TL;DR: Don’t be lured by the false promise of 0 false positives. If a secret detection tool does not report any false positives, chances are high it is silently skipping real secrets.
Introduction
In an ideal world, secret detection tools would spot all leaked secrets and never report false positives.
Unfortunately -or maybe fortunately...- we do not live in an ideal world: secret detection tools are not perfect, sometimes they report false positives. But would it really be better if they did not?
Definitions, what are false positives and false negatives?
A false positive happens when a system reports a condition as valid when it is not. The opposite, the false negative, happens when the condition is reported as invalid when it should have been reported as valid.
In the case of secret detection, the condition is identifying whether a character sequence, or a set of character sequences, is a secret.
We can summarize this in a table:
| Sequence identified as not a secret (negative) | Sequence identified as a secret (positive) | |
|---|---|---|
| Sequence is not a secret | True negative | False positive |
| Sequence is a secret | False negative | True positive |
(You can learn more about these terms and others in our article explaining the concepts of accuracy, precision and recall)
With these definitions in mind, it makes sense for secret detection tools to try to maximize the number of true negatives and true positives, and minimize the false ones. But secret detection is based on a lot of heuristics, so the answer is often not truly black or white. What should a secret detection tool do when the answer is not clear-cut?
Which one is worse, too many false positives or too many false negatives?
Let’s take this to the extreme.
If a tool reports too many false positives, it leads to alert fatigue: users are flooded with alerts. They start to ignore them and some reported true positive secrets are not taken care of.
If, on the other hand, the tool is very aggressive against false positives, users won’t be flooded with reports and can take care of the reported ones. But since the tool heuristics cannot be perfect, the tool is going to identify real secrets as false negatives and silently sweep them under the rug.
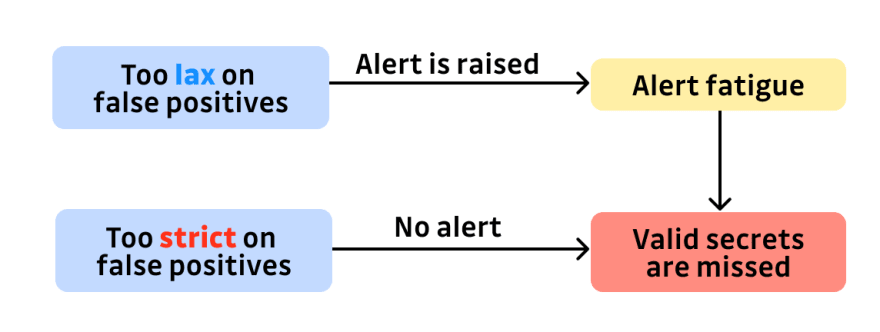
In both cases, valid secrets have the risk of being missed, but at least if the tool prefers to identify a secret as valid when unsure, the user can be aware of it: the secret won’t be silently discarded.
This can be counter-intuitive when one starts evaluating secret detection tools: when comparing tool A and B, if A only reports valid secrets and B reports valid and invalid secrets, then one might be tempted to decide A is the better product. That is until you dive deeper and notice that some valid secrets reported by B have been silently ignored by A.
This is similar to the mail spam situation: if a spam filter is too aggressive, your inbox will be kept clean and tidy, but you will have to regularly go hunt for valid emails from the spam folder.
False positive, according to whom?
Sometimes the tools do not have access to the whole context. A sequence could be identified as a secret by a detection tool because it matches all the characteristics of secrets used for a given service. Yet you know it is not a true secret in the context of your infrastructure, for example because it is used in example code. For the tool it is a valid secret, for you it is a false positive.
Continuing with the spam filter analogy, you are the ultimate judge of whether an email is spam or not.
"Due to the nature of the software we write, sometimes we get false positives. When that happens, our developers can fill out a form and say, "Hey, this is a false positive. This is part of a test case. You can ignore this."
Beware of overfitting
According to Wikipedia, overfitting is “the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit additional data or predict future observations reliably”.
When developing a secret detection tool, eliminating all false positives reported when testing the tool against known datasets would lead to overfitting. The tool would have perfect theoretical scores, but would perform poorly on real-world data.
To avoid falling into this trap, we use both fixed datasets and real-time data. Fixed datasets are good when one needs determinism, for example to spot regressions. Real-time data prevents overfitting by exercising our tools against varying content. We also regularly refresh our fixed datasets, to ensure they remain relevant.
How can we avoid alert fatigue?
“GitGuardian gives us a little more information about that secret because it can tie together the historical context and tell you where the secret has been used in the past. You can say, "Oh, this might be related to some proof-of-concept work. This could be a low-risk secret because I know it was using some POC work and may not be production secrets."
It’s safer to have some false positives than no false positives at all, but if we don’t address alert fatigue, users won’t be in a much better situation. What features do GitGuardian tools provide to help with that issue?
First, both our internal and public monitoring products let you define repositories to exclude. This lets you quickly eliminate a bunch of irrelevant secrets.
Second, following our shift-left strategy, we provide GitGuardian Shield, a client-side tool to prevent committing secrets. GitGuardian Shield helps reduce the number of false positives reported to your security team by making your developers aware of them: if they try to commit a secret, ggshield will prevent them from doing so, unless they flag it as a secret to ignore using a ggignore comment (in which case it is identified as a false positive). When a secret is flagged as ignored, it won’t generate an alert when it is pushed to your repository.
Once a leaked secret has been reported, we provide tools to help your security team quickly dispatch them. For example the auto-healing playbook automatically sends a mail to the developer who committed the secret. Depending on how you configured the playbook, developers can be allowed to resolve or ignore the incident themselves, lightening the amount of work left to the security team.
Conclusion
"Accurate secrets detection is notoriously challenging. The solution offers reliable, actionable secrets detection with a low false-positive rate. That low false-positive rate was one of the reasons we picked it. There are always going to be some, but in reality, it's very low compared to a lot of the other, open source tools that are available."
Don’t be lured by the false promise of 0 false positives. If a secret detection tool does not report any false positives, chances are high it is silently skipping real secrets.
We continuously improve our tools and refine our algorithms to report as few false positives as possible, but like an asymptote, 0 false positives can never be reached. Erring on the side of caution and letting some false positives in is safer. This leaves the user in control, but beware of alert fatigue. Secret detection tools must provide easy ways for users to flag false positives as such.





Top comments (0)