de tradicional (contagem de forma sequencial).
O Map-Reduce permite a execução de queries ad-hoc (ou seja, é capaz de fazer consultas locais, sem a necessidade de uma interface gráfica) em todo o conjunto de dados em um tempo escalável. O segredo da sua performance está no balanceamento entre seeking e transfer: reduzir operações de seeking e usar de forma efetiva as operações de transfer. Seek time é o delay para encontrar um arquivo. Já o transfer rate é a velocidade para encontrar o arquivo (que tem melhorado de forma significante) e é bem mais veloz que o seek time.
O Map-Reduce é muito utilizado para atualizar todo (ou a maior parte) de um grande conjunto de dados. O RDBMS (Relational Database Management System) - Banco de dados relacional é ótimo para atualizar pequenas proporções de grandes bancos de dados. Eles utilizam o tradicional B-Tree, que é altamente dependente de operações de seek. Além disso, eles utilizam operações de SORT e Merge para recriar o banco de dados, o que é mais dependente de operações de transfer.
Com relação à arquitetura o Map-Reduce funciona através de duas operações. No processo de mapeamento, os dados são separados em pares (key-value pairs), transformados e filtrados. Então, os dados são distribuídos para os nodes e processados. No processo de redução, os dados são agregados em conjuntos de dados (datasets) menores. Os dados resultantes do processo de redução são transformados em um formato padrão de chave-valor (key-value), onde a chave (key) funciona como o identificador do registro e o valor (value) é o dado (conteúdo) que é identificado pela chave.
O processo de Map-Reduce se inicia com a requisição feita pelo cliente e o job submetido, e o JobTracker se encarrega de coordenar como o job será distribuído. Depois, no mapeamento dos dados, os dados de entrada são primeiramente distribuídos em pares key-value e divididos em fragmentos, que são então atribuídos a tarefas de mapeamento. Na etapa de redução dos dados, cada operação de redução dos dados tem um fragmento atribuído. Por fim, o processo é executado e o resultado final é gerado.
Apache Zookeeper
O Apache Zookeeper é uma solução open-source de alta performance para coordenação de serviços em aplicações distribuídas, ele é uma espécie de guardião do Zoo (ferramentas do Hadoop).
Apache Oozie
O Apache Oozie é um sistema de agendamento de workflow usado para gerenciar principalmente os Jobs de MapReduce. Ele é integrado com o restante dos componentes do ecossistema Hadoop para apoiar vários tipos de trabalhos do Hadoop (como Java Map-Reduce, streaming Map-Reduce, Pig, Hive e Sqoop), bem como jobs específicos do sistema (como programas Java e scripts shell).
O Oozie é um sistema de processamento de fluxo de trabalho que permite aos usuários definir uma série de Jobs escritos em diferentes linguagens e, então, liga-los um ao outro. Ele permite aos usuários especificar, por exemplo, que uma determinada consulta só pode ser iniciado após os jobs anteriores que acessem os mesmo dados sejam concluídas.
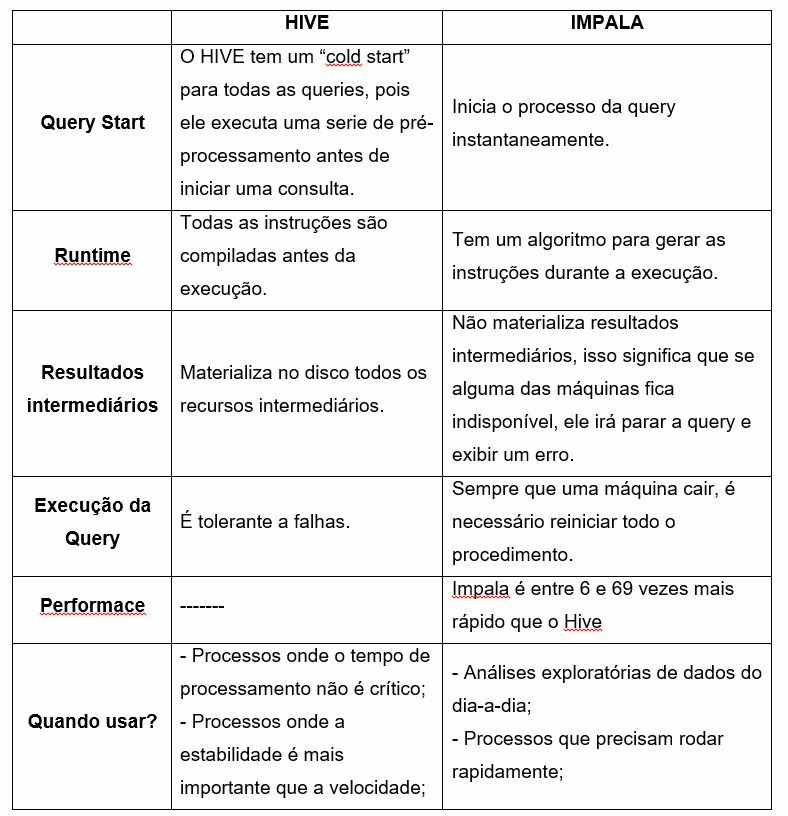
Hive vs Impala__
Hive e Impala são projetos de software que foram desenvolvidos para facilitar a construção de queries no ambiente Hadoop por meio de uma interface SQL.
O Apache Hive é um Data Warehouse que funciona com Hadoop e MapReduce. Ele permite consultas sobre os dados usando uma linguagem tipo SQL, chamada de HiveQL (HQL), além disso, ele provê capacidade de tolerância a falha para armazenamento de dados e depende do MapReduce para execução. O Hive permite conexões JDBC/ODBC, e por isso, é facilmente integrado com outras ferramentas de inteligência de negócios como Tableau, Microstrategy, Microsoft Power Bi, etc. Ele é orientado a batch e possui alta latência para execução de queries.
As principais diferentes entre os dois projetos de software são:
YARN
O YARN possui um Resource Manager Global (que conhece todos os recursos do Cluster) e cada nó (maquina) possui um Resource Manager Local, que gerencia os recursos locais daquela máquina. Quando a aplicação for rodar, ela "pede" recursos para o Resource Manager Global, que vai alocar em uma das máquinas o Application Master (que gerencia a aplicação), que, por sua vez, irá alocar recursos em cada uma das máquinas.
HBase
O HBase é um grande banco de dados distribuído, que permite acessar grandes volumes de dados de maneira rápida, rodando em conjunto com o Hadoop. O seu objeto é armazenar tabelas realmente grandes, com bilhões de registros. Ele é um banco de dados NoSQL e aproveita a tolerância a falhas fornecidas pelo sistemas de arquivos do HDFS. O Hbase é organizado como um banco de dados chave-valor, cada conjunto de colunas são organizados em famílias. Para se encontrar um dado, é preciso ter uma chave, uma família de colunas e a coluna desejada, além disso, cada célula possui versões, que guardam as informações que foram modificados ao longo do tempo, geralmente organizada através do formato timestamp (data e hora).
Com relação à sua arquitetura, o HBase possui dois tipos de node, o Master e o RegionServer. Somente um node Master pode ser executado, a alta disponibilidade é mantida pelo ZooKeeper. O Master é responsável pela gestão de operações de cluster, como assignment, load, balancing e splitting. Ele não faz parte de operações de read/write. Já o RegionServer é responsável por armazenar as tabelas, realizar leituras e buffers de escrita e pode existir um ou mais deles em uma aplicação (o cliente comunica o RegionServer para processar as operações de read/write).
Spark
O Spark é um framework que surgiu para solucionar alguns problemas que os usuários tinham com o Map-Reduce (como rodá-lo várias vezes). Ele é uma engine de computação distribuída (por exemplo, se você quiser executar uma query, o Spark vai pegar e quebrar estar query em diversas query menores e, depois, vai distribui-las nos nós de Cluster e vai gerenciar todos esses cálculos/tarefas. Por fim, ele vai consolidar todas as tarefas após a conclusão das mesmas e gerar o resultado final da query).
O Spark é capaz de rodar o código em paralelo, permitindo que o programador construa o algoritmo pensando no encadeamento de funções e, no final, execute uma função que colete os resultados. Ele trabalha sempre em memória (não persiste os dados em disco, ao menos que você peça isso a ele), ao contrário do Map-Reduce.
Apesar do Spark perder do Map-Reduce em termos de resiliência, ele é capaz de realizar as query de maneira muito mais rápida. O Spark foi construído com a linguagem Scala, mas possui APIs para diversas linguagens de programação, como o Java, Python e R.
Apache Storm
O Apache Storm se tornou o padrão para processamento de dados em tempo real distribuído e permite processar grandes quantidades de dados. Ele foi criado para processar grandes quantidades de dados em ambientes tolerantes a falhas e escaláveis (basicamente, ele é um framework para streaming de dados e possui uma alta taxa de ingestão de dados).
Apache Sqoop
Sqoop é um projeto do ecossistema do Apache Hadoop, cuja responsabilidade é importar e exportar dados de bandos relacionais. Sqoop significa SQL-to-Hadoop. É possível importar tabelas individuais ou bancos de dados inteiros para o HDFS e o desenvolvedor pode determinar que colunas ou linhas serão importadas. Ele é uma ferramenta desenvolvida para transferir dados do Hadoop para RDBMS e vice-versa.
O Sqoop também pode gerar classes Java, através das quais o desenvolvedor pode facilmente interagir com os dados importados. Ele utiliza conexão JDBC para se conectar com os bancos de dados relacionais e pode criar tabelas diretamente no Hive, além de suportar importação incremental.
Apache Pig
O Apache Pig é uma ferramenta utilizada para analisar grandes conjuntos de dados que representam fluxos de dados e, com ele, podemos realizar todas as operações de manipulação de dados no Hadoop. Para analisar dados usando o Apache Pig, os programadores precisam escrever scripts usando linguagem Pig Latin, e todos esses scripts são convertidos internamente para tarefas de mapeamento e redução.
O Apache Pig tem um componente chamado de Pig engine, que aceita os scripts Pig Latin como entrada e converse esses scripts em Jobs MapReduce. Ele possui basicamente dois componentes: o Pig Latin Script Language (que é uma linguagem procedural de fluxo de dados que contém sintaxe e comandos que podem ser aplicados para implementar lógica de negócios) e o Runtime engine (que é o compilador que produz sequencias de programas MapReduce, utilizando HDFS para armazenar e buscar dados, e é usado para interagir com sistemas Hadoop. Além disso, ele também valida e compila scripts em sequências de jobs MapReduce).
Apache Flume
O Apacher Flume é um serviço que permite enviar dados diretamente para o HDFS. Ele foi desenvolvido pela Cloudera e permite mover grandes quantidades de dados, além de ser um serviço que funciona em ambiente distribuído para coletar, agregar e mover grandes quantidades de dados de forma eficiente. Ele possui uma arquitetura simples e flexível baseada em streaming (fluxo constante) de dados.
O modelo de dados do Flume permite que ele seja usado em aplicações analíticas online, além de poder ser usado em Infraestrutura de TI. Os agentes são instalados em servidores web, servidores de aplicação ou aplicativos mobile, para coletar e integrar os dados com Hadoop para análise online.
Apache Mahout
O Apache Mahout é uma biblioteca open-source de algoritmos de aprendizado de máquina, escalável e com foco em clustering, classificação e sistemas de recomendação. Ele é dedicado ao Machine Learning. Ele permite a utilização dos principais algoritmos de clustering, teste de regressão e modelagem estatística e os implementa usando um modelo MapReduce. Para saber se a sua aplicação precisa usar o Mahout, você precisa levar em consideração se seu projeto atende estes quatro pontos: utiliza algoritmos de Machine Lerning com alta performance; precisa ser um software open-source e gratuito; possui um grande conjunto de dados (Big Data) e você pretende utilizar ferramentas de análise como R, Python ou Octave; e o processamento de dados será feito usando um modelo de batch (ou seja, que não precisa utilizar dados gerados em tempo real).
Apache Kafka
O Apache Kafka é um sistema para gerenciamento de fluxos de dados em tempo real, gerados a partir de web sites, aplicações e sensores. Essencialmente, ele age como uma espécie de "sistema nervoso central", que coleta dados de alto volume, como por exemplo, a atividade de usuários (clicks em um web site), logs, cotações de ações, etc. Depois disso, ele torna estes dados disponíveis como um fluxo em tempo real para o consumo por outras aplicações. Ele foi desenvolvido com o propósito de servir como um repositório central de fluxos de dados.
HCatalog
O HCatalog É uma tabela e uma camada de gerenciamento de armazenamento para Hadoop, ele suporta diferentes componentes disponíveis no ecossistema Hadoop, como o MapReduce, Hive e o Pig para facilmente ler e escrever dados do cluster. Ele é um componente chave do Hive que permite que o usuário armazene seus danos em qualquer formato ou estrutura.
Avro
Avro é um projeto open source que fornece serialização de dados e serviços de troca de dados, e esses serviços podem ser usados juntos ou de forma independentes. O uso de programas de serviço de serialização pode serializar dados em arquivos ou mensagem.
O Avro schema depende de esquemas para serialização/desserialização e requer esquemas de leitura e gravação de dados. Quando os dados Avro são armazenados em um arquivo, seu esquema é armazenado com ele, para que possam ser processados posteriormente por qualquer programa. A tipagem dinâmica se refere à serialização e desserialização, ele complementa a geração do código que está disponível no Avro para uma linguagem tipada estatisticamente.
Thrift
O Thrift é uma estrutura de software para o desenvolvimento escalável de serviços entre linguagens. Ele é uma linguagem de definição de interface para comunicação RCP (Remote procedure call). O Hadoop faz várias chamadas RCP e, portanto, há a possibilidade de usar o componente Thrift para performance e outros fins.
Apache Drill
O Drill foi o primeiro mecanismo de consulta SQL que possui um modelo sem esquema. Ele possui um sistema de gerenciamento de memória especializado para eliminar o garbage collection e o uso da memória. O Drill funciona bem com o Hive, permitindo que os desenvolvedores reutilizem sua implantação existente do Hive. Algumas das vantagens de se utilizá-lo são:
· Extensível: o Drill fornece uma arquitetura extensível em todas as camadas, inclusive camadas de consultas, otimização de consultas e client API. Podemos estender qualquer camada para a necessidade específica de uma organização;
· Flexibilidade: ele fornece um modelo de dados colunar hierárquico que pode representar dados complexos e altamente dinâmicos, além de permitir um processamento eficiente;
· Descoberta de esquemas dinâmicos: ele não necessita de esquemas ou especificação de tipos para começar os processos de consultas. Em vez disso, o Drill começa a processar os dados em unidades chamados de record batches e descobre o esquema durante o processamento;
· Metadados descentralizados do Drill: diferentemente de outras tecnologias Hadoop de SQL, o Drill não possui requisitos de metadados centralizados. Seus usuários não precisam criar e gerenciar tabelas em metadados para consultar dados.
Ambari
Ambari é uma plataforma de gerenciamento para provisionar, gerenciar, monitorar e proteger o cluster do Apache Hadoop. O gerenciamento do Hadoop fica mais simples à medida em que o Ambari fornece uma plataforma consistente e segura para o controle operacional.
Análise de Dados (Tipos de Dados)
Os dados podem ser de dois tipos:
· Qualitativa/Categórica: são operações aritméticas que não podem ser aplicadas aos seus valores, são divididas em:
o Nominal: as variáveis são medidas em classes discretas, mas não é possível definir uma ordem. Ex: matemática, física, química;
o Ordinal: as variáveis são medidas em classes discretas entre as quais é possível definir uma ordem, segundo uma relação descritível, mas não quantificável. Ex: feminino/masculino, 0/1, etc.
· Quantitativa/Numérica: são operações aritméticas que podem ser aplicadas aos seus valores, sendo dividida em:
- Discretas: são variáveis que contém um número finito ou infinito enumerável de valores. Ex: 23, 46, 56, etc;
- Contínuas: são variáveis que podem assumir um número infinito de valores, mas são enumeradas. Ex: peso, altura, salário, etc.
Categorias de Bancos de Dados NoSQL
Os bancos de dados NoSQL são divididos em quatro categorias principais:
· Graph databases = esta categoria geralmente é aderente a cenários de rede social online, onde os nós representam as entidades e os laços representam as interconexões entre elas. Dessa forma, é possível atravessar o grafo seguindo as relações. Essa categoria têm sido usada para lidar com problemas relacionados a sistemas de recomendação e listas de controle de acesso, fazendo uso de sua capacidade de lidar com dados altamente interligados e é muito utilizada para o desenvolvimento de redes sociais. Ex: Neo4j, FlockDB, GraphDB, ArangoDB;
· Document databases = esta categoria permite o armazenamento de milhões de documentos. Por exemplos, podemos armazenar detalhes sobre um empregado, junto com o currículo dele (como um documento) e então pesquisar sobre potenciais candidatos a uma vaga, usando um campo específico, como telefone ou conhecimento em uma tecnologia. Ex: MongoDB, CouchDB, RavenDB, Terrastore;
· Key-values stores = nesta categoria os dados são armazenados no formado key-value (chave-valor) e os valores (dados) são identificados pelas chaves. É possível armazenar bilhões de registros de forma eficiente e o processo de escrita é bem rápido. Os dados podem ser então pesquisados através das chaves. Ex: Oracle NoSQL BD, MemcacheDB, Redis, AWS DynamoDB;
· Column Family stores = também chamados de bancos de dados orientados a coluna, os dados organizados em grupos de colunas e tanto o armazenamento quanto as pesquisas de dados são baseados em chaves. Ex: HBase, Cassandra, Hypertable, Accumulo.
Referências
· https://data-flair.training/blogs/hadoop-ecosystem-components/
· https://www.alura.com.br/curso-online-intro-engenharia-de-dados
· https://www.datascienceacademy.com.br/





Top comments (1)
Que material sensacional, obrigado por compartilhar!