Terminology
Table and its elements

Each DynamoDB table contains items, which are rows of data. Each item is composed of two parts. The first one is the primary key. It can contain only partition key, or be composite - containing both primary key and sort key. The second one is the attributes, which are columns that have a name and a value associated with it
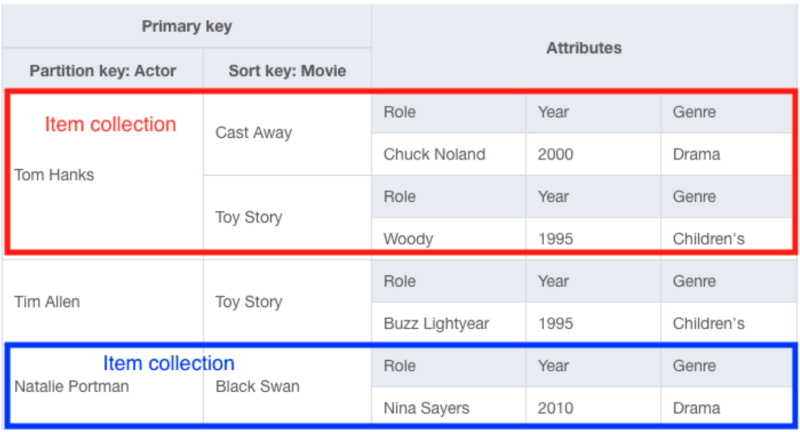
There is also a concept of item collection. An item collection is one or more items, which correspond to the same partition key.
Streams

You’ve probably already dealt with or at least heard about streams: a stream gets data from producers and passes it to consumers. In our case, the producer is DynamoDB and consumers are different AWS services. The prominent one is Lambda, with the help of which you can do some post-processing on your data or aggregate it.
Secondary indexes

What makes DynamoDB so much more than just a simple Key-Value store is the secondary indexes. They allow you to quickly query and lookup items based on not only the primary index attributes, but also attributes of your choice. Secondary Indexes, unlike primary keys, are not required, and they don't have to be unique. Generally speaking, they allow much more flexible query access patterns. In DynamoDB, there are two types of secondary indexes: global secondary indexes and local secondary indexes.
LSIs must be created at the same time the table is created and they must use the same partition key as the base table but they allow you to use a different sort key. They also limit you to 10 GBs of data per partition key and they share their throughput with base table - if you query for data using LSI, the usage will be calculated against capacity of the underlying table and its base index
GSIs can be created at any time after table creation and may use any attributes from the table as partition and sort keys, so two items can have the same partition and sort key pair on a GSI. Unlike LSIs, they don’t limit you in amount of data per partition key and they also don’t share their throughput. Each of the GSIs is billed independently, and, as a consequence, throttling is also separated. Their only downside is that they only offer eventual consistency, while LSIs offer both eventual and strong consistency.
Limits
https://dynobase.dev/dynamodb-limits/
Item size
DynamoDB's limit on the size of each item, which is row, is 400 KB. To avoid hitting it, you should store large objects (e.g images, videos, blobs etc) in S3 and just store a link to them in DynamoDB or, if the item is too large by itself, break it up into multiple items.
Indexes
DynamoDB Indexes allow you to create additional access patterns. GSIs (Global Secondary Index), aka indexes that use a different attribute as partition key, are limited to 20 per table. However, that limit can be increased by asking the support.
On the other hand, LSIs (Local Secondary Index) are hard-capped to 5 indexes. Usage of LSIs adds yet another, often overlooked limitation - it imposes a 10 GB size limit per partition key value.
For that reason, you should probably always favor GSIs over LSIs.
Scan and Query operations
These two operations have not only similar syntax - both of them can also return up to 1 MB of data per request. If the data you're looking for is not present in the first request's response, you'll have to paginate through the results - call the operation once again but with NextPageToken set to LastEvaluatedKey from the previous one.
Transactions and Batch Operations
Transactional and Batch APIs allow you to read or write multiple DynamoDB items across multiple tables at once.
For transactions:
TransactWriteItems is limited to 25 items per request
TransactReadItems is limited to 25 items per request
For batch operations:
BatchWriteItem is limited to 25 items per request
BatchGetItem is limited to 100 items per request
Partition Throughput
DynamoDB Tables are internally divided into partitions. Each partition has its own throughput limit, it is set to 3,000 RCUs (Read Capacity Units) and 1,000 WCUs (Write Capacity Units) per partition key.
Unfortunately, it is not always possible to distribute that load evenly. In cases like that, "hot" partitions (the ones that receive most of the requests), will use adaptive capacity for a limited period of time to continue operation without disruptions or throttling. This mechanism works automatically and is completely transparent to the application.
Others
Throughput Default Quotas per table - 40,000 RCUs and 40,000 WCUs
Partition Key Length - from 1 byte to 2KB
Sort Key Length - from 1 byte to 1KB
Table Name Length - from 3 characters to 255
Item's Attribute Names - from 1 character to 64KB long
Item's Attribute Depth - up to 32 levels deep
ConditionExpression, ProjectionExpression, UpdateExpression & FilterExpression length - up to 4KB
DescribeLimits API operation should be called no more than once a minute.
There's also a bunch of reserved keywords.
Best practices
https://dynobase.dev/dynamodb-best-practices/
Queries
- If you’re new to DynamoDB, you can use SQL-like query language, called PartiQL, to work with DynamoDB, instead of it’s native language
- Use BatchGetItem for querying multiple tables - you can get up to 100 items identified by primary key from multiple DynamoDB tables at once
- Use BatchWriteItem for batch writes - you can write up to 16MB of data or do up to 25 writes to multiple tables with a single API call. This will reduce overhead related to establishing HTTP connection.
- If you need consistent reads/writes on multiple records - use TransactReadItems or TransactWriteItems
- Use Parallel Scan to scan through big datasets
- Use AttributesToGet to make API responses faster - this will return less data from DynamoDB table and potentially reduce overhead on data transport
- Use FilterExpressions to refine and narrow your Query and Scan results on non-indexed fields.
- Because DynamoDB has over 500 reserved keywords, use ExpressionAttributeNames always to prevent from ValidationException
- If you need to insert data with a condition, use ConditionExpressions instead of Getting an item, checking its properties and then calling a Put operation. This way takes two calls, is more complicated and is not atomic.
- Use DynamoDB Streams for data post-processing with Lambda Instead of running expensive queries periodically for e.g. analytics purposes, use DynamoDB Streams connected to a Lambda function. It will update the result of an aggregation just-in-time whenever data changes.
- To avoid hot partitions and spread the load more evenly across them, make sure your partition keys have high cardinality. You can achieve that by adding a random number to the end of the partition key values.
- If you need to perform whole-table operations like SELECT COUNT WHERE, export your table to S3 first and then use Athena or any other suitable tool to do so.
Monitoring and Security
- Use IAM policies for security and enforcing best practices this way you can restrict people from doing expensive Scan operations
- Use Contributor Insights to identify most accessed items and most throttled keys which might cause you performance problems.
- Use On-Demand capacity mode to identify your traffic patterns. Once discovered, switch to provisioned mode with auto scaling enabled to save money.
- Remember to enable PITR (point-in-time-recovery), so there’s an option to rollback your table in case of an error
- Add createdAt and updatedAt attributes to each item. - - - Moreover, instead of removing records from the table, simply add deletedAt attribute. It will not only make your delete operations reversible but also enable some auditing.
Storage and Data Modelling
- Store large objects (e.g images, videos, blobs etc) in other places, like S3, and store only links to them inside the Dynamo
- You can also split them into multiple rows sharing the same partition key. A useful mental model is to think of the partition key as a directory/folder and sort key as a file name. Once you're in the correct folder, getting data from any file within that folder is pretty straightforward.
- Use common compression algorithms like GZIP before saving large items to DynamoDB.
- Add a column with epoch date format (in seconds) to enable support for DynamoDB TTL feature, which you can use to filter the data or to automatically update or remove it
- If latency to the end-user is crucial for your application, use DynamoDB Global Tables, which automatically replicate data across multiple regions. This way, your data is closer to the end-user. For the compute part, use Lambda@Edge functions.
- Instead of using Scans to fetch data that isn't easy to get using Queries, use GSIs to index the data on required fields. This allows you to fetch data using fast Queries based on the attribute values of the item.
- Use generic GSI and LSI names so you can avoid doing migrations as they change.
- Leverage sort keys flexibility - you can define hierarchical relationships in your data. This way, you can query it at any level of the hierarchy and achieve multiple access patterns with just one field.
Examples
Composite primary key

This primary key design makes it easy to solve four access patterns:
- Retrieve an Organization. Use the GetItem API call and theOrganization’s name to make a request for the item with a PK of ORG# and an SK of METADATA#.
- Retrieve an Organization and all Users within the Organization.Use the Query API action with a key condition expression of PK = ORG#. This would retrieve the Organization and allUsers within it, as they all have the same partition key.
- Retrieve only the Users within an Organization. Use the QueryAPI action with a key condition expression of PK = ORG# AND begins_with(SK, "USER#"). The use of thebegins_with() function allows us to retrieve only the Userswithout fetching the Organization object as well.
- Retrieve a specific User. If you know both the Organizationname and the User’s username, you can use the GetItem API call with a PK of ORG# and an SK of USER# to fetch the User item.
Sources
“The DynamoDB Book” by Alex DeBrie: https://www.dynamodbbook.com/
Dynobase - Professional GUI Client for DynamoDB: https://dynobase.dev/

Top comments (0)