
osm-edge is built on top of Open Service Mesh (OSM) v1.1.0 codebase and is a lightweight service mesh for resource-sensitive cloud environments and edge computing scenarios. It uses osm as the control plane and Pipy as the data plane and features high performance, low resources, simplicity, ease of use, scalability, and compatibility (x86/arm64 support).
osm-edge is a simple, complete, and standalone service mesh and ships out-of-the-box with all the necessary components to deploy a complete service mesh. As a lightweight and SMI-compatible Service Mesh, osm-edge is designed to be intuitive and scalable.
For detailed introduction and documentation, refer to osm-edge documentation
In this experiment, benchmarks were conducted for osm-edge(pipy) (v1.1.0) and osm(envoy) (v1.1.0). The main focus is on service TPS, latency distribution when using two different meshes, and monitoring the resource overhead of the data plane.
osm-edge uses Pipy as the data plane; osm uses Envoy as the data plane.
Testing Environment
The benchmark was performed in a Kubernetes cluster running on Cloud. Cluster comprised of 2 worker nodes and one load generator node. Software and hardware configurations as below:
- Kubernetes: k3s v1.20.14+k3s2
- OS: Ubuntu 20.04
- Nodes: 16c32g * 2
- Load Generator: 8c16g
What features were tested?
- Both meshes had permissive traffic mode enabled
- Both meshes had mutual TLS enabled and were encrypting traffic and validating identity between all application pods.
- Both meshes were reporting metrics, including L7 metrics, though these metrics were not consumed in this experiment.
- Both meshes logged various messages at the INFO level by default. We did not configure logging.
What application was used for testing?
The test application uses the common SpringCloud microservices architecture. The application code is taken from flomesh-bookinfo-demo, which is a SpringCloud implementation of bookinfo application using SpringCloud. In the tests, not all services were used, but rather the API gateway and the Bookinfo Ratings service were selected.

External access to the service is provided through Ingress; the load generator uses the common Apache Jmeter 5.5.
For the tests, 2 paths were chosen: one is the direct access to the Bookinfo Ratings service via Ingress (hereafter ratings), and the other passes through the API Gateway (hereafter gateway-ratings) in the middle. The reason for choosing these two paths is to cover both single-sidecar and multiple-sidecar scenarios.
Procedure
We start the test with a non-mesh (i.e., no sidecar injection, hereafter referred to as non-mesh), and then test with osm-edge(pipy) and osm(envoy) mesh, respectively.
To simulate the resource-constrained scenario of the edge, the CPU used by the sidecar is limited when using the mesh, and the 1 core and 2 core scenarios are tested respectively.
Thus, there are 5 rounds of testing, with 2 different tests in each round.
Performance
Jmeter uses 200 threads during the test and runs the test for 5 minutes. Each round of testing is preceded by a 2-minute warm-up.
For sake of verbosity, only the results of the gateway-ratings paths are shown below with different sidecar resource constraints.
Note: The sidecar in the table refers to the API Gateway sidecar.
| mesh | sidecar max CPU | TPS | 90th | 95th | 99th | sidecar CPU usage | sidecar memory usage |
|---|---|---|---|---|---|---|---|
| non-mesh | NA | 3283 | 87 | 89 | 97 | NA | NA |
| osm-edge(pipy) | 2 | 3395 | 77 | 79 | 84 | 130% | 52 |
| osm(envoy) | 2 | 2189 | 102 | 104 | 109 | 200% | 108 |
| osm-edge(pipy) | 1 | 2839 | 76 | 77 | 79 | 100% | 34 |
| osm(envoy) | 1 | 1097 | 201 | 203 | 285 | 100% | 105 |
Sidecar with 2 CPU core limitations
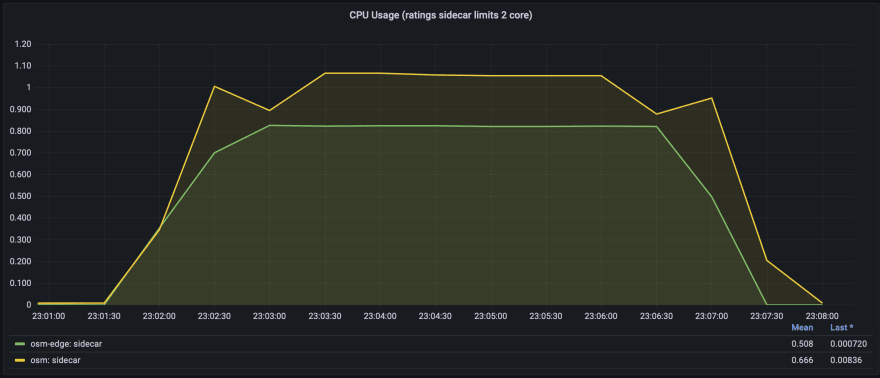
In the sidecar 2-core scenario, using the osm-edge(pipy) mesh gives a small TPS improvement over not using the mesh, and also improves latency. Improvement of TPS and latency is due the fact that Java NIO uses reactor pattern, while Pipy is built on C++ ASIO which uses the proactor pattern and the connection from Pipy to Java are long duplex connections. The sidecar for both API Gateway and Bookinfo Ratings is still not running out of 2 cores (only 65%), when the Bookinfo Ratings service itself is at its performance limit.
The TPS of the osm(envoy) mesh was down nearly 30%, and the API Gateway sidecar CPU was running full, which was the bottleneck.
In terms of memory, the memory usage of osm-edge(pipy) and osm(envoy) sidecar is 50 MiB and 105 MiB respectively, meaning osm-edge(pipy) was utilizing 52% less memory than osm(envoy).
TPS

Latency distribution

API gateway sidecar CPU usage

API gateway sidecar memory footprint

Bookinfo Ratings sidecar CPU usage
Bookinfo Ratings sidecar memory usage

Sidecar with 1 CPU core limitation
The difference is particularly noticeable in tests that limit the sidecar to 1 core CPU. At this point, the API Gateway sidecar becomes the performance bottleneck, with both the osm-edge and osm sidecar running out of CPU.
In terms of TPS, osm-edge(Pipy) drops by 12% and osm(Envoy)'s TPS drops by a staggering 65%.
TPS

Latency distribution

API gateway sidecar CPU usage

API gateway sidecar memory footprint

Bookinfo Ratings sidecar CPU usage

Bookinfo Ratings sidecar memory usage

Summary
The focus of this experiment was to benchmark the performance and resource consumption of both meshes in a resource-constrained environment. Experiment results revealed that osm-edge maintained high performance and made efficient use of allocated resources. This experiment proves that complete service mesh functionalities can be used and utilized for resource-constrained edge scenarios.
osm-edge is well-suited and ready for both cloud and resource-sensitive environments.

Top comments (0)