
Web scraping is a handy tool to have in a data scientist's skill set. It can be useful in a
variety of situations to gather data, such as when a website does not provide an API. We will be using this golang package github.com/anaskhan96/soup. It performs the same as beautifulsoup of python.
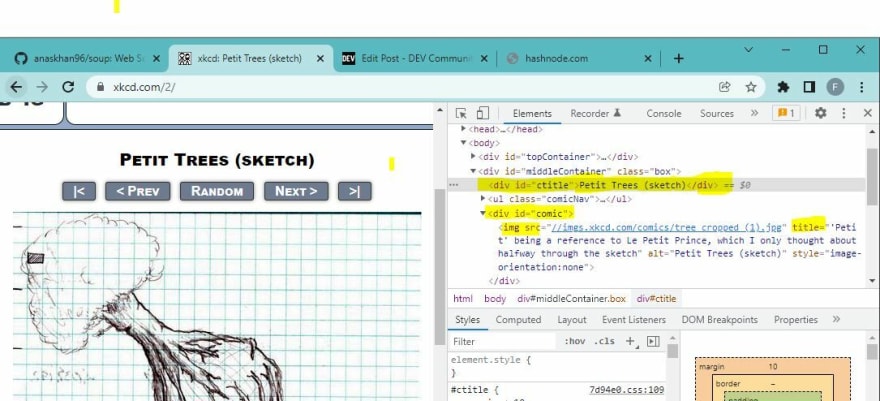
This is the webpage we are going to be scraping.
Below is a highlighted image of our desired values on the Browsers Dev tools.
Here is our code
package main
import (
"fmt"
"github.com/anaskhan96/soup"
)
func main(){
fmt.Println("Enter the xkcd comic number :") //collect user input
var num int //declare an integer called"num" to store the input
fmt.Scanf("%d", &num) //Collect the user input and assign it to num
url := fmt.Sprintf("https://xkcd.com/%d", num)//Append num to website url ''
resp, _ := soup.Get(url) //Call the soup fuction to extract url
doc := soup.HTMLParse(resp) //Parse extracted url to HTML encoding
title := doc.Find("div", "id", "ctitle").Text() // parse HTML Text
fmt.Println("Title of the comic :", title) // print HTML Text
comicImg := doc.Find("div", "id", "comic").Find("img") //Parse HTML IMAGE
fmt.Println("Source of the image :", comicImg.Attrs()["src"])
fmt.Println("Underlying text of the image :", comicImg.Attrs()["title"])
}
And Here is our output.

Here is the Github Repo
Credits to Daniel Whitenack on his book Machine Learning With Go

Top comments (0)