
Headless CMS can store raw data about products, stock, people, books or whatever else. But it can also hold information about the structure of pages on a website. Without sacrificing the benefits of a headless approach - we can also provide users with familiar and easy-to-use tools to control the appearance of their content and foster the reuse of existing material. In this article, we will look at an approach to how to structure headless CMS-based websites and design the content model to support these goals.
Information Architecture
What comes first in every headless CMS-based project is the information architecture. This means - your data model. There are 2 common patterns for designing the model:
Model built around raw data, e.g. products and stock
Model that also represents concepts like pages and their content.
While the first approach is absolutely correct, the second can easily become an anti-pattern of a headless CMS application. Let’s look a bit deeper into the pros & cons of both.
Raw data pattern
In the raw data pattern, we make great efforts to eliminate (or at least greatly reduce) any signs of the presentation layer in our data model. Some models we might see in a project would be:
product
- id: number
- price: number
- name: text
- description: text
- image: URL
invoice
- id: number
- date: date
- amount: number
- customer: object
This is done for a good purpose - the more sauté our data, the easier it will be to repurpose for different channels. What you display in a web browser today might end up on your smartwatch tomorrow. Reusing that content on a different device becomes relatively easy once we get rid of HTML or other forms describing how the content should be displayed. That’s, in fact, one of the main selling points of headless CMSs. Drawbacks? The headless Content Management System in reality, becomes a very thin frontend to a database. Is it bad? Not necessarily. Does it help content editors work with the content? To some extent - yes. But in this case, 100% of the description of how this content is displayed on a website (for example) has to be defined in code. This, in turn, means that any change to what is displayed on the website requires a developer to change that code and redeploy the application. This isn’t what customers used to platforms like Wix, WordPress or Adobe Experience Manager want to see. They expect at least some level of control and the ability to perform changes on a website without constantly engaging development teams.
Visual model
Quite the opposite approach, one which tries to address the need to easily perform changes on the website, is to include a description of the visual representation of our content in the headless data model. What we might find in a project that follows this path is, for example:
page
- title: text
- URL: text
- keywords: text
- header: rich text
- mainContent: rich text
- footer: rich text.
Depending on the features provided by the headless CMS - content editors may have quite a bit of control over how the content is structured and rendered on a page. For example, Flotiq [link do flotiq.com] offers a block editor that allows authoring page sections using structured content blocks.
This approach, unfortunately, is very close to a headless CMS anti-pattern. Content stored in pages structured this way will likely be unusable in any channel except a website. Let’s look at an example page object represented in JSON:
{
"title": "About us",
"url": "/about-us",
"keywords": "company information",
"header": "<h1>ACME company information page</h1>",
"mainContent": "<h2>Company history</h2><img src=\"/media/team-photo.jpg\" alt=\"Our team in 2022 has grown to 20 people!\"/><p>Our company has been founded in 1999, just before Y2K.</p>",
"footer": "<span style=\"font-size:8pt\">Call us at +1 (123) 456-789</span>"
}
Now - this will be easily rendered in a web browser, but what about a watch? Or what if you would like to send the company history information to a mobile phone in a text message? You will have to strip all the HTML, possibly removing some important information (like the contents of the alt attribute in the example above). Actually, you won’t even be able to reuse the information about company history on another page of your website - you would have to copy the entire page and only then start making adjustments. You will end up with a similar situation when using visual website builders.
Headless visual pattern
A sweet spot can be found between the 2 models above. A way to keep both - the editors wanting some flexibility and influence on the presentation layer and orthodox headless purists - happy. Let’s consider a specific example of a website selling tea. The basic data type, in this case, would be:
product
- id: number
- name: text
- description: text
- kind: {green, black}
- price: number
- image: url
order
- id: number
- date: date
- customerAddress: text
- orderedProductId: number
- quantity: number
- totalPaid: number
- shipmentStatus: text
and providing this to content editors via a Headless CMS will allow them to easily add and update products and track orders. A very simple product detail page might look similar to the following (the code examples below are incomplete but are inspired by Next.js components):
export default function Product({ product }) {
return (
<div style="background-color: green">
<h1>{product.name}</h1>
<img src="{product.image}"/>
<span><b>Price</b>{product.price}</span>
<button>Buy</button>
</div>
)
}
That’s really straightforward. But will a content editor happily clone a Git repo, open up an IDE and change the background color of this page? Nope. So can we do anything about it?
Defining the architecture
In some cases, this might be an iterative process, but it usually starts with a simple question - what do you expect to update on the site, and how frequently will you do it? Based on the answers to these questions, you will end up creating more or less complex content architecture. To address the situation in the example above - one might include in their content model (on top of the product and order content types) a productCard the model defined like this:
productCard
- id: number
- productId: number
- cardBackground: text
- and the component would instantly become:
export default function Product({ product, productCard }) {
return (
<div style="background-color: {productCard.cardBackground}">
<h1>{product.name}</h1>
<img src="{product.image}"/>
<span><b>Price</b>{product.price}</span>
<button>Buy</button>
</div>
)
}
This mix of content types originating from the raw data model and ones more related to the visual representation is really powerful if you think about it. Let’s consider that on our website, we also have a number of informational pages which describe the process of growing tea, packaging it and brewing it. Our UI designer created a modern minimalistic design based on 2 kinds of sections:

Content in these sections is text and a related image, but we already know there will be situations when the editors might want to visually emphasise some of these descriptions. How could we organize this in a headless CMS? Let’s look at an example:
order
- id: number
- name: text
- variant: {leftTextRightImage, leftImageRightText}
- heading: text
- content: text
- image: URL
- backgroundColor: text
page
- id: number
- URL: text
- title: text
- content: array of linked section objects. In the section content type we’ve identified several important patterns:
a) sections can have the image on either side but otherwise are the same,
b) background color should be changeable by the editors,
c) heading text should be split from the rest to simplify the presentation.
For the page content - we chose to compose the content of links to existing section objects (Flotiq supports relations/linking between objects of different content types). This way, sections can be used on different pages, and editors can even decide what goes on which page and in what order.
export default function Section({ props } ) {
return (
<div style="background-color:{props.backgroundColor}; display:flex">
<div style="order: {props.variant == "leftTextRighImage" ? 1 : 2}">
<h1>{props.heading}</h1>
<span>{props.content}</span>
</div>
<div style="order: {props.variant == "leftTextRighImage" ? 2 : 1}">
<img src="{props.image}"/>
</div>
</div>
)
}
export default function Page({ page }) {
return (
{page.sections.map((section) => (
<Section section={section}/>
))}
)
}
Data in Flotiq
The example above can be implemented in Flotiq very quickly. Here are our content type definitions first.
Section

Page

Objects
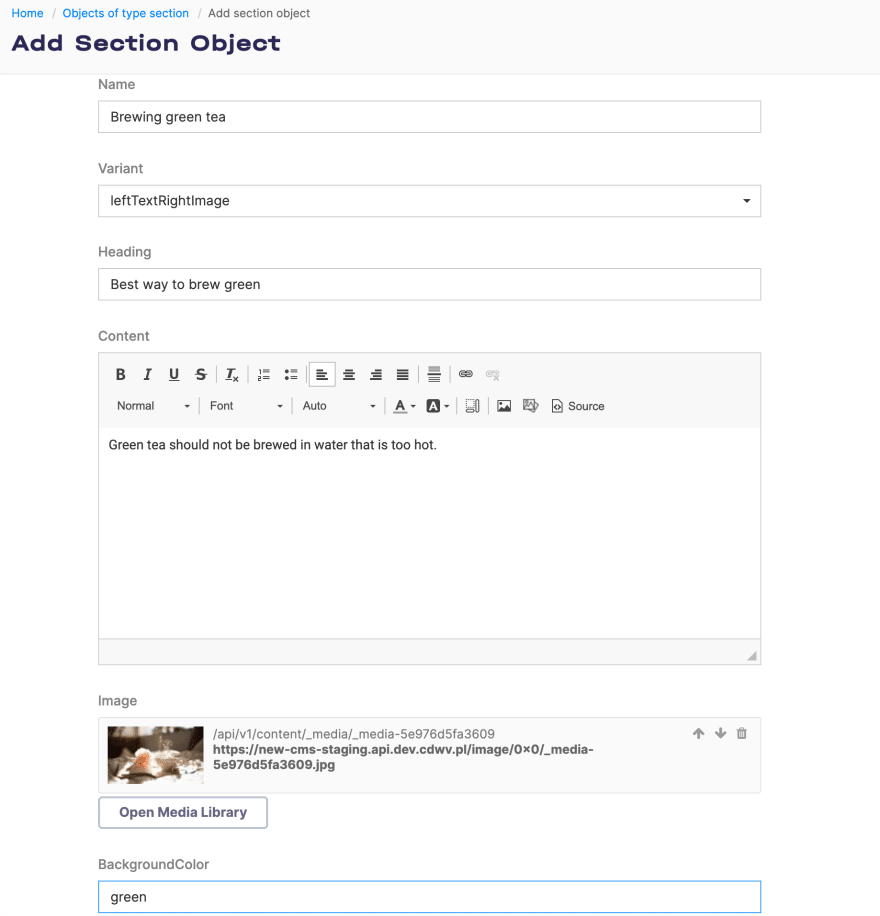
Once the CTDS are in place, we can start creating content. Here’s an example section:
and a page could be like this:

Summary
The main selling point of headless CMS systems is the separation of data and the description of its presentation. Unfortunately, this split can hurt the authoring flow and create bottlenecks for the development team. At the same time - focusing on the presentation side can result in a data model that makes content reuse almost impossible. Fortunately, following the headless visual pattern, we are able to logically structure our content, map it onto code (i.e. React components) and equip content editors with tools to influence the presentation layer without making code changes.

Top comments (0)