The Database
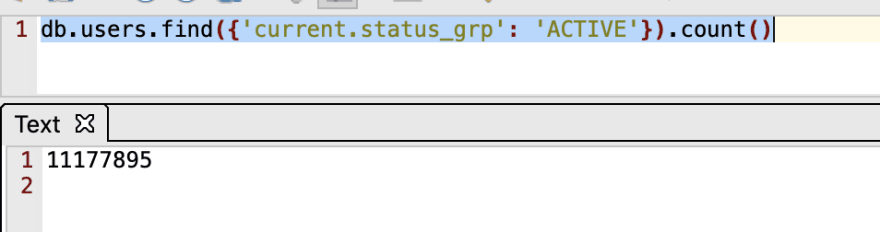
That is 11,177,895 active users. We run an eight cluster Mongo Database and we pay around $100k a year just in support. In this database, we only keep the most recent data and not transactional data so we can analyze better and faster. Faster because in a single document(JSON) we have all the information we need. It took almost a year to centralize and sanitize the data, in analytics, the data (and it's quality) is the most important part.
The Goal
So what do our stakeholders need? We are an internal department that works along with all other departments, so we adjust to the needs of each one. Our goal is to provide the best offer to the right client at the right time. To do that, we built an offer engine in Java and Google Web Toolkit (currently being migrated to Vue.js) so we can configure offers at every possible situation. This engine is a tree of rules (it also looks like a tree in the UI), each rule is configurable and each rule can evaluate in real-time and in Mongo's Map-Reduce (like Hadoop but in Mongo). That way we provide the offer for each of our stores (89) and for all digital channels.
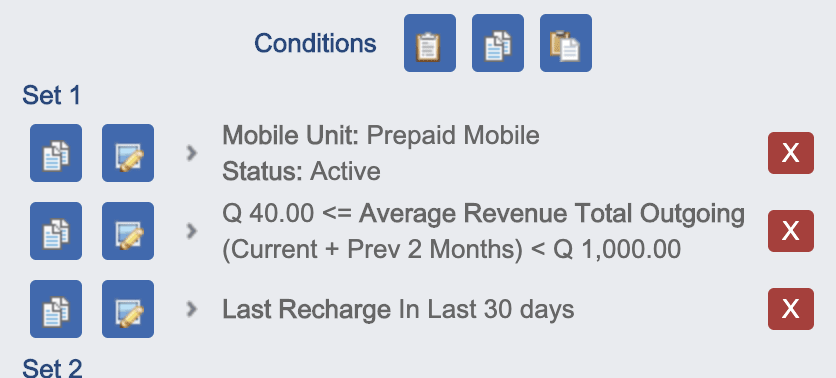
Where is the analytics?
So far, I haven't talked about analytics and actually this is the part that takes the least of our time and effort. Why? Because making models is easy and simple. We only use two kind of models. Logistic regressions and Decision Trees. These are the simplest, effective and easier to explain to other people. For a long time, we have been using R studio to create them and we export them in a JSON structure to be evaluated in Java in real-time. Exporting models to production is hard, so we are changing from R to python. Our engine is highly configurable so we can configure what model to apply for each node of the tree.

Results
Last year we generated 30 million in incremental revenue, and this goal is increasing every year.





Top comments (0)