

Software projects that include an AI model have major challenges in addition to those addressed in the traditional software development life cycle (SDLC). A successful AI-SDLC project must resolve numerous AI-specific issues, such as poor-quality data and AI model selection. Furthermore, generative AI systems receive input and produce output as if the user is interacting with another human rather than a computer. This introduces more uncertainty into AI-human interactions that must be considered during design.
Consequently, this post defines six flexible AI-SDLC phases that can be modified and sized as needed. There are commonalities across all AI projects, especially when they are in an environment already using SDLC best practices.
The SDLC phases aim to enable teams to increase their ability to successfully design and implement any type of AI. This includes using the intelligent capabilities of an AI tool, such as Pieces Copilot+, to assist the developers working on an AI-SDLC project. As projects become more complex, it becomes more important to support developers with AI tools that expand their knowledge and increase their abilities.
Five-Finger Project Management
The AI-SDLC methods for managing software development projects have multiple phases, and there are two mutually exclusive ways to define the lengths of the phases. The following figure identifies the SDLC phases by assigning each phase to a finger of a hand. Each hand shows one of the two ways to calculate the lengths of a project’s SDLC stages.

Reading the software development life cycle phases from left to right, the phases are (1) Describe, (2) Discover, (3) Define, (4) DO, and (5) Deploy. There is a sixth phase, Monitor & Maintain, that links Deploy back to Describe. This Monitor & Maintain phase may be within the current project or it may start a new project, such as a major upgrade.
The DO phase of an AI-SDLC is a four-step iterative cycle that includes (a) Prepare Data, (b) Train AI Model, (c) Customize AI Model, and (d) Test AI Model. These steps and the major phases are discussed in more detail in the following sections of this post.
In the PROCESS View of any SDLC methodology, the schedule is calculated forward from the start date. The expected length of time for each phase is added to the total time, and the total time determines the planned delivery date. In this approach, many experienced developers use a multiplication factor that increases the projected time for each phase to a more realistic number.
In contrast, the DEADLINE View of a program development cycle calculates the length of each phase by calculating backward from a firm deadline for delivery. Unfortunately, this approach is often used for projects, and it can require a “work-until-you-drop” expectation for developers.
The optional sixth phase, Monitor & Maintain, uses information from the deployed system to Describe a problem that needs to be solved. In the PROCESS View, it starts a new Phase 1 that is within the original project definition or is the start of a new project. The new information may require adding a new feature or new knowledge, be a major or minor bug fix, or be anything else that requires changing the code of the deployed system.
The Monitor & Maintain phase often is not considered in projects defined with the DEADLINE view. Although that may be successful in a traditional SDLC project, it can cause major problems in an AI-SDLC project. For example, the AI model can increasingly produce wrong answers as its knowledge base becomes more outdated.
Because of the increased risk in deploying AI systems, a large project may iterate through several smaller projects. For example, the first smaller project might have deployed a proof-of-concept benefits-tracking system to one or two users in the HR department for feedback. The second smaller project deployed an improved pilot to all users in the HR department, and the third smaller project deployed the full system to all company employees.
Even in small and informal AI-SDLC projects, it is important to clearly distinguish and understand the six major SDLC phases and the four steps of the DO cycle. Skipping or skimping on any part of the programming cycle can greatly increase the dangers of major problems in and after deployment.
Visualizing and Describing the AI-SDLC
An AI-SDLC is a standard software development life cycle that has been customized to include an AI model that generates output. The output of the AI model may or may not be presented directly to users of the system. In either case, the AI's decisions affect what is presented to users.
The following figure illustrates the AI-SDLC and the focus for each major phase as well as the four DO steps.
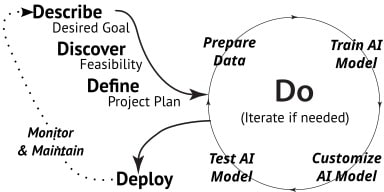
These are the phases for any project, whether it is a group of friends deciding upon a trip destination or the most complex software development projects that include several AI systems. The uniqueness of an AI-SDLC is the focus on data and the AI model in the DO phase.
1. Describe
The first step in the SDLC is describing the desired goal(s), even if the project is only going to see a movie with friends. If you do not identify what you (and others involved) want from the project, time and money will be wasted on doing things that do not need to be done.
In the traditional phases of SDLC, the result of the Describe phase can be a single sentence, a paragraph of explanation, a detailed budget justification, or whatever else is appropriate for the project. The key information is the goal description or Statement of Purpose describing the desired result(s) from the project.
In an AI project, the goal is one or more "use cases," which are specific challenges an AI may solve or opportunities an AI may help capture. For the first AI project, start small with one limited and well-defined use case. As the organization grows, additional use cases can be implemented.
Make the first use case an example for future AI use cases. It is the beginning of a library of use cases that is regularly updated. There are frequent incremental additions of new use cases rather than infrequent additions of large, complex use cases. The goal is to add business value by identifying and selecting use cases with the best ROI or learning value.
Problems to be solved by an AI project should be directly related to high-level strategic or operational priorities and measurable by KPIs, primarily those that are not achieving their target values. Data should be accessible and not yet explored by an AI model. Furthermore, an AI project needs executive sponsorship (a “champion”) to be successful, and the project must align (be consistent) with the organization's mission, data, and traditional IT.
It is also crucial to note whether the AI must allow users to understand how the AI model arrives at its decisions. This can be crucial for user trust and acceptance, and it might be a regulatory requirement for high-risk use cases in domains such as medicine and finance.
2. Discover
The second of the SDLC phases, Discover, is when questions about feasibility are answered. Failure to carefully identify and answer the appropriate questions about feasibility puts the project at high risk of failure. Decisions about feasibility should be based on research rather than personal opinions.
The problem being solved by introducing an AI model should be a recognized need, rather than a solution looking for a problem to solve. This requires user interviews to determine how the AI will be applied, and market research to determine whether the appropriate AI model is available to buy, available for free, or would need to be built.
It is assumed that Phase 1, Describe, clearly defines the specific problem or challenge the AI system will solve. The feasibility questions need to focus on issues such as success metrics, data characteristics, technical resources, ethical considerations, regulatory compliance, risks, scope and budget constraints, and project ROI.
3. Define
An AI-SDLC project plan includes the same phases as a standard SDLC experience, but it has additional considerations specific to the development and integration of an AI model. The following figure overviews the output of each phase in the traditional SDLC and the AI-SDLC. Although it is shown as a linear “waterfall” process, in reality, the programming phases are a well-planned iterative process.

Model selection can be difficult, especially if you do not know how the models differ. For example, for certain applications, it might be crucial to understand the model's reasoning behind its predictions. These projects would need to consider including techniques such as LIME (Local Interpretable Model-Agnostic Explanations) in SDLC practices to help explain the AI model's decision-making process.
Based on the problem you are trying to solve and the characteristics of your data, different AI models are appropriate. Common choices include deep learning models for image or text recognition, decision trees for classification tasks, or reinforcement learning models for decision-making in dynamic environments.
In summary, while the core SDLC phases remain relevant, an AI-SDLC project plan places a stronger emphasis on data, on AI model training and evaluation, and on monitoring and maintenance to ensure the AI model functions effectively and ethically in the real world.
4. DO
4a. Prepare Data
The data used to train and fine-tune the AI model is crucial because the answers and decisions it affects are why the project exists. The AI model will \"hallucinate\" and provide wrong information to users when there is no data available to correctly respond to the user's prompt.
For example, the SARAH (Smart AI Resource Assistant for Health) system recently deployed by the World Health Organization (WHO) fabricated a list of fake names and addresses of clinics that supposedly existed in San Francisco. There are numerous other instances where AI hallucinations have caused major problems for companies and consumers.
There are several key things to consider regarding data for an AI project, and security should always be considered.
Data Acquisition
- Identify the data needs
- Identify data sources
- Collect the data
Data Preprocessing
- Check data quality (i.e., check for biases)
- Clean the data and label if needed
- Transform data as appropriate for the model
- Split data into training, validation, and test datasets
Other Considerations
- Start small and expand
- Use synthetic (AI-generated) data to improve the model
- Use a pretrained model and only fine-tune it
By carefully managing your data throughout the AI-SDLC phases, you can ensure your AI model has the foundation it needs to learn effectively and deliver the results you want.
4b. Train the AI Model
If you plan to use a pre-trained model (available from various sources), you can skip this step! Training complex AI models can require significant computing power (CPUs, GPUs). Ensure you have the necessary infrastructure in place to efficiently train the AI model.
If the AI model is being built rather than bought, there are considerations far above the level of discussion in this exploration of the SDLC life cycle phases. For example, it will be necessary to define the model architecture (e.g., number of layers, neurons per layer) and set hyperparameters (e.g., learning rate, optimizer) that influence the model's learning process. This initial configuration can be adjusted later during fine-tuning.
Significant expertise is also required if the model is selected from what is currently available. For example, Google's '"Model Garden" offers more than 150 models organized into three categories that differ in task specificity. An expert can deploy a model directly from Model Garden through Hugging Face to the desired endpoint for users to access the model.
If the model is to be trained, the training data is fed into the AI model iteratively. During each iteration, the model makes predictions based on the current configuration, calculates the errors between predictions and actual values, and adjusts its internal parameters to minimize those errors. It is necessary to track the model's training progress by monitoring metrics like loss (error) and accuracy on the validation set. This helps identify potential issues like overfitting or underfitting.
4c. Customize the AI Model
Customizing an AI model is sometimes called LLM fine-tuning. The validation data defined in Step 4b of SDLC models is used to modify the variables (hyperparameters) that control the model's learning. The goal is to improve the AI model’s performance. This may involve techniques like grid search or random search to find the optimal configuration.
Sometimes the AI model memorizes the training data too well (overfitting) and consequently performs poorly on unseen data. For example, overfitting can lead to wrong answers (hallucinations) when the model responds to a new problem by providing the answer to a well-trained problem that is slightly different.
Underfitting happens when the model fails to learn the underlying patterns in the data. Techniques like regularization or dropout can help address these issues.
4d. Test the AI Model
Test the AI model thoroughly before deploying it, even if the system is only a proof of concept. Evaluate the model's final performance on the unseen test data using relevant metrics aligned with your project goals. For instance, accuracy might be the primary metric for a classification task, while precision and recall are more important for imbalanced datasets.
Analyze the model's errors on the test data to identify areas for improvement. This can help refine the data preprocessing steps, explore alternative model architectures, or collect more data if necessary.
5. Deploy
Deployment issues and other AI DevOps challenges should have been defined and considered during the Discover and Define phases. The infrastructure requirements for deploying your AI model in production involve numerous critical factors.
For example, does the deployment environment have sufficient computing power (CPUs, GPUs) to handle the model's inference needs? Running complex AI models efficiently might require specialized hardware. AI models also can significantly increase the amount of electricity used.
Secondly, ensure adequate storage capacity for the model and its associated data. Consider the scalability of your infrastructure to handle potential increases in user traffic or data volume.
Make sure your ML DevOps chooses a suitable serving framework to manage the model in production. These frameworks handle tasks like model loading, versioning, and managing requests from the application. Popular options include TensorFlow Serving, TorchServe, or Triton Inference Server.
By carefully considering these and other factors, you can plan your deployment process thoroughly. This is necessary to ensure a smooth and successful deployment of your AI-powered software system within the AI-SDLC phases. Remember, deployment is not a one-time event for an AI system—ongoing monitoring, maintenance, and potential retraining are crucial for maintaining a reliable and effective AI solution.
6. Monitor & Maintain
Systems that include an AI model are not deployed and then forgotten by their developers. In addition to the updates required because of traditional maintenance issues, the AI model requires additional monitoring and maintenance. These include performance monitoring, retraining and updates, AI version control and rollbacks, and a disaster recovery plan.
Pieces Copilot+ for AI-SDLC
AI systems have become increasingly important in their contributions to every phase of the traditional SDLC phases and the AI-SDLC. The intelligence of AI in DevOps can be used to increase the teams’ productivity, and that enables developers to more quickly create better software.
For example, real-world testing with synthetic (AI-generated) data provides information about flow, timing, and error conditions in a simulated production environment. This enables previewing new features or UI layouts to get faster and more detailed feedback before implementing it in code meant for production. In a recent webinar demo, the Mockaroo online AI was used to create free synthetic data that simulated real data.
The Pieces Copilot+ AI acts as an assistant programmer whose sole task is improving the user's productivity. For example, Pieces can do routine tasks, such as translating code into different languages, documenting for various types of readers, and generating the code for entire functions in response to well-defined prompts. This can increase code consistency and conformance to standards, as well as streamline the stages in program development.
It also finds and suggests how to repair code that is inefficient or contains bugs. Consequently, the code that goes to testing is cleaner and more efficient. Pieces can generate more diverse and complete test cases to do broader and deeper tests of the new system. It can generate edge cases and unexpected events that yield more robust software to be deployed.
Pieces also benefits projects by making collaboration happen more quickly and easily. For example, the Pieces Copilot can be asked to provide action items based on chats in Slack or Teams, by analyzing your active workflow with Live Context.
It can identify the source if the user pulled the snippet from a website or extracted it via OCR from a screenshot of a YouTube channel. The new context engine in Pieces Copilot+ can be asked many types of questions that are not possible in other AI copilots. An explanation and some example prompts/questions are available in this blog post. This other post has 20 novel AI prompts that take advantage of Pieces Copilot+ live temporal context that ordinary copilots cannot handle.
In its newest release, Pieces maintains its own workstream as a real-time context pulled from the user's entire workflow. Thus, it can summarize the user's online research, resolve complex coding issues that require outside resources in a different project, and streamline all aspects of the workflow.
Pieces learns from the user's habits and preferences to provide personalized recommendations and shortcuts within integrated development environments (IDEs), browsers, and communication tools such as Teams and Slack. These features provide a strong advantage for teams working within AI Software Development Life Cycle best practices.
The AI-related challenges and issues increase the chaos that must be controlled and organized. For example, there are additional stakeholders, such as Data Scientists and Machine-Learning specialists, that provide or need AI-related snippets. The live context of Pieces Copilot+ powered by the Workstream Pattern Engine can make the entire team’s workload easier by organizing and proactively providing the information as needed.
Conclusion
In summary, the AI-SDLC is the traditional SDLC plus the issues and challenges introduced by the inclusion of an AI model. The focus on producing business value remains the same. Each project will customize the details within the AI-SDLC phases to fit into its enterprise environment and achieve its goals.
MLOps is the combined focus of Data Scientists, Machine Learning (ML) specialists, and DevOps specialists on deploying and maintaining an ML algorithm in a production environment. The goal is to build efficient and effective models that satisfy business and regulatory requirements while increasing automation and business value. As discussed in this post, Machine Learning DevOps converts the traditional SDLC into the AI-SDLC.
Using AI copilots such as Pieces Copilot+ results in numerous benefits. These include faster design and implementation, cleaner and more efficient code, and more thorough testing scenarios. It can also be used to predict potential problems and identify where code needs to be improved before it causes major or minor failures.

Top comments (0)