
In this text I will explain what is spell correction in the area of search functionality, how it works in Google, Amazon and Pinterest and will demonstrate how to make your own implementation from the ground up using custom search engine Manticore Search
Spell correction also known as:
- Auto correction
- Text correction
- Fixing a spelling error
- Typo tolerance
- “Did you mean?”
and so on is a software functionality that suggests you alternatives to or makes automatic corrections of the text you have typed in.
The concept of correcting typed text dates back to the 1960s, says Brad Myers, a professor of interface design at Carnegie Mellon University. This’s when a computer scientist named Warren Teitelman who also invented the “undo” command came up with a philosophy of computing called D.W.I.M., or “Do What I Mean.” Rather than programming computers to accept only perfectly formatted instructions, Teitelman said we should program them to recognize obvious mistakes.
The first well known product which provided spell correction functionality was Microsoft Word 6.0 released in 1993.
Nowadays people can’t imagine their real life without messaging, searching, browsing and using different business applications: text editors, content management systems (CMS), customer relationship management systems (CRM) and others. And in all of them people do typing mistakes, forget proper spelling of words, sometimes are wrong with grammar and so on. This is absolutely fine, everybody makes mistakes. What a good software does is helping you fix those mistakes the easiest and most efficient way. There are many approaches how it can do that: both from how it looks for a user and what value it brings and how it’s made under the hood.
In this article we will focus specifically on search systems as for them it’s especially important to correct your search query before (or while) it’s processed since otherwise your search results may be absolutely wrong.
Different approaches to autocorrect
In terms of user experience we can split the approaches into 2 groups:
- within the first one a system tries to correct your text right as you type it
- within another it takes it as a given and gives you suggestions afterwards
In most cases these approaches are combined so a system tries to correct you as you type and if it thinks there’s still some issue — suggests you a correction after you get the search results.

- Autocorrect — corrects wrong typed query immediately
- Autocomplete — another big feature many modern sites have which is often combined with the autocorrect functionality
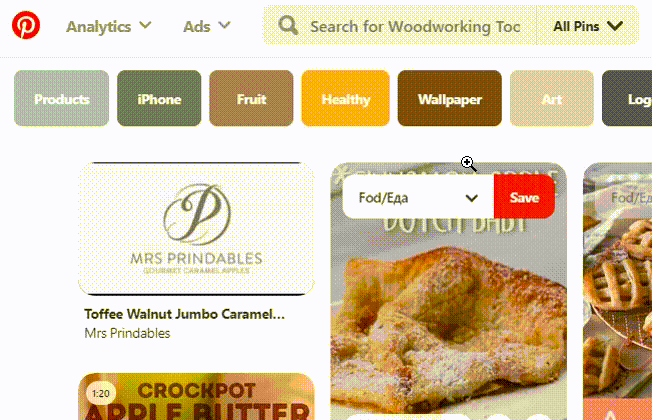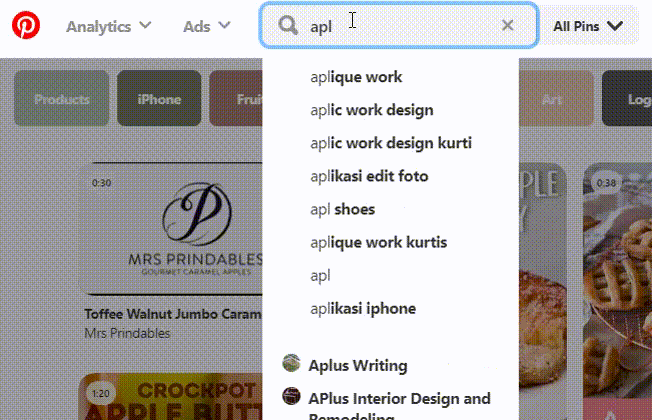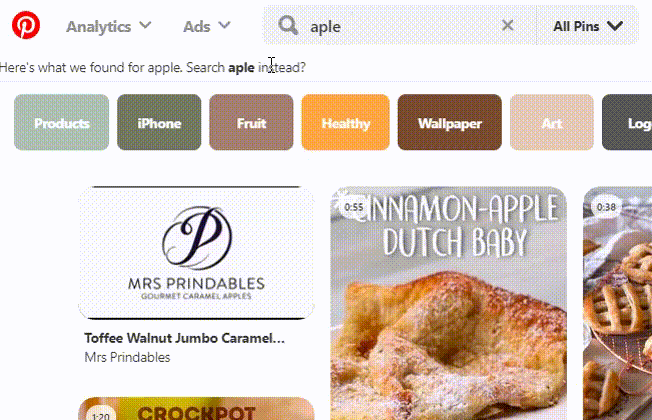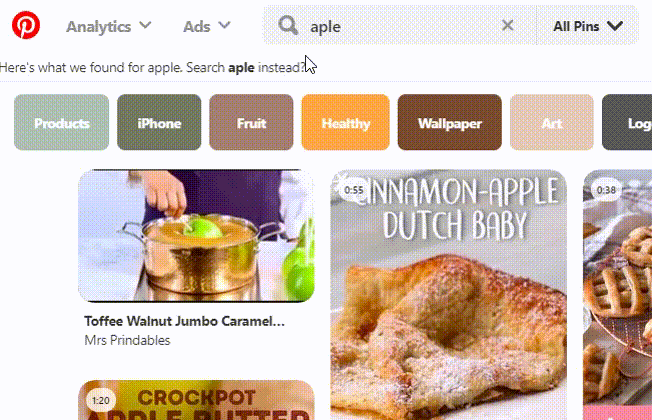
- Suggestions — it’s kind of a mix of autocomplete and autocorrect which often looks like suggesting you smth a little bit different from what you’re typing in, but still making sense (see the picture below)
- Highlighting of mistakes — another nice feature is mistake highlighting. It can also be done both as you type and afterwards
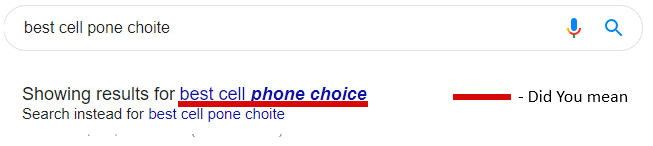
- “Did you mean” — many systems recommend you refined search queries not only while you are typing, but when displaying the search results too. We call it “did you mean … ?”. In its turn there are 2 patterns:
- Search by your original search query and just show you the recommended one (as Google does)
- Or search by the refined one and suggest to “search for instead”
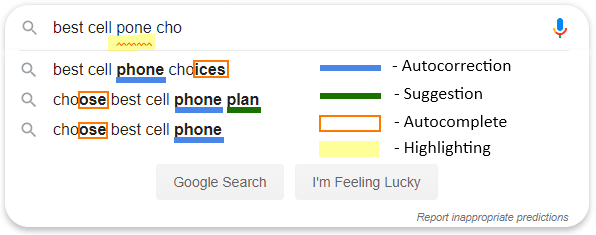
As you type components:
After the query:
Let me demonstrate you with pictures how different popular sites use the aforementioned techniques.
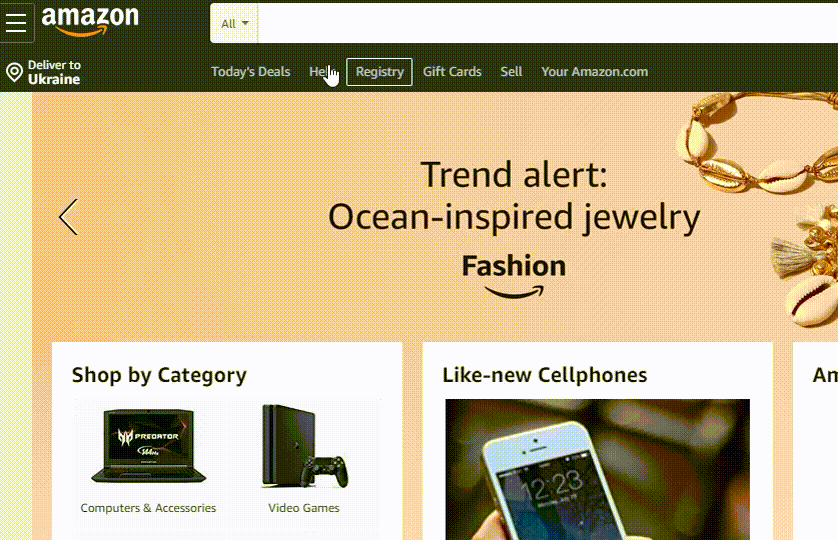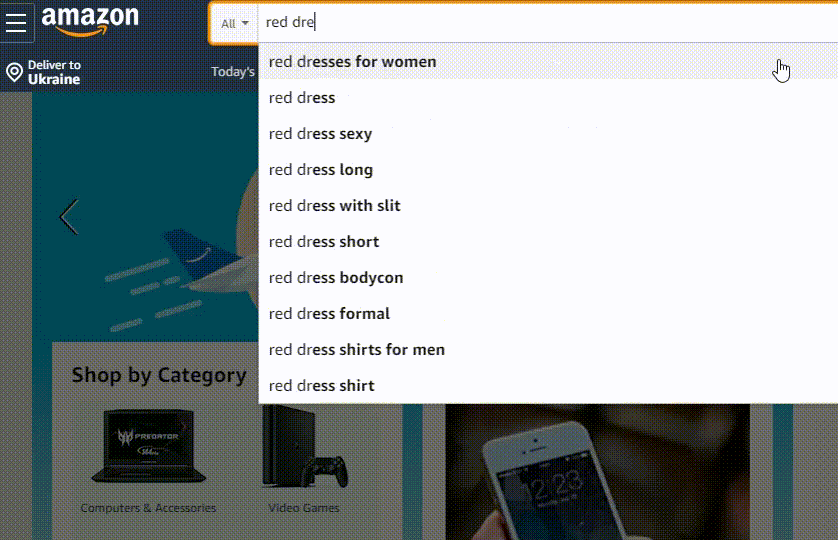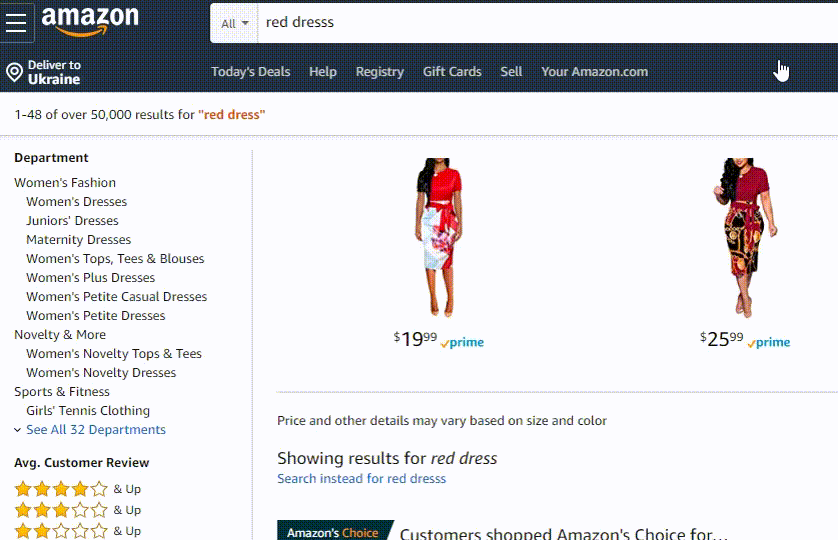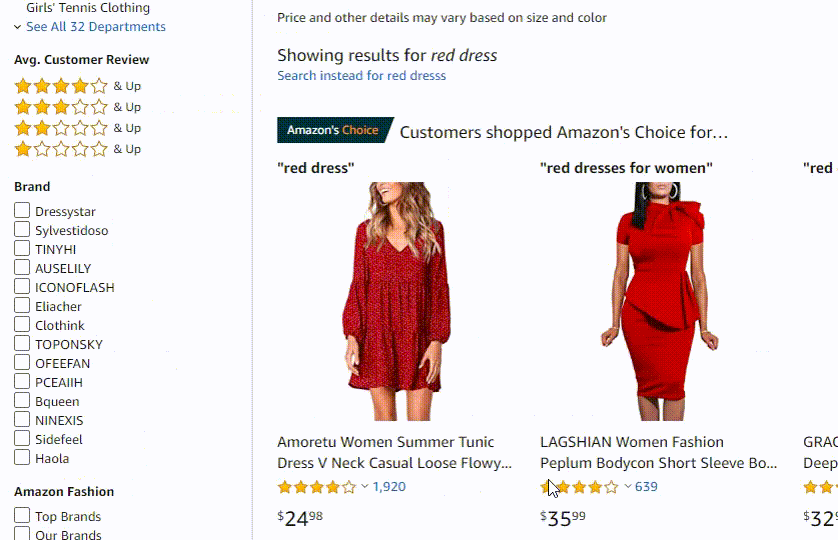
Google as the site #1 in the Internet does everything: autocorrect, autocomplete, suggestions, mistake highlighting and “did you mean”. Google uses a prediction service to help complete searches and even URLs typed in the address bar: These suggestions or predictions (as Google names that) are based on related web searches, your browsing history, and Google’s websites ranking.
Amazon uses eCommerce oriented search algorithm called A9. What differs it from Google’s algorithm is that it puts a strong emphasis on sales conversions.
In terms of Amazon’s autocorrect implementation it consists of all the previously mentioned components, but since it’s a marketplace its suggestions ranking formula seems to include the factor of how attractive a suggestion can be to you in terms of sales.
Pinterest also has its own algorithm based on internal domain/pins/pinners relevance.
How it works
Let’s now think about how spell correction can be done. There are few ways, but the important thing is that there is no purely programmatic way which will convert your mistyped “ipone” into “iphone” (at least with decent quality). Mostly there has to be a data set the system is based on. The data set can be:
- A dictionary of properly spelled words. In its turn it can be:
- Based on your real data. The idea here is that mostly in the dictionary made up from your data the spelling is correct and then for each typed word the system just tries to find a word which is most similar to that (we’ll speak about how exactly it can be done shortly)
- Or can be based on an external dictionary which has nothing to do with your data. The problem which may arise here is that your data and the external dictionary can be too different: some words may be missing in the dictionary, some words may be missing in your data. E.g. like in these cases:

But it might still make sense for smaller data collections as then there’s a higher chance the search query will be corrected at all
- Not just dictionary-based, but context-aware, like if I search for “white ber” Google understands that I mean a bear:
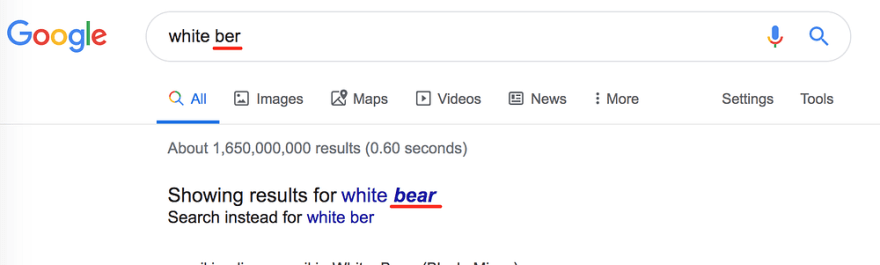
But if I change it to “dark ber” it understands I mean beer:
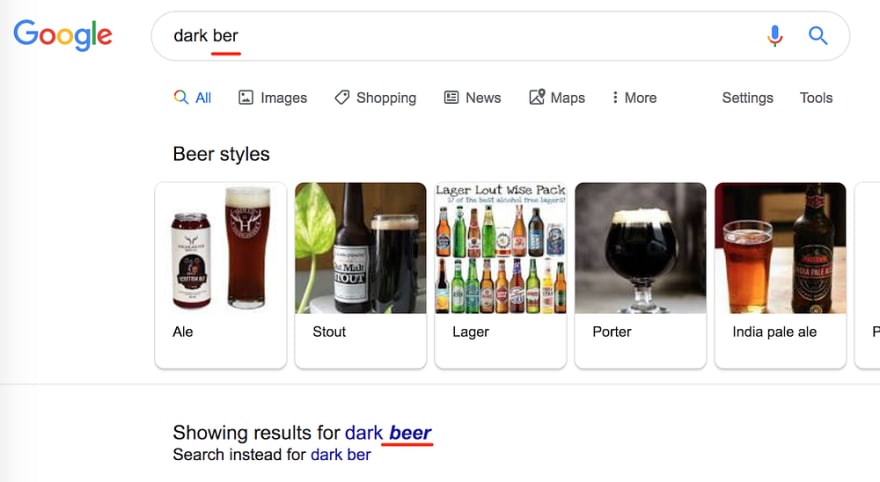
The context may be not just a neighbour word in your query, but your location, date of time, current sentence’s grammar (to let’s say change “there” to “their” or not), your search history and virtually any other things that can affect your intent.
- Another classical approach is to use previous search queries as the data set for spell correction. It’s even more utilized in autocomplete functionality, but makes sense for autocorrect too. The idea here is that mostly users are right with spelling, therefore we can use words from their search history as a source of truth even if we don’t have the words in our documents nor we use an external dictionary. Context-awareness is also possible here.
- Another approach is to use your users’ previous search queries and/or your dictionary and/or documents to figure out some correction rules and use just them to correct new search queries. There’s even a patent about this https://patents.google.com/patent/US6618697B1/en
For all the approaches can be used different algorithms of searching and evaluation of candidate spell corrections:
- From simplest like just comparison of a given word with all the words in the dictionary
- Early rejects algorithms that allow to narrow down the list of candidates significantly (that we will look in details below)
- Finite automatons of different kinds to improve performance of finding candidates (Lucene’s way)
- Probabilistic models, e.g. Hidden Markov Model that Etsy utilize on a basis of previous search queries
- To different machine learning techniques that often require large training data
Looking at how fast AI, machine learning and semantic search have been evolving lately I believe in this decade the landscape of spell correction techniques may change dramatically, but for now the above approaches seem to be most used. And most solutions are based on your existing data collection and the dictionary made up from it.
How to write your custom auto-correct
Here I will describe a part of my own experience with making a website search with help of Manticore Search. I discovered this product about a year ago while working on some clients projects and I’m still using it in few of my projects due to its lightweight and fast search with a lot of out of the box functions.
Let’s now speak about what tools you can use to add the autocorrect functionality to your system and at the same time go a little bit deeper into understanding how at least simpler techniques work.
Todo that we will take one of popular custom search engines as they often provide the functionality we’re looking for. I like Manticore Search as in contrast to more known Elasticsearch, it is much more lightweight, easier to deal with as it’s SQL-native and works faster in most cases. It’s so SQL native that you can even connect to it with a standard MySQL client. They provide an official docker image, so I’ll use that to demonstrate how autocorrect works in Manticore Search:
➜ ~ docker run --name manticore -d manticoresearch/manticore
1ac28e94b3ca728fb431ba79255f81eb31ec264b5d9d49f1d2db973e08a32b9f
And inside the container I’ll run mysql to connect to the Manticore Search server running there:
➜ ~ docker exec -it manticore mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.5.21
Copyright © 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
It ships with 2 test tables that we can use for a quick play with spell correction:
MySQL [(none)]> show tables;
+--------+-----------+
| Index | Type |
+--------+-----------+
| pq | percolate |
| testrt | rt |
+--------+-----------+
2 rows in set (0.00 sec)
Let’s check the schema of testrt:
MySQL [(none)]> describe testrt;
+---------+--------+------------+
| Field | Type | Properties |
+---------+--------+------------+
| id | bigint | |
| title | field | stored |
| content | field | stored |
| gid | uint | |
+---------+--------+------------+
4 rows in set (0.00 sec)
and insert few documents into it. Let it be movie titles:
MySQL [(none)]> insert into testrt(title) values('The Godfather'),('The Wizard of Oz'),('Combat!'),('The Shawshank Redemption'),('Pulp Fiction'),('Casablanca'),('The Godfather: Part II'),('Mortal Kombat'),('2001: A Space Odyssey'),('Schindler\'s List');
Query OK, 10 rows affected (0.00 sec)
We can now see all our documents in the index:
MySQL [(none)]> select * from testrt;
+---------------------+------+--------------------------+---------+
| id | gid | title | content |
+---------------------+------+--------------------------+---------+
| 1657719407478046741 | 0 | The Godfather | |
| 1657719407478046742 | 0 | The Wizard of Oz | |
| 1657719407478046743 | 0 | Combat! | |
| 1657719407478046744 | 0 | The Shawshank Redemption | |
| 1657719407478046745 | 0 | Pulp Fiction | |
| 1657719407478046746 | 0 | Casablanca | |
| 1657719407478046747 | 0 | The Godfather: Part II | |
| 1657719407478046748 | 0 | Mortal Kombat | |
| 1657719407478046749 | 0 | 2001: A Space Odyssey | |
| 1657719407478046750 | 0 | Schindler's List | |
+---------------------+------+--------------------------+---------+
10 rows in set (0.00 sec)
What has just happened: when we inserted the titles not just Manticore Search saved them as is, but it made a lot of things essential for natural language processing (NLP): tokenization (to split the titles into words), normalization (to lowercase everything) and many other things, but there was one important for us which is that it has split the words into trigrams they consist from. For example “Combat!” (or actually “combat” after normalization) was split into “com”, “omb”, “mba”, “bat”. So why is that important?
To answer that let’s assume we make a mistype in “combat” and type “comabt” instead. If we now want “combat” to be found how would we do that? The options are:
- We could go through our whole dictionary and compare each word with our keyword (“comabt”), then we would evaluate the difference between the 2 words. It’s called the Levenshtein distance. There are few ways to calculate it for a given pair of words, but the problem is that even if you can do that fast for 2 words it may take you a while to compare each word from your dictionary with the given word
- So it would be good to compare not all dictionary words, but only those that have higher chance to be a correction for the given word. And here comes the idea of trigrams — if we split all the dictionary words into trigrams and the search keywords too we can now operate those smaller tokens to find the candidates.
So in this case what’s done internally is that Manticore Search first splits “comabt” into infixes: “com”, “oma”, “mab” and “abt” and then finds the corresponding words in the dictionary as when the document was inserted it also did the same. Since the complexity of this algorithm is not very high (much lower than comparing each word with each other) Manticore quickly finds that there’s a word “combat” which also has “com” and it’s the only candidate word. So all it has to do after that is to make sure the candidate word doesn’t differ very much from the given word. It calculates the Levensthein distance, figures it’s not greater than the limit (4 by default) and returns the candidate:
MySQL [(none)]> call qsuggest('comabt', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 2 | 1 |
+---------+----------+------+
1 row in set (0.00 sec)
In other cases there may be more candidates. For example if you search for “combat” there is one word in the dictionary which exactly matches your query (the Levenshtein distance is 0), but there’s another which you might mean and CALL SUGGEST returns it too:
MySQL [(none)]> call qsuggest('combat', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 0 | 1 |
| kombat | 1 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
If you enter 2 words CALL QSUGGEST only process your last one:
MySQL [(none)]> call qsuggest('mortal combat', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 0 | 1 |
| kombat | 1 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
So how do I use this functionality in my application?” you may ask. It’s quite simple. Just:
- keep sending the search query to CALL QSUGGEST after each new character
- and show it’s output to the user
Here’s the log of what it would give in the case of our dataset, note the input (after “call qsuggest”) and the output (in column “suggest”):
MySQL [(none)]> call qsuggest('m', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mo', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mor', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mort', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| mortal | 2 | 1 |
+---------+----------+------+
1 row in set (0.01 sec)
MySQL [(none)]> call qsuggest('morta', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| mortal | 1 | 1 |
+---------+----------+------+
1 row in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| mortal | 0 | 1 |
+---------+----------+------+
1 row in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal c', 'testrt');
Empty set (0.01 sec)
MySQL [(none)]> call qsuggest('mortal co', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal com', 'testrt');
Empty set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal comb', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 2 | 1 |
| kombat | 3 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal comba', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 1 | 1 |
| kombat | 2 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
MySQL [(none)]> call qsuggest('mortal combat', 'testrt');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| combat | 0 | 1 |
| kombat | 1 | 1 |
+---------+----------+------+
2 rows in set (0.00 sec)
Conclusions
- Autocorrect is a very nice feature commonly used in many systems that helps users to find better results and site owners to not lose a user frustrated about no results due to a mistype or an incorrect query
- There are many ways how it can be implemented
- Google’s, Amazon’s, Pinterest’s, Etsy’s and other big sites’ implementations seem to be rather complicated and based on a non-trivial algorithms
- But in many cases something much simpler may also make sense
- Manticore Search can be used to provide neded functionality. By the way there’s an interactive course about it on their site

Top comments (2)
Thanks for sharing! Gave me some ideas myself, which I'm sure can be incorporated into a good search. Thanks.
You're welcome