
At FINN, we grew from 0 to 20,000 car subscriptions, expanded to the US, all in just two years. Those statistics bring one word to mind: speed. We were fast, and how we did so is no secret either. If you want to know, read it here:

 Medium
Medium
All that speed came with certain costs. The tech relied heavily on no/low code tools like Airtable, Make (Integromat) and Retool, to name a few. We built a lot of microservices, automation workflows which enabled us to automate a lot of processes revolving around e-commerce and car subscriptions.
Early 2021, we had our 1000th car subscription and things weren’t slowing down. Around mid-2021 we were selling 70 car subscriptions daily: our highest record being 242 cars in a day! Imagine that! By end of 2021 we had crossed 10K subscriptions! Growth-wise it was looking great, but the tech was already at its peak and showing signs of struggle.
These two years of rapid prototyping and experimenting helped us learn what works well and what doesn’t, but the thing with prototypes is that they are not reliable, they break often and do not scale well.
Our situation back then looked something like:
- Database (Airtable) limits
- Synchronisation issues
- Overuse of no-code tools like Make for critical business purposes
- Extreme coupling at data level
- Lack of ownership of the data model
- Lack of access and change control process
- Difficult testing process
As with all prototypes, there comes a certain time at which we realise its not working for us anymore and we start making finer products, inspired by these prototypes and the learnings. The later half of 2021 indicated that FINN had outgrown its low-code prototypes and needed something better.
 |
|---|
| Image Credits - https://jasonmorrissc.github.io/post/2022-02-24_no-code/ |
Mitigating database failures
Airtable was our database of choice in the initial days. Reason: Ease of use, easy schema changes, quick rollbacks and snapshot recovery. We chose Airtable because everyone (and not just engineers) could work with it. Soon enough we had a database with more than 40 tables and the “cars” table having nearly 400 fields! (Highly inefficient, we know.) To add to that, we had dozens of automated workflow reading and changing that data and soon our database gave up. Airtable comes with a limit of 5 requests per second per base. We were constantly hitting that target and started having more than 100 timeouts per day.
We quickly set up a squad in action. This squad was called “No Time to Timeout”-squad, based on the recently released James Bond movie “No Time to Die”, with one goal: reduce daily Airtable timeouts to 0. The solution:
- Identify data that are loosely coupled and move them into separate bases, so that they can be managed independently
- Create read replicas for data that is used company-wide, e.g.: cars and subscription related data
- Identify read-heavy processes and update them to read from read replicas (this introduces a little staleness in data, but will do for now)
- Identify write heavy processes. For this we had to implement solutions case by case. For example, for car in-fleeting we implemented a diffing function which compares the recent changes sent by car manufacturers with the last changes and only updates the cars whose data has changed. For others, we batch the write operations
This reduced the timeouts to zero, but this was only our first step towards having a stable system.
Maintaining Trust in Our Data
We started having sync issues. Multiple sources of data, combined with lack of ownership of the data and no change control process, introduced a lot of data quality issues. Too many people changing the data directly, and partial updates to data required for certain processes made everything worse.
Ownership
This was the time to promote ownership. Teams were given ownership of certain data sets, e.g. the User Acquisition team owns the leads, Operations owns the cars and subscription management, Finance owns the monetary related data, and so on.
Access control
Controlling read and write access to data was tackled by cutting direct database access wherever possible and instead exposing data via micro-services written by the data-owning teams. These APIs were not generic CRUD APIs allowing you to do anything, but rather intent-driven APIs which only exposed a certain part of the dataset, depending on what you needed to do.
State machines
We started defining state machines for our critical entities like Car and Subscription. We had to define “What” data can be changed, “When”, and “Under what conditions”. The plan was to increase data consistency by making it impossible to change data in a way that would lead to conflicts. For example, marking a subscription as active would require to first check with the Car management and deliveries team if they have actually handed over the car. They would need to check with the Finance team if the deposit had been paid. Here’s one of our drafts for the Subscription state machine:
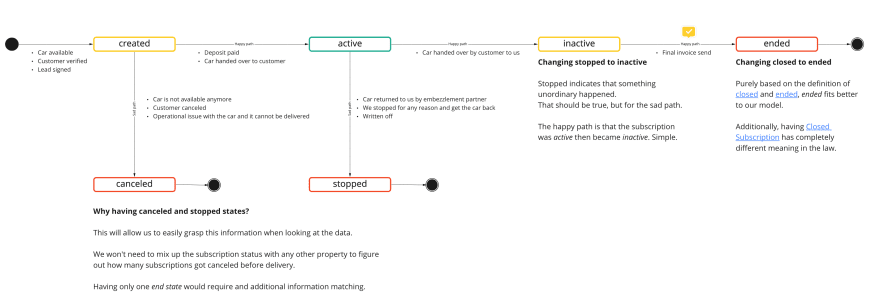
Going pro-code with project Green Dragon 🐉
The issues mentioned above made it crystal clear that we would not be able to scale. Moreover, soon we would have to expand into the US and things would only get more intense. We needed a system that was reliable as we simply could not afford to be in fire-fighting mode all the time. Where would be the time for new features, if all engineering effort was spent on maintaining the current system?
We decided to build new systems based on time-tested technologies and move away from the no-code/low-code solutions we had. We laid down some basic Engineering Principles to be followed. This was very challenging, because we had to keep the company and the business running till the new systems could take over.
Reduce risk to minimum
In my colleague Andrea’s words: Migrations are never easy and they hardly go as smoothly as we hoped. Our goal was to reduce the risk to minimum so that we could act quickly to respond to problems that might arise.
We came up with a strategy “Think 10x”. The idea was to start small, with just 10 cars targeted to be sold, and then scale 10 times in each phase. 10 cars → 100 cars → 1,000 … 100,000 cars. This ambitious project was called the “Green Dragon”.
The first phase, called “MVP 10”, was to focus on one part of the entire car subscription process and to go live with just 10 cars up for subscription from the new system on our website.
Enforce good engineering practices
Good systems are built on good principles. They guide us and help us make decisions when we have doubts. At FINN, we needed good principles for our new phase, the one where we double down on tech and make our critical systems better. Here the engineering principles we laid down at FINN:
- Keep it simple: we want to solve today’s problem in a simple way with an eye looking at tomorrow, rather than solving tomorrow’s problem today
- Embrace errors: We operate in a legacy environment where failures are common. We don’t want to fight errors, we want to embrace them and design with failure in mind
- Make it visible: Our services must talk to us, tell us what is happening and show us how well they are doing. We don’t want to find things out, we want to be told
- Internalise complexity: We cannot change how our partners work, but we can change how easy we make it for them to work with us
- Customer first: Our customers rely on us to give them the best possible experience, but they also trust us to manage their data and information
- Data is always accessible: we never want to block people from reading our data and we should always provide a way for them to do it without any work
- Clear is better than clever: We strive for readable code that is easy to understand and change. Our goal is not to write the least amount of code, but the clearest. Magic is not our friend here Once again, credits for laying down these principles goes to Andrea :)
Reducing disruption to minimum
FINN is very pro-automation, and we didn’t want to disrupt that. Everyone at FINN knows how to work with the automation platform Make (formerly Integromat) and leverages it to automate their day to work. Since data would not be so open anymore, we needed to provide a way for our colleagues to be able to use the new system from the comfort of Make. We made custom apps on Make which enabled our colleagues to use our new core APIs.

Our colleagues also need custom dashboards showing different data to enable their day-to-day work, such as overseeing and managing daily deliveries, damage management, incident handling and customer care. They need parts of subscription data, car data, financial data and much more. They also need to be able to perform some actions on this data. For this, we built them dashboards using Retool, so that they don’t need direct access to data as in the old system at FINN. This allowed us to have data validations and checks in place, and only allow data writes through our intent-driven APIs. This was such an enabler to help us keep our data consistent, while promoting easy access to data at the same time.
Where are we today?
Mitigating our issues to get the current system working and give us some breathing room to focus on developing the new system surely feels something like this famous meme:

Fixing A Bug In A Production GIF | Gfycat
Watch and share Fixing A Bug In A Production GIFs on Gfycat
Thankfully, with excellent teamwork across departments and multiple mitigation squads, we were able to stabilize our current systems. We took this Green Dragon project as an opportunity to show what real tech could do in all its glory. Every one was super energetic and enthusiastic about developing systems that would support FINN for the next phase of growth! We went live on June 28th 2022 with the MVP 10 phase smoothly and sold our first “Green Dragon” car subscription on June 30th and we aren’t slowing down. Huge shout out to Andrea Perizzato for leading this initiative ❤
What’s next?
We are going full flat out as we rebuild the tech that powers FINN. Watch this space for more insights about our tech and the next phases that we go live with!
Conclusion
No-code is cool and fast, and got us to where we are today, much faster than our competitors, but it won’t help us get where we want to. We have entered the next phase of growth where we take what we have learnt in the last two years and make it even better, more robust and scalable. We have set good practices in place to guide us along this way and we will continue to embrace struggle till we get to 100,000 car subscriptions.
If you liked this article, liking it and sharing it with others would help a lot!
If you would like to read more on topic such as this, software engineering, productivity, etc, consider following me! Much appreciated.
Connect with me on LinkedIn, I’m always happy to talk about tech, architecture and software design.
Lastly, FINN is hiring! If you want to be a part of this crazy growth and work alongside super awesome colleagues, consider having a look at our careers page or simply reaching out to me :) FINN is very diverse and inclusive, also consider having a look at our Women in Tech programme ❤

Top comments (0)