
This is the second part of the article about the voice assistant. You can find the first part here.
Database
Now let’s talk about saving questions and answers. The Trie data structure is a great fit for quickly identifying if a question exists in the database and then finding its answer. To store tree nodes and links between them, I used the graph database Dgraph. For this project, I created a free cloud repository on dgraph.io. A TrieNode looks like this:
type TrieNode {
id: ID!
text: String!
isEnd: Boolean!
isAnswer: Boolean!
isRoot: Boolean! @search
nodes: [TrieNode]
}
The search parameter is needed for the field to be indexed, which enables us to quickly find the root of the tree by running a query:
const query = `
query {
roots(func: eq(TrieNode.isRoot, true))
{
uid
}
}
`;
I used dgraph-io/dgraph-js-http library for sending the requests. To get all child elements for a node, I used the following query:
const query = `
query all($a: string) {
words(func: uid($a))
{
uid
TrieNode.nodes {
uid
TrieNode.text
TrieNode.isAnswer
TrieNode.isEnd
TrieNode.isRoot
}
}
}
`;
That is all it took to traverse the tree depth-first. If the question ends with a word for which there is a node with the isEnd characteristic equal to true, then the answer will be its child element with the value true for the isAnswer field. In addition to query results, dgraph-js-http returns additional information in the extensions field, for instance server_latency, which can be monitored while filling the database with a large number of nodes.
To configure service access to the database, we need a URL, which can be found at the top of the main repository page.
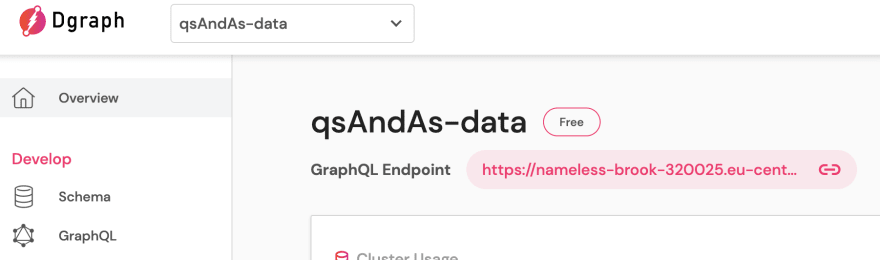
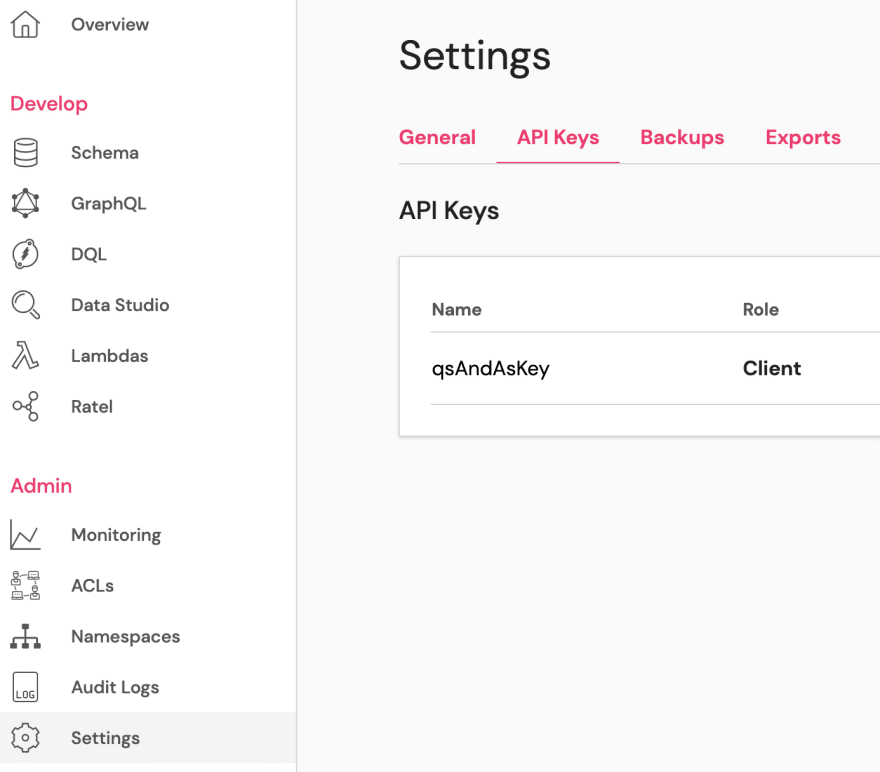
The second required parameter is an API key. It has to be created in the Settings section, in the API Keys tab:
Docker и Nginx
For ease of development, I added docker and nginx. The corresponding configuration files can be found on github in the qsAndAs repository. The three values in the environment section for the service that need to be filled in for everything to work are:
DGRAPH_HOST - URL for cloud.dgraph.io repository with the question and answer tree without /graphql at the end, should look something like this: https://somthing.something.eu-central-1.aws.cloud.dgraph.io;
DGRAPH_KEY - API key from cloud.dgraph.io repository;
GOOGLE_APPLICATION_CREDENTIALS - The path to json-file with the key from the Google Cloud project;
Profanity
I decided to use english for the obscenities/profanities.
First, I checked how Text-to-Speech is protected from the use of English profanity. I changed the phrase "I don't have an answer for you!" to "F$$k off! I don't have an answer for you!" and got the correct audio file without any censorship. Then I asked "Why did that son of a b$tch insult my family?" and got the full transcript again. After that I tried a few phrases such as "Tony, you motherf$$kers!" from the famous TV series The Sopranos and again everything worked out.
The non-conclusion conclusion
- The entire process of creating and testing my project, did not cost me a single penny;
- Speech-to-Text worked perfectly, except for situations where the audio was so poorly legible I had trouble understanding it myself;
- I tried to decipher the an hour-long dialogue between developers by uploading it to Google Cloud Storage. The result was not flawless, but the ability to add adaptive models to the decryption should improve the result;
- Google Cloud was highly convenient to work with, both through the web interface and through gcloud CLI, I do prefer the interface though;
- I was pleasantly surprised by the availability of a free cloud account for Dgraph;
- The Dgraph web interface turned out to be very convenient too, and the fact that I could play around with queries and mutations via Ratel greatly accelerated my learning. I must say that before this, I had no opportunity to try working with graph databases;
- In terms of labour intensity, it turned out that a working prototype could easily be made in just one weekend. And taking into account the presence of working examples for accessing Google Cloud for Go, Java, Python, and Node.js, the technologies for the prototype can be chosen from a very wide list;
- In the future, you can replace Trie with a text classifier in Vertex AI;

Top comments (0)