Managing and generating value through data has been a challenge for most companies for decades. In recent years, the phenomenon of Big Data has brought a lot of optimism because of the promise of a revolution in business. However, what was seen was frustration due to limitations that data architectures have, and that prevent them from providing the expected value for companies. Given this scenario, a new architectural paradigm emerged, Data Mesh, which aims to remove bottlenecks and allow a more optimized delivery of value through data.
The challenge of creating value through data
Before getting into the details of this new architectural paradigm, let's understand the current context and identify the causes of failure in the data journey of many companies.
For that, let's review some of the key components that are used as big data repositories. The first of these is the Data Warehouse, which emerged in large corporations decades ago. In this context, the business had a slower and more predictable pace, the architecture was essentially composed of large and complex systems with little or no integration between them. The challenge was to get a unified view across the systems.
More recently, starting in the 2010s, a model that gained popularity was the Data lake, which emerged in a much more dynamic and less predictable business moment. This model was used not only by large corporations but also by new companies with disruptive value propositions. The architecture has evolved for a greater number of applications, which are simpler and more integrated, often stimulated by the use of new technologies such as cloud and microservices.
To better understand the concepts behind these two models, I suggest reading the following articles right here on the AvenueCode blog, Data Lake e Data Warehouse.
It's important to highlight that in these two architectural paradigms, the teams responsible for the data have characteristics of high specialization and centralization.
In light of this scenario, even though investments in the data area continue to grow, confidence in the return by adding real value to the business is decreasing. Based on a study by NewVantage Partners, it is possible to observe that only 24% of companies are actually able to adopt a data culture. However, it is important to point out that the problem does not lie in the technology itself, as the great advances of the last decade have dealt very well with the problems arising from the large volume and processing of data. Limitations in delivering value to the business result from processes and data models, due to intrinsic characteristics of such practices, such as:
- Monolithic and centralized architecture: based on the premise of the need to centralize data to obtain real value, architectures have always been complex and concentrated in a single place. Even in this context, it was relatively simple to start a Data Warehouse or Data Lake project, however, the difficulty lies in scaling, since these models have problems keeping up with the rapid changes arising from the business areas.

Source: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
- Highly centralized and specialized responsibilities: The responsibility for complex architectures is in the hands of a highly specialized engineering team that often works in isolation from the rest of the company, that is, far from where the data is generated and used. With that, this team can become a bottleneck when some changes are needed or in the addition of a new process to the data pipeline. In addition to the fact that the members of this team hardly have a business vision of all areas and, therefore, cannot respond to changes in business rules at the ideal speed.
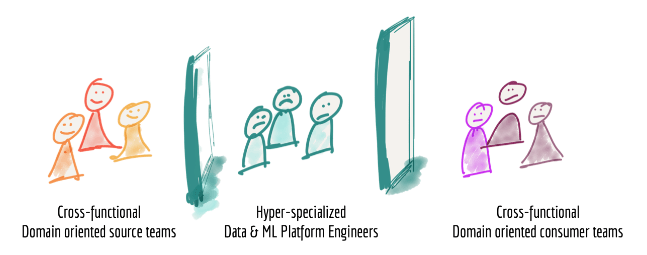
Source: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
The adoption of a centralized structure both in terms of staff and in terms of data platform brought major challenges for the real democratization of data such as the problem of data quality, due to the lack of business expertise by the engineering team. And there is also a deficiency in scalability issues, both due to engineering limitations as well as the complexity and interdependence of steps in the data pipeline.
Data mesh
Faced with the aforementioned problems, Zhamak Dehghani presented a new approach to data architectures, in these two articles on Martin Fowler's blog: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh, Data Mesh Principles and Logical Architecture. With the main objective being the democratization of data, Data Mesh challenges the models previously adopted and the assumption that large volumes of data must always be centralized to be able to use them or even to use a single team to manage these resources. To reach its full potential, the Data Mesh architecture follows 4 basic principles:
- Domain-oriented data architecture.
- Data as a product.
- Infrastructure that makes data accessible as self-service.
- Federated governance.
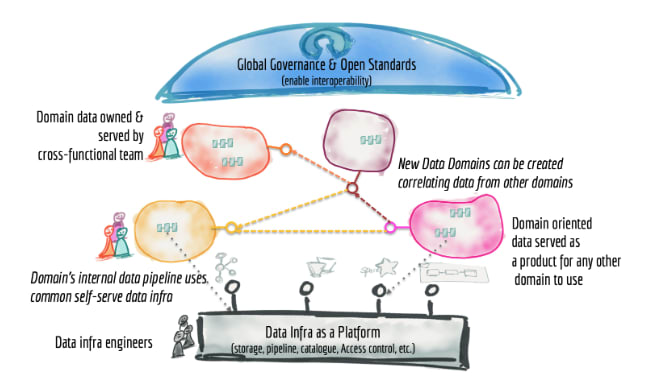
Source: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
Domain-oriented data architecture
The data architecture must be built and modeled in a way that is oriented to the different business domains, instead of being centralized in a single team. This practice can bring some benefits, such as using and managing data close to its respective sources, rather than having the effort of moving it. This is of great importance because moving the data requires a cost, for example, if it is necessary to add more processing jobs in a generic workflow and assuming that each job is a possible point of failure. Another benefit of this Data Mesh principle lies in the fact that data responsibility is balanced according to the domains involved and this makes the growth of new data sources and coupling them more agile to keep up with the rapid evolution of business. This makes it easier to scale at the same pace as business demands.
Data as a product
Making data architectures distributed is interesting from the point of view of allowing more optimized scalability, but it brings problems that did not exist in the centralized model, such as the lack of standardization in access and data quality. To solve these problems, Data Mesh proposes to think of data as a product, and for that, it is necessary to create new roles, such as the Data Product Owner and the Data Developer. These new roles are responsible for defining and developing products. Instead of looking at data as a service, the Data Product Owner must apply product thinking to create a better experience for customers or users, while the Data Developer works with a focus on developing the product itself. Within the responsibilities, the Data Product Owner of each domain must ensure that the data is accessible and well documented, as well as determine the form of storage and ensure the quality of the data. The purpose of this principle is to provide a good experience for users to perform analysis and bring real value to the business.
Infrastructure that makes data accessible as self-service
Another concern that arises in the decentralization scenario is the spreading of knowledge in technologies that were previously concentrated. There would be a risk of overloading domain teams and generating reworks regarding the data platform and its infrastructure, which needs to be built and constantly managed. Since the skills needed for this task are highly specialized and difficult to find, it would be impractical to require each domain to create its own infrastructure environment. Thus, one of the Data Mesh principles is to propose a self-service data platform, to allow autonomy of domain teams. This infrastructure is intended to be a high-level abstraction to remove complexities and the challenge of provisioning and managing the lifecycle of data products. It is important to note that this platform must be domain agnostic. The self-service infrastructure must include features to reduce the current cost and expertise required to build data products, including scalable data storage, data products schema, data pipeline construction and orchestration, data lineage, etc. Thus, the objective of this principle is to ensure that domain teams can create and consume data products autonomously, using the platform's abstractions.
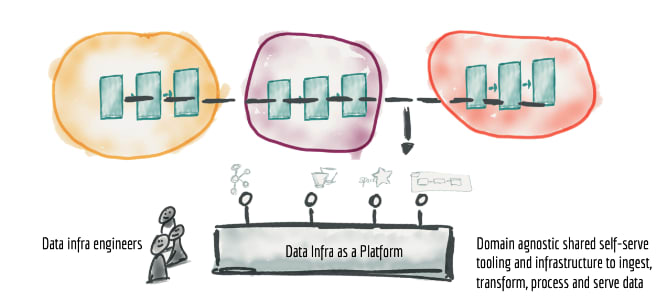
Source: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
Federated governance
One of the fundamental principles of Desh Mesh is to create federated governance, aiming to balance centralized and decentralized governance models to seek the positive points of both. Federated governance has some features such as domain decentralization, interoperability through global standardization, a dynamic topology, and most importantly, the automated execution of decisions by the platform. Traditionally, governance teams use a centralized model of rules and processes and accumulate full responsibility for ensuring global standards for data. In Data Mesh, the governance team changes its approach to sharing responsibility through federation, being responsible for defining, for example, what are the global (not local) rules for data quality and security, instead of being responsible for quality and security of all company data. That is, each Data Product Owner has domain-local autonomy and decision-making power while creating and adhering to a set of global rules, to ensure a healthy and interoperable ecosystem. Taking the LGPD as an example, the global governance team remains legally responsible and can inspect domains to ensure global rules.
It is important to highlight that a domain's data only becomes a product after it has gone through the quality assurance process locally according to the expected data product quality metrics and global standardization rules. Data Product Owners in each domain are in the best position to decide how to measure data quality locally, knowing the details of the business operations that produce the data. Although such decision-making is localized and autonomous, it is necessary to ensure that the modeling is meeting the company's global quality standards, defined by the federated governance team.
Data Mesh Architecture and Adoption
In the image below, it is possible to see the summarized architecture and observe the four principles at a high level, starting with the data platform, passing through the domains responsible not only for applications and systems but also for data, all under the macro responsibility of federated governance, ensuring product interoperability.
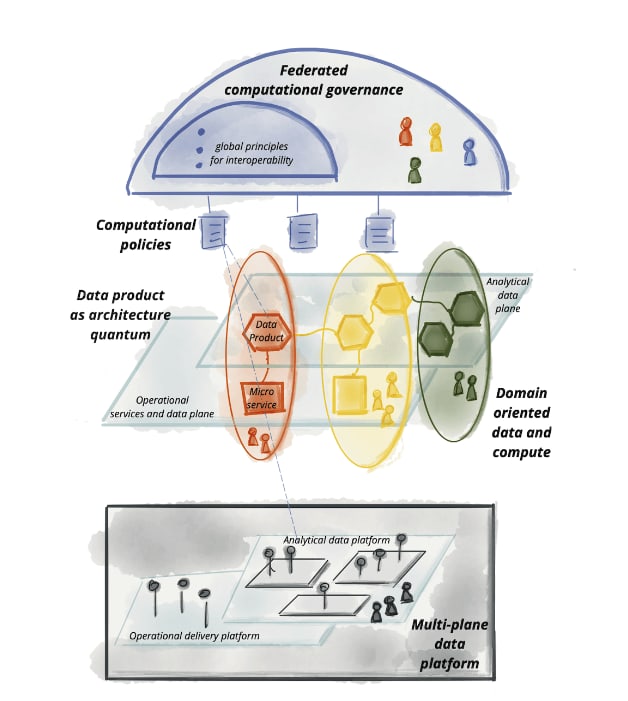
Source: Data Mesh Principles and Logical Architecture
In the current scenario and thanks to the advancement of data storage and processing technology in recent years, the technological factor is not a problem for the adoption of Data Mesh, since the tools used in Data Lake/Warehouse can be used in the new model. This article presents the possibility of creating a Data Mesh architecture based on GCP (Google Cloud Platform). In addition, there is a wide variety of cloud data storage options that allow domain data products to choose the right storage for the need.
It is important to point out that Data Mesh requires a change of culture within your company, from the business area to engineering, which can be a barrier in the implementation of this model. To know if your company would really benefit from Data Mesh, you need to answer some questions, such as:
- The number of data sources.
- The number of people on the data team.
- The possible number of business domains.
- If the data engineering team is currently a bottleneck often.
- What is the current level of importance that the company gives to the subject of data governance.
In general, the greater the number of data sources, set of consumers, business rules, and complexity of business domains, the use of Data Lake/Warehouse can end up becoming a bottleneck in the delivery of quality solutions. This is a scenario that would possibly benefit from the adoption of a Data Mesh based architecture. It is also valid to carry out specific projects in situations that could make good use of Data Mesh and change the culture and architecture little by little. Taking as an example a situation where if you are discarding data sources to be imported, which are valuable to business users, because it is complex to integrate these data sources in the current Data Lake/Warehouse structure, then this could be a good opportunity. to perform the migration to this new architecture.
Conclusion
With this, we conclude that Data Mesh offers an alternative to current data architecture models, allowing greater synergy between technical teams and business areas, which are the big users of data.

Top comments (1)