
The AWS environment has grown to a kind of universe providing more than 250 services over the last 20 years. Many applications which quite often easily use 5-10 or more of these services benefit from the rich feature set provided. Burdens which have existed for instance in local data centers like server management have been taken over by AWS to provide developers and builders more freedom to be more productive, creative and more cost effective at the end.
Billing and cost management at AWS are one of the hotter topics which have been discussed and complained about throughout the internet. AWS provides tools like the AWS Pricing Calculator which helps to create cost estimates for application infrastructure. Significant efforts have been spent over the last couple of years to improve the AWS Billing Console in order to provide better insights about daily and monthly spendings. However, it still can be hard to get a clear picture as every service and quite often also every AWS region has its own pricing structure.
At the same time, more and more cost saving options have been released. Depending on the characteristics and architecture of an application it can be astonishing easy to save a considerable amount of money with no or only limited invest in engineering time using some of the following tips.
Cleanup resources and data
Probably the most obvious step to reduce costs is to delete unused resources like dangling EC2 or RDS instances, old EBS snapshots or AWS Backup files etc. S3 buckets containing huge amounts of old or unused data might as well be a good starting point to reduce costs.
Beside not wasting money all these measures enhance the security at the same time: things which are no longer available cannot be hacked or leaked. AWS provides features like AWS Backup/S3 retention policies to support managing data lifecycle automatically so that not everything must be done manually.
AWS Saving Plans
Savings plans which come in different flavours were released about 3 years ago. They offer discount opportunities of up to 72 percent compared to On-Demand pricing when choosing the "EC2 Instance Savings" plan. Especially the more flexible "Compute Savings Plans" which still offers up to 66 percent discount is quite attractive as it covers not only EC2, but Lambda and Fargate as well.
Workloads running 24/7 with a somehow predictable workload are mostly suited for this type of offering. Depending on the selected term length
(1 or 3 years) and payment option (No, Partial or All Upfront) a fixed discount is granted for a commitment of a certain amount of dollars spent for compute per hour. Architectural changes like switching EC2 instance types or moving workloads from EC2 to Lambda or Fargate are possible and covered by the Compute Savings Plans.
Purchasing savings plans requires a minimum of work with a considerable savings outcome especially as most workloads require some sort of compute which contribute significantly to the total costs.
Reserved Instances and Reserved Capacity
Unfortunately, AWS does not offer Savings Plans for all possible scenarios or AWS services but other powerful discount options like Amazon RDS Reserved Instances come to a rescue. Reserved Instances use comparable configuration options like Savings Plans and promise a similar discount rate for workloads which require continuously running database servers.
The flexibility of change is however limited and depends on the database used. Nevertheless, it is worth considering Reserved Instances as a cost optimization choice with again only a minimum amount of time invest necessary.
Amazon DynamoDB, the serverless NoSQL database, offers a feature called Reserved Capacity. It reserves a guaranteed amount of read and write throughput per second per table. Similar term and payment conditions as already mentioned for Savings Plans and Reserved Instances apply here as well. Predictable traffic patterns benefit from cost reduction compared to the On-Demand or Provisioned throughput modes.
Automatic Shutdown and Restart of EC2 and RDS Instances
Many EC2 and RDS instances are only used during specific times during a day and most often not at all during weekend. This applies mostly for development and test environments but might also be valid for production workloads. A considerable amount of money can be saved by turning off these idle instances when they are not needed.
An automatic approach which initiates and manages the shutdown and restart according to a schedule can take over this task so that nearly no manual intervention is needed. AWS provides a solution called "Instance Scheduler" which can be used to perform this work if no certain start or shutdown logic for an application has to be followed.
Specific workflows which require for instance to start the databases first, prior to launching any servers can be modelled by AWS Step Functions and executed using scheduled EventBridge rules. Step Functions is extremely powerful and supports a huge range of API operations so that nearly no custom code is necessary.
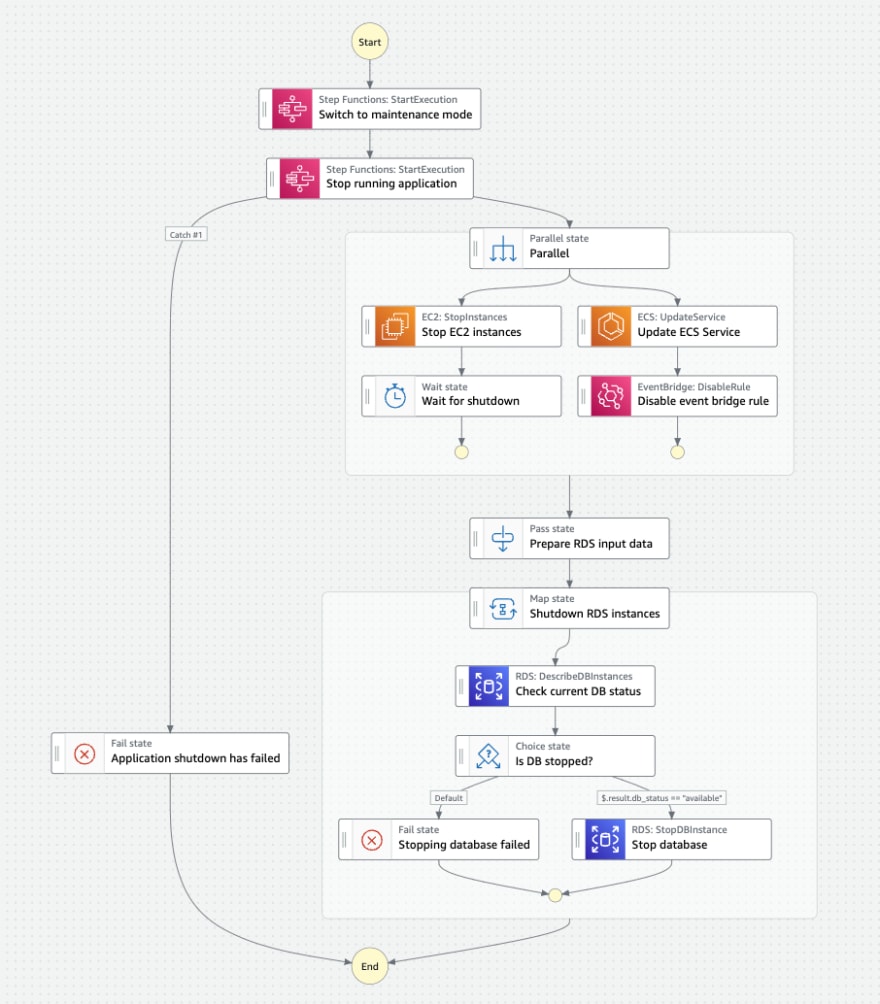
An example of a real-world workflow which stops an application consisting of several RDS and EC2 instances is shown in the image below. A strict sequence of shutdown steps must be followed to make sure that the application stops correctly. This workflow is triggered every evening when the environment is no longer needed.
The counter part is given in the next example. This workflow is used to launch the environment every morning before the first developer starts working.
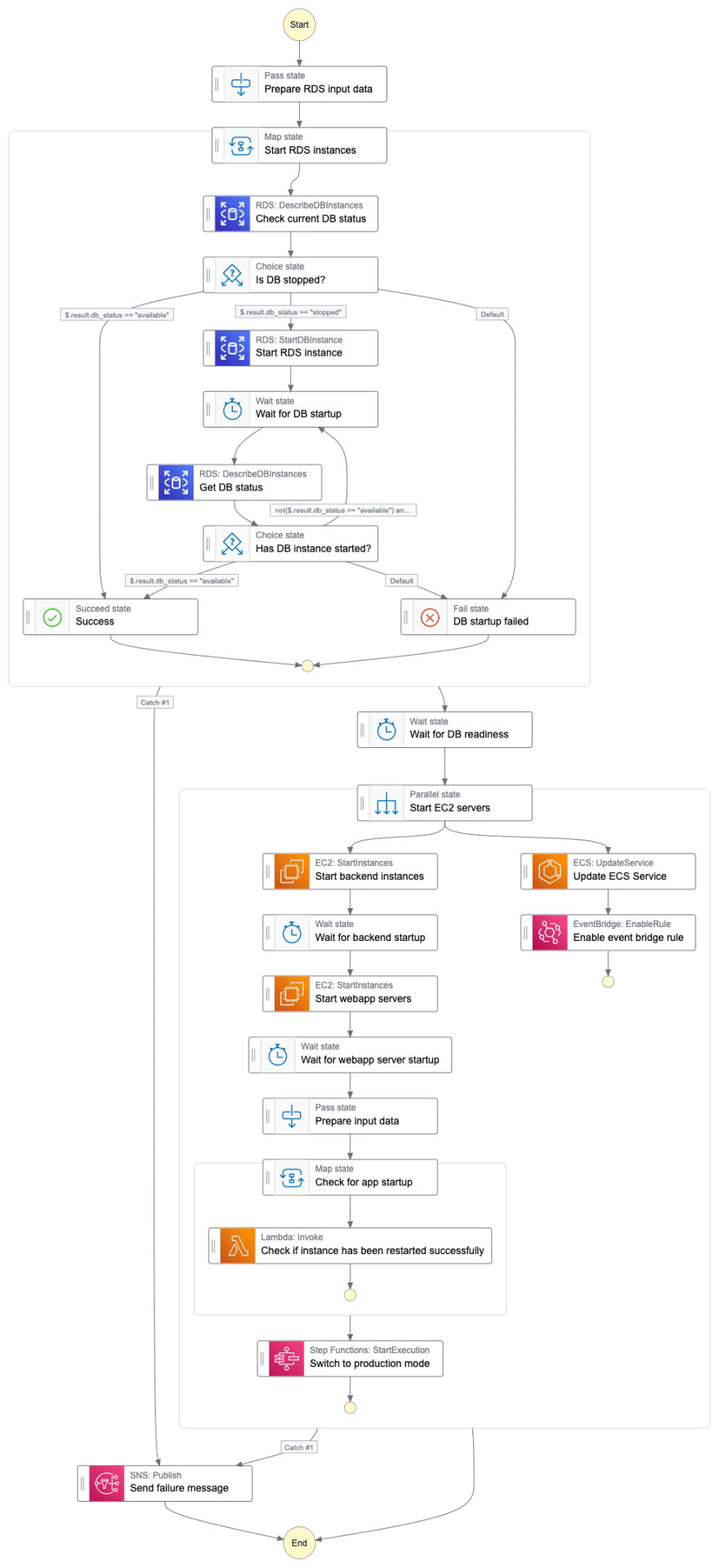
Shutting down all EC2 and RDS instances during night and over the weekend cut down the compute costs by about 50 percent in this project which is significant for a larger environment. The only caveat with this approach has been so far insufficient EC2 capacity when trying to restart the instances in the. It has happened very seldom, but took about half a day until AWS had enough resources available for a successful launch.

Up and downscale of instances in test environments
This option might not work in all cases as test (aka. UAT) environments often mirror the production workload by design to have nearly identical conditions when performing manual or automated tests. Especially load tests, but others as well should be executed based on production like systems as their results are not reliable otherwise. In addition, not every application runs on smaller EC2 instances as smooth as on larger ones respectively changing an instance size might require additional application configuration modifications.
Nevertheless, it sometimes is possible to downscale them (RDS databases might be an additional option) when load and other heavy tests are not performed on a regular basis (even though this might be recommended in theory).
Infrastructure as code frameworks like Terraform or CloudFormation make it relatively easy to define two configuration sets. They can be swapped prior to running a load test to upscale the environment. EC2 supports instance size modifications on the fly (no restart necessary) and even some RDS databases can be modified without system interruption. The whole up- or downscale process requires only a small amount of time (depending on the environment size and instance types) and can save a considerable amount of money.
Designing new applications with a serverless first mindset
Serverless has become a buzzword and marketing term during the last few years (everything seems to be serverless nowadays), but in its core it is still a quite promising technological approach. Not having to deal with a whole bunch of administrative and operative tasks like provisioning and operating virtual servers or databases paired with the "pay only for what you use" model is quite appealing. Other advantages of serverless architectures should not be discussed in this article but can be found easily using your favorite search engine.
Especially the "pay as you go" cost model counts towards direct cost optimization (excluding in this post topics like total cost of ownership and time to market which are important in practice as well). There is no need to shut down or restart anything when it is not needed. Serverless components do not contribute to your AWS bill when they are not used -- for instance at night in development or test environments. Even production workloads which often do not receive a constant traffic flow but more a spiky one benefit compared to an architecture based on containers or VMs.
Not every application or workload is suited for a serverless design model. To be fair it should be mentioned that a serverless approach can get much more expensive than a container based one in case of very heavy traffic patterns. However, this is probably relevant for just a very small portion of all existing implementations.
Quite often it is possible and beneficial to replace a VM or container by one or more Lambda function(s), a RDS database by DynamoDB or a custom REST/GraphQL API implementation by API Gateway or AppSync. The learning curve is steep and well-designed serverless architectures are not that easy to achieve at the beginning as a complete mind shift is required but believe me: this journey is worth the effort and makes a
ton of fun after having gained some insights into this technology.
Think about what should be logged and send to CloudWatch
Logging has been an important part of any application development and operation since the invention of software. Useful log outputs (hopefully in a structured form) can help to identify bugs or other deficiencies and provide a useful insight into a software system. AWS provides with CloudWatch a log ingesting, storage and analyzing platform.
Unfortunately, log processing is quite costly. It is not an exception that the portion of the AWS bill which is related to CloudWatch is up to 10 times higher than for instance the one of Lambda in serverless projects. The same is valid for container or VM based architectures even though the ratio might not be that high, but still not neglectable. A concept how to deal with log output is advisable and might make a considerable difference at the end of the month.
Some of the following ideas help to keep CloudWatch costs under control:
Change log retention time from "Never expire" to a reasonable value
Apply log sampling like described in this post and for instance provided by the AWS Lambda Powertools
Consider using a 3rd party monitoring system like Lumigo or Datadog instead of outputting a lot of log messages. These external systems are not for free and not always allowed to use (especially in an enterprise context) but provide a lot of additional features which can make a real difference.
In some cases, it might be possible to send logs directly to other systems (instead of ingesting them first into CloudWatch) or to store them in S3 and use Athena to get some insights.
Activate logging when needed and suitable but not always by default -- not every application requires for instance VPC flow logs or API Gateway access logs even though good reasons exist to do so in certain environments (due to security reasons or certain regulations snd company rules)
Logging is important and quite useful in most of the cases, but it makes sense to have an eye on the expenditures and to adjust the logging concept in case of sprawling costs.
Wrap up
All the cost optimization possibilities mentioned above can only scratch the surface of what is possible in the AWS universe. Things like S3 and DynamoDB storage tiers, EC2 spot instances and many others have not even been mentioned nor explained. Nevertheless, applying one or several of
the strategies shortly discussed in this article can help to save a ton of money without having to spend weeks of engineering time. Especially Savings Plans and Reserved Instances as well as shutting down idle instances are easy and quite effective measures to reduce their contribution to the AWS bill by 30% to 50% for existing workloads. Newer ones which are suited for the serverless design model really benefit from its cost and operation model and provide a ton of fun for developers.

Latest comments (0)