
Please note no information exposed here can be used to harm Twitch and we have provided them with a detailed report outlining the vulnerabilities discovered.

Watch video presentation of this text
Earlier this year Twitch became the latest in a growing list of companies whose source code was unintentionally made public. In this particular case, all source code belonging to Twitch was exposed to the forum 4chan which totalled 6,000 internal Git repositories, 3,000,000 documents with a combined unzipped size of 200GB.
Included in this leak was source code from various Twitch products, secret projects, subsidiaries, internal tools, and employees repositories. As well, there was exposed information from databases including the streamers' earnings.
We spent some time scouring the 6000 Git repositories for secrets and sensitive data and while most of the attention has been on the leaked streamers' revenues, our results show a much more serious problem that extends far beyond just this single breach.
Exploring the Twitch codebase
We found nearly 6,600 secrets inside the Twitch Git repositories. This includes 194 AWS keys, 69 Twilio keys, 68 Google API keys, hundreds of database connection strings, 14 GitHub OAuth keys, and even 4 Stripe keys to name only a few.
Perhaps what is the most troubling aspect of this breach, is that this amount of sensitive data we found isn't actually surprising. Considering the size of the leaked data, the magnitude of secrets we found is reasonable when benchmarked next to what we see in our new customers. We also saw a lot of evidence of security tools usage, indicating some maturity with AppSec showing how baked in the problem of leaked secrets in source code is for all organizations, big and small.
There have been many examples of private code being accessed by an attacker, what makes the Twitch breach unique however is that the malicious actors published source code publicly. This gave us an opportunity to put on our black hats and explore this breach from the perspective of a malicious actor. Doing so we could explore the security vulnerabilities of a real production codebase, starting with sensitive information like secrets.
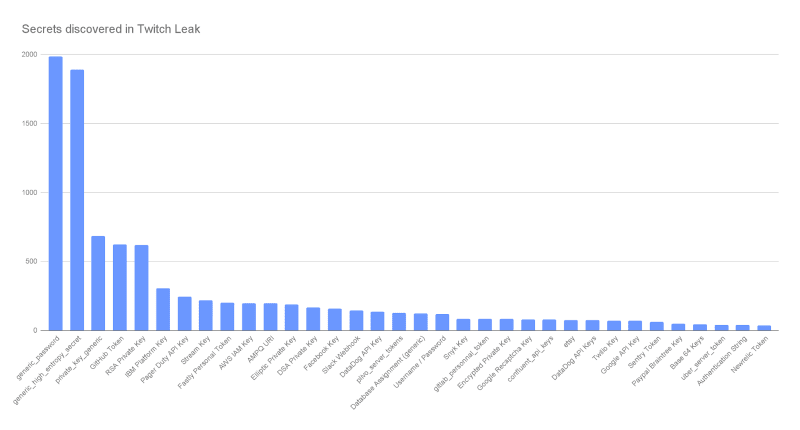
First some disclaimers. Usually, GitGuardian would validate keys found in a repository to remove false positives. Because of the ongoing investigations that will undoubtedly be going on, GitGuardian decided not to validate any keys as not to mislead the forensics teams. This means we cannot give a percentage of the keys which were valid at the time of the leak.
Gaining initial access to the code
Even today we have not learned a lot about exactly how attackers were able to gather the information and their motives behind it. The only information from Twitch on this matter was below:
"The incident was a result of a server configuration change that allowed improper access by an unauthorized third party."
This doesn't give us too much information other than it is likely they accidentally made their servers accessible to unauthorized users. This could have been a backup server, a Git server, what we know is that the attackers were able to access Git repositories and also some databases.
We know from other examples of breaches there are many ways a bad actor can gain access to private code. In the case of Uber in 2016, attackers were able to gain access via poor password hygiene, in the case of the Indian Government breach attackers found misconfigured Git repositories by fuzzing domains, in the CodeCov breach attackers exploited a Docker image to gain access to code repositories. Point is, Git repositories are becoming high-value targets and it only takes a small crack in the security chain for an attacker to be able to find their way in.
The security implications
When we look at Twitch the main narrative in the media is that this doesn't present a security risk and that no significant customer data was leaked. Our findings directly challenge this, and while no customer information may have been compromised directly in the breach (other than the streamers' income), the vast amount of secrets we uncovered shows that there most definitely are big security concerns associated with this leak.
Out of the nearly 6,000 repositories, more than 1,100 had at least one occurrence of a secret candidate inside them (including their history). What we will look at now, is what an attacker would do if they had access to this information. Remember that in this case the attacker decided to publish the code to 4chan, but imagine a scenario where the attacker did not publish this information and Twitch was unaware of the breach giving an attacker ample time to find and exploit the sensitive information they found.
Simulating an attack
We decided to try and look at this the same way a malicious actor might and try to simulate the steps they would take. In this example, there is so much data to sort through that even though there are thousands of keys, it can be difficult to quickly identify the ones that are most interesting. In our case, we took an approach of:
- Identifying and classifying different secrets into categories
- Link high-value keys with high-value repositories
Identifying high-value and secondary secrets
The first step as an attacker would be to scan the entire code base for secrets. This can be very difficult depending on the tooling you have access to. Some keys like AWS keys follow specific patterns but most are simply high entropy strings which are much more difficult to find and will produce more false positives. Luckily for us we have the advantage of being able to leverage GitGuardian's powerful detection engine to accurately find these secrets.
Once we have uncovered them, we need to break them into three different categories.
| Infrastructure & keys | Data keys | Secondary attack keys |
|---|---|---|
| example | example | example |
| Cloud service keys | Database Credential | * reCaptcha |
| Payment system keys | S3 bucket keys | * Messaging systems (Slack, Twilio) |
| Encryption keys |
Depending on your goal as an attacker you may focus on a specific category. If you are wanting to disrupt services, direct traffic, or use computing power for your own evil plan you can focus on the infrastructure keys. If your goal is to steal, encrypt or abuse data then you can focus on accessing the databases. If however, you want to infiltrate the organization further than the keys allow or conduct account takeovers, you can choose to focus on what we are calling secondary attack keys. These are keys that will let you launch targeted spear-phishing campaigns using tools like Twilio to send messages to users, bypass security features like reCaptcha or use the internal messaging system to try and elevate privileges.
In the example of Twitch we have no shortage of keys to uncover to fit whatever evil plan you may have. Once we have found and categorized the keys, however, we want to try and filter out the false positives. One simple way to do this is to validate the keys using a script that calls the backend. In our case, we opted not to do this so we don't disrupt the forensics that may be ongoing.
Therefore we used different methods to sort our findings:
- Search for keywords indicating a testing purpose, such as 'Test'
- Search for commits that are closest to the leak date.
Using PayPal Braintree keys (a payment service) as an example, we can quickly sort out the keys used in production and the keys used in SANDBOX environments.
Braintree SANDBOX key found in Twitch Data

Braintree Production Key found in Twitch Data
In the example below we can see an AWS key in a config.py file that was committed the same day as the breach occurred, making them high-value candidates for being true secrets.

Because a breach like this has such a large amount of sensitive information, each type comes with a different attack path an attacker might want to take.
Here are some examples: .
Database assignment credentials that could be used to access potentially sensitive information.

Cloudflare keys to disable protections on attacks like DDOS attacks. 
Here we can see some reCaptcha keys that would allow an attacker to bypass protections in a DDOS or bruteForce campaign.
And of course a whole heap of credentials that appear to give access to numerous internal systems and tools. Another approach to finding high-value secrets is simply to look for the names of the repositories:

In this example, we can see 14 AWS keys in the repo with the name Backend/CloudServices, which most probably indicates a high-value repository. BINGO! This gives us a great indication of where we should focus our attention and which services we can attack first. All that is left for us, as the attackers, to do now is launch our evil plans starting with the most likely secrets to yield an immediate result and then working down to longer, more complicated attack paths using secondary attack keys.
The larger problem
Now it may appear here as if the core of this problem was because the source code of Twitch was leaked, but actually, this is not true. Source code getting into the wrong hands is a frequent event, this is because source code is a leaky asset, it transits through many servers, workstations and networks making a compromise not an unlikely event. Perhaps much worse than your code being made public is an attacker gaining access and not keeping quiet, working silently to exploit the secrets inside. In fact, the person or people that leaked this code likely did Twitch a favor as there were probably actors with more malicious intent who also discovered the misconfigured server.
The true security problem is not our source code being leaked, it's that our source code in and of itself is a vulnerability yet we do not acknowledge this until a security event forces us to. After diving deep into the Twitch source code, I can state again that Twitch wasn't an organization that didn't take security seriously or didn't show signs of maturity from an application security perspective. The problem is not on an organizational level, it is on an industry level. We must all assume our source code will be leaked and implement security measures to make sure our source code isn't a vulnerability.
Preventing secret sprawl
Secret sprawl is the unwanted distribution of secrets which is evident in the Twitch example. The simple truth is that it is extremely difficult to prevent secret sprawl entirely because it falls down to human error and the fact the secrets are actually very difficult to detect with high precision and recall (see an entire blog article about this). This does not mean however we cannot identify and take action before a breach happens.
Preventing secret sprawl needs to focus on three areas.
- Tools to empower developers to prevent them from committing secrets in the first place;
- Tools to detect secrets in real-time when they do leak (because they will);
- And then tools that monitor places outside of your organization's control, such as on employees' public Git repositories.
GitGuardian has been taking on this challenge since 2017 and enables everyone within the software development lifecycle to take part in the solution to secret sprawl. GitGuardian Shield is an open-source developer tool taking a shift left strategy to allow the developers themselves to prevent secrets from leaking. Our application security platform for internal repository monitoring allows security and project leaders to make sure repositories are clean from secrets so if source code does leak it doesn't create a new security issue and lastly our public monitoring solution allows organizations to get visibility into how secrets are leaking outside of their scope of control.
Contact GitGuardian to find out how we can help your organization today.





Top comments (0)