
Quando o time de engenharia trabalha em um mesmo ambiente, seja em uma única sala ou em diversas, a comunicação é facilitada. Foi feito deploy de determinada feature? Como está a investigação daquela intermitência? Como ficou aquele bug de produção? Foi corrigido?
Pelo fato do gestor estar fisicamente próximo, sempre há alguém para quem possa recorrer em caso de dúvida. Não é à toa que o número de interrupções dos engenheiros e desenvolvedores é muito menor quando estão trabalhando remoto.
Isso se dá pelo aumento das barreiras de comunicação. Não tendo pessoas próximas para as abordar, tende-se a buscar pela informações de uma outra maneira: visitando o board de user stories, procurando por emails de post-mortem ou histórico de algum chat corporativo.
Entretanto, nem toda empresa possui uma cultura de documentação apropriada para o trabalho remoto. Isso injeta uma dose de medo nos gerentes de engenharia que, ao perderem o contato físico com seus times, sentem que perderam o controle e que nada mais funcionará.
Na prática, sabemos que não é bem verdade. O fluxo de entregas tende a continuar funcionando, mas, para que isso aconteça, mudanças serão necessárias. Toda a comunicação antes feita cara a cara, precisa, agora, acontecer de forma remota. Em alguns casos, uma vídeo chamada resolverá; em outras, uma thread de emails ou em outra ferramenta para discussões será necessária.
Cada empresa precisa estabelecer quais as melhores formas de manter o time alinhado e colaborativo. Assim, utilizando diversas ferramentas para que o trabalho continue sendo feito da melhor maneira possível.
E deste cenário, algumas pergunta surgem: e os gerentes de engenharia, como podem acompanhar o processo de desenvolvimento? Como sabem quem precisa de ajuda? Como garantir que as demandas continuam sendo entregues com qualidade?
Quem pode ajudar a responder estas perguntas é o SourceLevel. Nosso produto foi desenvolvido para ajudar do desenvolvedor ao CTO a enxergarem o processo de desenvolvimento. Através da visibilidade e de números objetivos, o time pode então tomar as melhores decisões sem achismos.
O que medir? Pessoas ou o fluxo de desenvolvimento?
Existem diversos motivos para que gestores prefiram medir o fluxo de desenvolvimento. A principal razão é que medir o desempenho individual não contribui, ao contrário, atrapalha, a colaboração.
Se desenvolvedores forem cobrados por linhas de código, número de commits ou pull requests fechados, então a qualidade do código e o quanto, de fato, a pessoa desenvolvedora entrega de valor para o usuário final ficam de fora. Também não estão sendo consideradas a contribuição desta pessoa durante um pair programming, na revisão de pull requests, nas decisões de arquitetura e em outras etapas do processo de desenvolvimento.
Portanto, é interessante olhar para o fluxo como um todo, considerando sempre o trabalho de time. Assim, os gerentes de engenharia serão capazes de ter a visão do todo, da quantidade, do ritmo e a quantidade das entregas.
A visão individual não é inútil, pode ser utilizada para embasar uma reunião de 1:1 ou de performance review, dado que é papel do gerente de engenharia trabalhar o desenvolvimento destas pessoas desenvolvedores; mas é ineficiente na gestão da área como um todo.
Por isso, o SourceLevel foca atualmente na percepção do time, mas pretende, expandir para visões individuais, com métricas de produtividade, colaboração e contribuições para o time.
Se você tem interesse nestas métricas e tornar suas reuniões de 1:1 e de performance mais objetivas, fale conosco! Notificaremos os interessados assim que estiverem disponíveis!
Qualidade de Código
Qualidade é um dos atributos mais difíceis de se medir. Muitas vezes, os gestores ficam refém da opinião dos desenvolvedores, que, por trabalharem diariamente com o código, possuem uma visão subjetiva da qualidade.
Porém, para se traçar uma estratégia de manutenção e melhoria contínua, é necessário uma visão quantitativa. Só assim será possível descobrir o estado em que a aplicação se encontra e acompanhar seu progresso.
Para ajudar o time quanto a este quesito, o SourceLevel possui mais de 30 engines que rodam a cada mudança no código, podendo ser ligada ou desligada para que rodem a cada envio de commits de cada pull request. Chamamos isto de Automated Code Review.
Análise da qualidade de repositórios
Através de configurações via arquivo .yml, diversos linters podem ser ativados ou desativados. No caso do arquivo não existir, o SourceLevel deduzirá à partir das linguagens de programação presentes no repositório.
As issues encontradas pelos linters são distribuídas dentre as categorias: Bug Risk, Clarity, Complexity, Duplication, Security e Style. Também é possível configurar cada um deles através de arquivos específicos dentro de cada repositório, ou especificando a URL de um repositório de arquivos de configuração, facilitando a gestão e padronização para todos os repositórios da empresa.
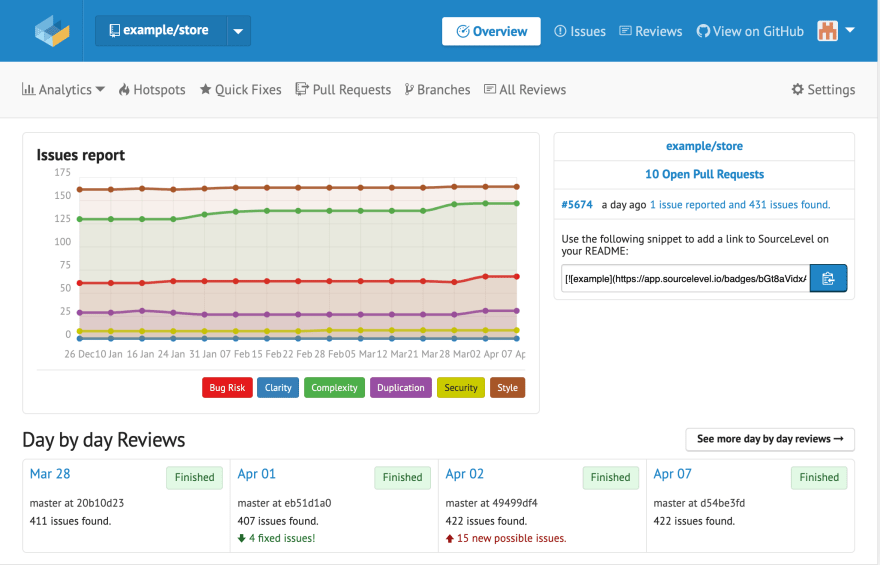
O gráfico de exemplo mostra o número absoluto de issues encontradas ao longo do tempo. Os dados apresentados são coletados pelos reviews diários na branch master.
Neste caso, a complexidade do código teve um aumento nos últimos dias, bem como o risco de bugs. O número de código duplicado havia sofrido uma queda no fim de Janeiro, mas nos primeiros dias de Abril subiu novamente.
Através da informação obtida no histórico do código deste repositório, os gerentes de engenharia e líderes técnicos podem tomar certas decisões, assim como o time pode estabelecer critérios para priorização destas demandas.
Esta tela é uma ótima fonte de dados para reuniões de priorização, discussão sobre débitos técnicos e, ao mesmo tempo, uma fonte de dados para garantir a qualidade das entregas ao longo do tempo.
Análise da qualidade nos Pull Requests
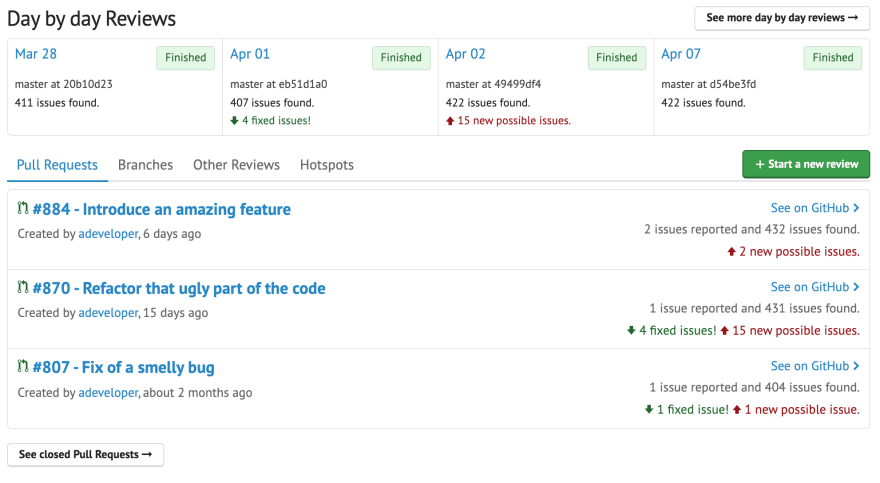
Para cada Pull Request aberto, são calculados os números de issues corrigidas e adicionadas. É possível, através da UI, visualizar issue por issue. De forma rápida, o próprio time consegue acompanhar o impacto de cada mudança sugerida, podendo, inclusive, bloquear seu andamento enquanto não forem corrigidos os erros.
A cada commit, os linters rodam novamente e recalculam os valores. Assim, os desenvolvedores e desenvolvedoras possuem sempre dados atualizados para tomada de decisão no dia-a-dia.
Automated Code Review nos Pull Requests
É muito importante que a revisão de código seja realizada por pares da pessoa que o submeteu à revisão. Este processo garante, dentre outras coisas, alinhamento, disseminação do conhecimento, e também diminui o número de bugs e falhas de segurança.
Ao revisar um Pull Request, as pessoas desenvolvedoras devem se atentar para inúmeros aspectos, sendo os mais importantes o quão correto o código está em relação aos requisitos técnicos e de negócio, se o código está correto em relação à arquitetura do código e do sistema, bem como se há bugs ou falhas de segurança.
O problema é que muitas equipes, ao invés de focar nas discussões de alto nível, acabam despendendo energia e tempo avaliando aspectos como qualidade, clareza, compatibilidade ao estilo pré-estabelecido e boas práticas da programação.
Muitos destes últimos aspectos citados possuem linters que os identificam e apontam aos desenvolvedores durante o processo de desenvolvimento, se configurados corretamente em suas IDEs.
Independente disso, é importante que exista uma ferramenta que automatize o Code Review o máximo possível. Isso permitirá o time a focar nas discussões que realmente importam.
O fato do SourceLevel inserir as issues encontradas pelos linters diretamente na respectiva linha do arquivo de um Pull Request, não só dá visibilidade ao autor ou autora de onde está o problema, facilitando, portanto, correção, como também torna o erro um convite à discussão.
A automação da etapa de code review tem sido um dos principais motivos do porquê nossos clientes amarem o SourceLevel.
Débito Técnicos
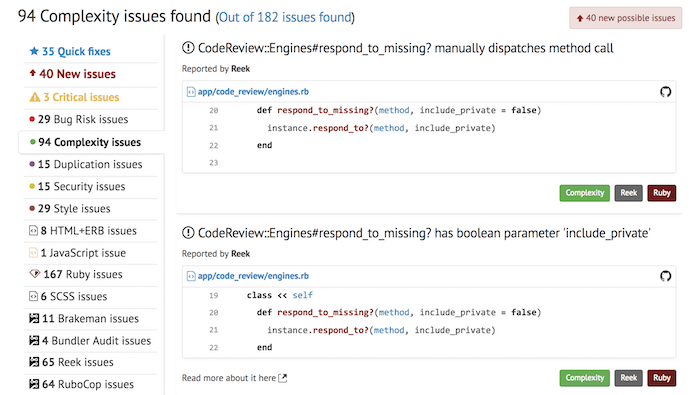
O SourceLevel organiza todas as issues em uma única página, podendo filtrá-las por Engine, categoria ou facilidade de correção. Essa página é importante para que os times tenham visibilidade e facilidade em atacar os problemas mais críticos de forma estratégica.
Zerar o número de débitos técnicos é tarefa difícil; mas a falta de controle pode gerar inúmeros problemas de manutenabilidade no futuro, aumentando o tempo de desenvolvimento de features pequenas e o risco de bugs.
Analytics para times de engenharia
Durante as reuniões com o board de um Startup ou com a alta gestão de uma empresa, todos os executivos costumam trazer dados para demonstrar o desempenho dos seus times. Marketing e Vendas, inclusive, monitoram diariamente estes números que envolvem, geralmente, número de Leads, taxa de conversão, número de vendas, receita bruta, etc.
O que os CTOs e líderes de engenharia levam? Muitas vezes esses profissionais montam planilhas e estimativas em cima de valores extraídos de outras ferramentas, como Jira e Clubhouse. Mas não seriam poucos dados para se justificar decisões concretas?
Por isso, o SourceLevel, que foca principalmente em métricas de engenharia, fornece algumas métricas relacionadas aos Pull Requests: Time to Review (Pull Request Lead Time), Throughput e Histograma do Lead Time.
Estas métricas, em breve, devem ganhar companhia de muitas outras, como Frequência de deploy, Time To First Approve, Time From Commit To Deploy e Time to First Review.
Se você tem interesse em utilizar estas métricas na sua empresa, entre em contato conosco! Entraremos em contato assim que forem lançadas!
Introdução às métricas
Abaixo está um breve glossário para entender as métricas do SourceLevel:
- Lead Time. É o tempo entre o começo ao fim de um dado fluxo. No caso dos Pull Requests, o Lead Time começa a ser contado no momento da sua abertura e termina com seu fechamento ou merge. Além de Pull Request Lead Time, esta métrica recebe outros nomes como Time To Review ou Code Review Lead Time.
- Throughput: Esta métrica representa a soma da quantidade de itens produzidos em determinado período. O período pode ser diário, semanal, mensal, ou qualquer outro estabelecido por quem consuma esta métrica. No caso do Code Review, o Pull Request Throughput representa o número de pull requests "mergeados". Os Pull Requests fechados não são contabilizados como trabalho concluído do ponto de vista de produção, pois não agregaram valor diretamente ao código. Isso não quer dizer que não possam ser utilizados como fonte de outros insights importantes.
- WIP: Em inglês, Work In Progress. **Representa todos os itens de trabalho que já foram iniciados, mas ainda não foram concluídos. No caso do Code Review, representam todos os Pull Requests ainda abertos.
- Cadência: a cadência de um processo é, à grosso modo, a quantidade de itens que saem de um processo ao término de determinado período. Sua definição se dará por uso de cálculos estatísticos em cima do Throughput*.* Em geral, é utilizada a média simples, o que significa dizer que a cadência pode ser a soma do throughput das últimas 4 semanas, por exemplo, dividido por 4.
- p50, p75 e p95: São os intervalos de confiança da informação. A média costuma esconder muita informação valiosa, por isso usamos a mediana (p50) e os intervalos de 75% e 95% de confiança para os cálculos Lead Time e Throughput.
Previsibilidade e Cadência
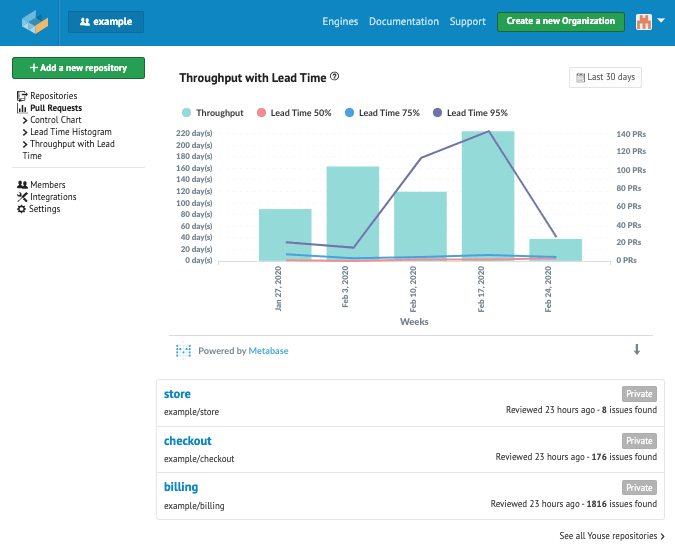
Todo gestor deseja previsibilidade. Esse atributo é fundamental para que se estabeleçam prazos e custos mais assertivos. Atingir uma segurança na previsão das entregas têm sido um dos principais objetivos dos gestores das áreas de tecnologia. Uma das melhores formas de se obtê-la é tendo uma cadência constante, ou seja, trabalhar para que o throughput e o lead time tenham a menor amplitude possível.
No imagem acima, por exemplo, através das barras, pode-se perceber que foram incorporados ao master em torno de 20 Pull Requests; na semana anterior, 140. Essa discrepância torna a previsibilidade muito difícil. Na semana seguinte, serão entregues 20, 60 ou 140? Qual a cadência do time?
Usando ainda o exemplo, percebemos que os três percentís de Lead Time mantiveram-se sem variações consideráveis nas primeiras 2 semanas mostradas no gráfico (semanas do dia 27/Jan e 03/Fev).
As linhas vermelha e azul, respectivamente mostrando p50 e p75, mostram uma certa estabilidade em todo o período analisado. Isso quer dizer que 50% dos Pull Requests levam no máximo 7 dias para serem incorporados à master. Se aumentarmos este número para 75% dos Pull Requests, então podemos dizer que levam no máximo 20 dias.
Nas semanas de 10 e 17 de Fevereiro, a linha azul dá um salto. Isso quer dizer que, aumentando a amostra para 95% dos Pull Requests concluídos nestas semanas, o maior Lead Time está entre 180 e 220 dias.
Como o comportamento dos Lead Times p50 e p75 foram similares aos da semana anterior, podemos deduzir que muito do WIP acumulado foi concluído. Muito provavelmente, o número alto do throughput da semana do dia 17 se deve ao fechamento de Pull Requests já revisados, mas que, por algum motivo, não haviam sido fechados.
Claro, não será possível entender o contexto e nem as motivações desses números sem uma investigação. Porém, munidos deles, CTOs, gerentes de engenharia e líderes de equipes podem focar suas investigações, validar suspeitas, mitigar os riscos antes que um problema maior aconteça e acompanhar o impacto de suas iniciativas.
Controle do WIP
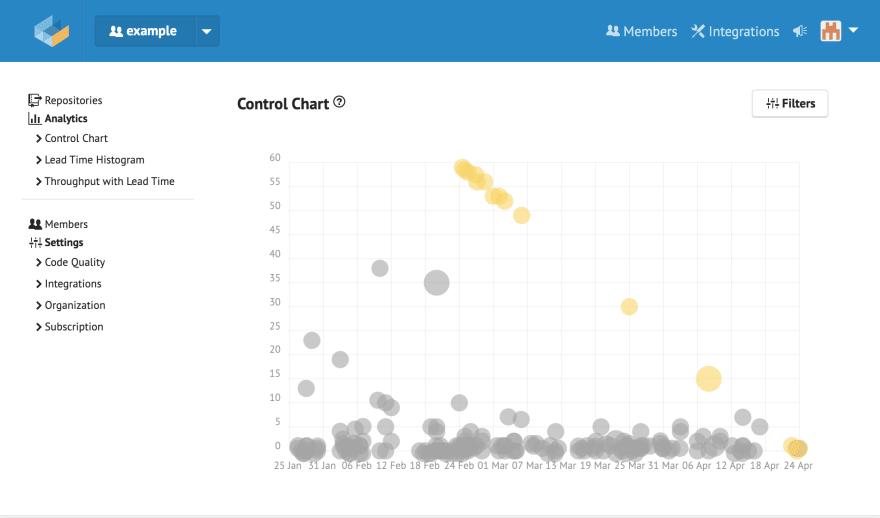
O gráfico de controle, ou Control Chart, oferece uma opção visual do estado atual do seu fluxo de trabalho. Os círuclos cinzas representam Pull Requests fechados; e as amarelas, Pull Requests abertos (WIP). O tamanho da circunferência é relativo ao tamanho da mudança: quanto mais linhas de código adicionadas ou removidas, maior o diâmetro.
No eixo X, temos o dia da abertura do Pull Request, e no eixo Y o Lead Time deste Pull Request. Nesse exemplo, o ponto amarelo na coluna do dia 25 de Março está indicando que está há 30 dias abertos; já o ponto maior, próximo à coluna do dia 06 de Abril, se mantém aberto há 15 dias e é relativamente maior em quantidade de linhas modificadas.
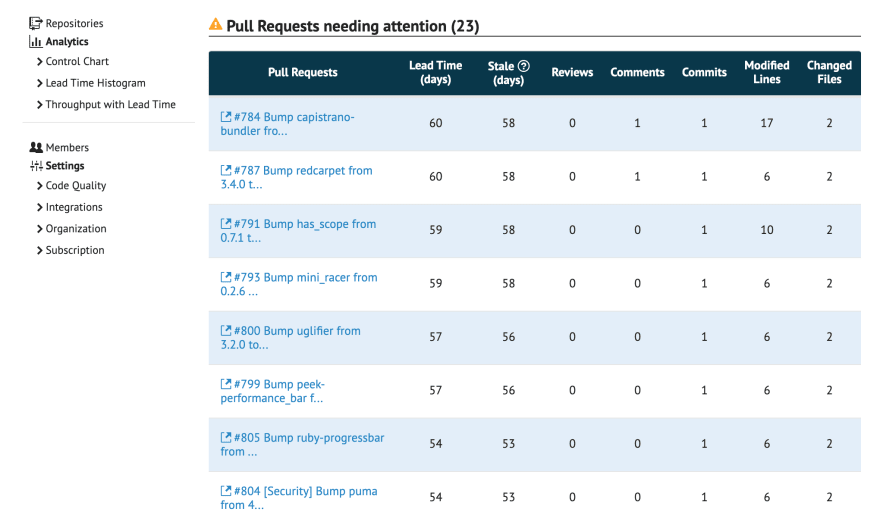
Ao passar o mouse por cima, é possível visualizar detalhes do Pull Request. Para corroborar, uma listagem de Pull Requests abertos ordenados do maior Lead Time ao menor é exibida logo abaixo do gráfico.
Como faço para começar a usar o SourceLevel?
Qualquer pessoa pode se cadastrar no SourceLevel e utilizar 14 dias de graça nos seus repositórios privados (permanentemente gratuito para repositórios open-source). Logo ao conectar com a conta do GitHub, a ferramenta puxará os dados históricos dos últimos 6 meses. Todos os gráficos ficarão disponíveis após a importação.
Se você estiver curioso para saber como anda o processo de desenvolvimento da sua empresa sem pagar nada, aqui vai o passo a passo:
- Cadastre-se na ferramenta
- Importe os repositórios do GitHub
- Aguarde nossa notificação de que seus dados estão prontos!
Precisa de ajuda? Sentiu falta de alguma coisa?
Estamos sempre abertos a feedbacks. Queremos ouvir sua opinião. Caso você sinta falta de algum gráfico ou informação, entre em contato conosco!
Se o SourceLevel te atende parcialmente, marque uma reunião conosco, quem sabe podemos incluir suas necessidades no nosso roadmap ou até mesmo, caso já tenhamos a mapeado, podemos aumentar a prioridade.
Para ajuda ou sugestões, não hesite em nos chamar pelo chat da nossa página!



Top comments (0)