
Almost all modern applications require storing and accessing data, but choosing the right database to power an application is a difficult task that involves reasoning about a complex set of tradeoffs. Developers typically need to think about:
- The geographic regions where the database will store data and whether the resulting real-world latency profile will allow them to create an application that is quick and responsive.
- The operational model for the database and the implied total cost of ownership and availability characteristics.
- The consistency model for the database and whether it meets requirements without pushing complex transaction support to the application.
- The developer experience for the database and whether it will empower fast and efficient innovation in the future.
- The scalability of the database and the ability to quickly dial capacity up or down as workloads change over time.
These dimensions are all important, but latency stands apart from the rest because it is the most difficult to reason about and it is often impossible to engineer around. Low latency is also growing in importance as business logic moves to the edge, making the difference between a local and remote API call more jarring and disruptive to users.
Defined simply, latency is the total amount of time that it will take for the database to receive a request, process the underlying transaction, and return the correct response. This definition implies that you can only determine the latency of a particular database if you view it through the lens of the application: where it will send requests from, the type of transactions it will need to run, etc. You cannot evaluate whether a database will meet your latency goals without considering it in the context of your application, making synthetic or best-case-scenario benchmarks unhelpful.
In this post, I’ll share a high-level framework that we use when helping developers think about latency. Then I’ll assess how Fauna does with respect to that framework.
Latency starts with the application
Databases exist to power applications, so database evaluation must begin by considering application architecture. For the last few decades most applications have been built using a three-tier architecture where the website or mobile app (called the presentation layer, but can be thought of as the software running on the client) communicates with an application server (called the application or business logic layer) that handles aggregating data from the databases (called the data layer) backing the application. But modern applications are increasingly moving towards a new client-serverless architecture where presentation logic runs on the client and business logic is encapsulated in the database which is accessed (along with other backend services) through an API. This architecture provides an opportunity to reduce latency by eliminating the need to go through a centralized application server and allowing databases to push data closer to the edge.
Regardless of architecture, latency for a request to the database begins with a network trip from the application to the database through all intermediate machinery, including the application server, if one exists. I’ll refer to this as external latency because it occurs before the request reaches the database.
Once the request reaches the database edge, the first point where the infrastructure owned or provided by the database vendor handles the request, the database needs to decode the wire protocol, authenticate the user, and parse the query expression. After this, a database will typically perform a number query handling steps before returning a response including processing compute operations associated with the underlying transaction, replicating data to other regions or replicas, and pulling required data from storage. I’ll call this time between receiving a request and returning a response where a database is handling the query internal latency. Note that not every database performs all of these steps. For example, an in-memory caching node that receives a write request may not replicate synchronously, or at all, to other regions, and may not even write to its local disk. However, a distributed transactional database will need to replicate durably and semi-synchronously to multiple remote regions before responding to the application, because it guarantees a higher level of availability and consistency.
Finally, the response that is returned by the database must travel through intermediate machinery back to the application, which also accrues towards external latency.
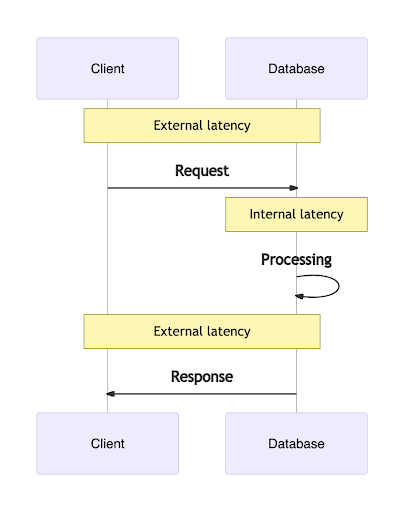
The total latency of the request, as experienced by the user, is equal to the sum of internal and external latency.
Where rubber meets road
Why does the distinction between internal and external database latency matter?
First, although most benchmarks measure internal latency only, database latency is more than internal latency in practice. If you’re building an application for a global customer base and backing it with a single-region application server and database, some customers may see 500+ milliseconds of latency for every request even if the database itself is infinitely fast.
Second, different architectures trade off other important database selection criteria like consistency, availability, scalability, and variance to achieve different latencies. For example, an eventually consistent database that asynchronously replicates data across regions may have lower internal latency numbers, but it leaves the application responsible for correctness edge cases. This can have the paradoxical effect of increasing latency if the application has to make extra requests to double check that the data is durable and correct, or if the application fails to do so, customers may receive an incorrect response.
In another example, a simple key/value store may offer very low average latency. But the fact that it can’t handle compute within the request may result in higher overall latency due to the many round trips required from the application to perform the same work that a database with a less constrained API could perform in a single transaction close to the data.
A framework for comparing latency
Instead of relying on simplistic benchmarks, I suggest applying the following framework to help you think about latency:
- Think about your application: where it will run, how it will be architected, and how data will flow from the application to the database.
- Come up with your own latency projections by modeling out both external and internal latency. When projecting external latency, look at where your users are located and the path that requests and responses to the database will take. Look at ping tables to help inform network latencies between various hops. For internal latency, avoid benchmarks that leverage overly synthetic traffic unless you’re confident that it is representative of your application traffic. Instead, try to look for actual reported latency metrics provided by vendors.
- Validate those metrics by running your own tests that mirror your application traffic.
- Think carefully about the tradeoffs that the database has made to achieve an internal latency profile and make sure that the consistency model and other database properties align to the requirements of your application.
To be more specific, you can calculate the expected latency by looking at your users and applying the formula
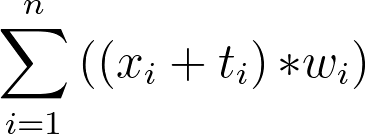
where your application traffic is divided across n distinct geographic regions, xi is the mean expected external latency in a given region, ti is the mean expected internal latency in a given region, and wi is the weight or percentage of active users who access your application in that region.
Applying the latency framework to Fauna
Let’s apply our latency framework to Fauna — a serverless, geographically distributed, strongly consistent, transactional database that is consumed as an API. Under the hood, Fauna uses Calvin to batch transactions and apply them across regions. This means that writes can take longer than a single node database because they must be applied to a majority of regions within a Region Group, but consistent reads are faster than a single node database because they can be served out of the nearest region.
To evaluate Fauna’s latency, let’s consider a hypothetical example where we’re building an application for customers across the United States, with 50% of users in Seattle and 50% in Miami; a pair of representative West and East Coast cities. Our application will be deployed to mobile devices using a client-serverless architecture where application logic runs on the client and clients make direct calls to the database. Let’s assume that we’re considering using a database in Fauna’s US Region Group and that latency is our primary evaluation criteria for a database.
Fauna’s US Region Group currently replicates data across three regions. This means that customers on both coasts will see average external latencies of <20 milliseconds before requests reach the database edge in Oregon or Virginia.
Fauna allows arbitrary computation over your data, so internal latencies are highly variable depending on the nature of the transaction underpinning a request. However, simple reads and writes are easy to reason about. For reads, Fauna simply returns requested values from the local region. For writes, Fauna synchronously assigns ordering to the transaction by writing it to the global transaction log, which requires a round trip to the next nearest region in the topology so that a majority of regions have recognized the write.
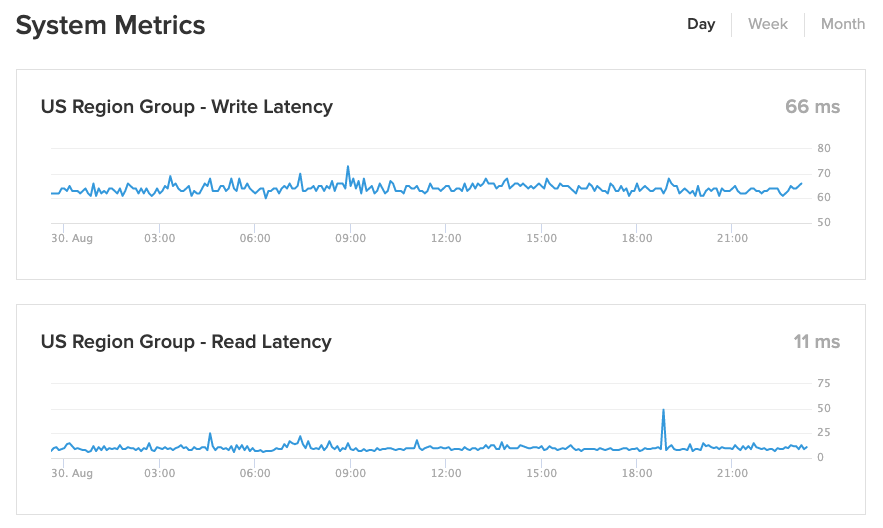
Fauna publishes average internal latencies that customers are seeing in practice on a status page. At the time of writing this article, reads are being served in 11 milliseconds and writes are being served in 66 milliseconds in the US Region Group.
Fauna’s external latency depends on the origin of the database call and the distance to the point of ingress to the database edge. In practice, customers that issue a request from Miami and ingress in Virginia should see about 24 milliseconds of external latency to reach the edge, while customers that issue a request from Seattle and ingress in Portland should see about 5 milliseconds of latency. For write requests, users that issue a request from Miami and ingress in Virginia should see about 13 milliseconds of additional internal latency as the transaction is sent to Ohio and applied in that region, while users in Seattle that issue a request and ingress in Portland should see about 62 milliseconds.
We can plug these values into the formula provided above to come up with the following average expected latencies:
- Simple reads from Fauna from Miami and Seattle should take ((24+ 11).5) + ((5+ 11).5)= 26ms on average.
- Simple writes to Fauna from Miami and Seattle should take ((24+ (13+ 11)).5) + ((5 + (62+ 11)).5)= 63ms on average.
Let’s consider how these metrics stack up against a hypothetical database that we’ll call FloraDB running in Virginia. FloraDB is a traditional, single-region database. Let’s assume it’s running on a single physical node and offers 5 milliseconds of average internal latency on both reads and writes, which is typical for an RDBMS.
Because FloraDB is single-region, the external latency of requests to the database is highly variable and depends on the location of the customer. Customers that issue a read or write from Miami will see about 24 milliseconds of network latency to reach Virginia, but customers that issue a read or write from Seattle will see about 70 milliseconds of network latency on every request.
Again, we can apply the formula above to generate projected average latencies:
- Simple reads from FloraDB from Miami and Seattle should take ((24+ 5).5) + ((70+ 5).5)= 52ms on average.
- Simple writes to FloraDB from Miami and Seattle should take (((24+ 5)+ 10).5) + ((70+ 5).5)= 52ms on average.
The following table captures all of the projected latencies above for an easier comparison:
| Read | Write | |||||
|---|---|---|---|---|---|---|
| Database | Miami | Seattle | Average | Miami | Seattle | Average |
| Fauna US | 35ms | 16ms | 26ms | 48ms | 78ms | 63ms |
| FloraDB Virginia | 29ms | 75ms | 52ms | 29ms | 75ms | 52ms |
Note that reads from Seattle to FloraDB take roughly 5x as long as reads to Fauna because the request has to travel across the country. A synthetic write benchmark driven from a node in Virginia would not give an accurate impression of the user experience of using either database; it would discount the negative impact of external latency when using FloraDB, as well as the positive impact of Fauna applying a transaction across regions in a Region Group by default, even though the benchmark would technically make FloraDB appear to be 10x faster for writes.
Summary
Latency is an important but complicated topic for developers to think through. In a distributed world, there is no single metric that accurately represents the latency of a specific database for all use cases.
I recommend starting by thinking about the application that you’re building, making predictions about the internal and external latencies that your application is likely to experience based on published metrics and the locations of your users, and then validating those projections with your own testing.
For most real world applications, using a database like Fauna that makes data available close to users on the edge is an attractive proposition, resulting in both lower average latencies and lower latency variances. The icing on the cake is the fact that Fauna delivers this low latency as a managed API along with high availability, strong consistency guarantees, a rich developer experience, and virtually unlimited scalability.

Top comments (0)